25、Prometheus监控系统
Prometheus简介
Kubernetes监控对象
数据提供方总结
Prometheus组成
监控架构
Prometheus部署
kube-state-metrics
node-exporter
AlterManager
Prometheus
k8s-prometheus-adapter
Grafana配置
配置Grafana的数据源
Kubernetes监控对象
数据提供方总结
Prometheus组成
监控架构
Prometheus部署
kube-state-metrics
node-exporter
AlterManager
Prometheus
k8s-prometheus-adapter
Grafana配置
配置Grafana的数据源
Prometheus简介
Prometheus其实本身是一个非常强大的监控系统,它的强大之处有几点,第一,高性能,因为其内部自带了一个时序存储系统,而不像zabbix默认使用MySQL或者PgSQL这样的关系型数据库,而时序存储系统,本身就是专用于基于时间流逝所采集的周期性的指标数据,所以在这个方面来说,它很高性能,第二,它的强大之处还表现在它内生的强大的ProSQL的查询接口,这个查询接口给用户提供了,非常灵活和强大的数据查询功能,允许用户获取Prometheus内部所采集到的监控数据,第三,Prometheus还可以整合我们的Grafana展示非常美观的监控界面,提供展示接口,第四,Prometheus能够实现强大的动态监控策略,能够通过服务发现的形式自动的添加或者移除监控目标,第五,Prometheus能够结合AlterManager实现非常强大的可定义报警机制;
Prometheus最初是作为一个通用的监控系统提供的,而且还是restfull风格的接口,后来当Kubernetes诞生之后,Prometheus好似天然就是一个专用于容器和容器编排平台的的监控工具,事实上也有人在非容器化下使用Prometheus来监控传统的IT信息架构组件,因为Prometheus对数据的采集的数据有这样几项,系统指标、程序指标、业务指标,而Prometheus在完成这些指标数据监控时,通常需要在被监控的主机通过一个所谓的Exporter来进行输出,也就意味着说,每一个监控的节点,他们能够自动的报告数据给Prometheus,Prometheus也能够自动的去拉取数据,只不过我们要使用Prometheus那么就需要借助于push gateway转接,也就是说Prometheus可以同时工作于两种监控模型,主动监控和被动监控;
但我们也可以借助于push gateway让每一个主动监控的系统,将数据推送给网关之后,再由Prometheus从网关那里获取数据;
对于Prometheus本身来讲有一个组件从外面去pull数据,在Prometheus内部还有时间TSDB序列数据库,而Prometheus本身提供的接口是一个http接口,它不像zabbix,有自己监控的套接字,有自己专用的协议,Prometheus完全就是使用最流行http协议来进行数据交互,另外Prometheus可以支持各种各样的服务发现机制来监控,还有它能借助于AlterManager把采样的接口分析以后出问题了,触发Alter规则,由AlterManager来根据用户自定义的报警机制来完成报警操作;
Kubernetes监控对象
那么在Kubernetes之上Prometheus能够用来监控我们需要监控的内容对象,一般有这么几项,第一节点,而对于节点来讲Kubernetes有一个专用的采集被监控节点数据的专用程序叫做node_exporter相当于zabbix agent,也就是说每一个监控的节点上都应该部署一个node_exporter,这个agent采集本地的所有数据,并接受Prometheus的拉取操作,如果我们监控的是Kubernetes集群中的节点的话,因为Kubernetes每一个节点默认都运行了一个cAdivisor,cAdivisor的数据被Metrics-server所采集,其实Prometheus也可以把cAdivisor作为采集数据的采集方,也就意味着在节点级来讲我们可以使用node_exporter还可以使用cAdivisor,而cAdivisor其对应的程序的Kubelet,它是Kubelet的一个组成部分;
在Kubernetes系统之上,它运行还有很多Pod、Service等组件,因为Kubernetes的所有资源都存储在etcd当中,而访问etcd只能通过ApiServer,所以监控Kubernetes之上各种各样的容器级指标数据的话,我们可以使用cAdivisor同时也可以通过ApiServer去收集各种各样的性能数据,所以ApiServer也是一个采样点;
因为etcd自身也是一个独立的系统,它自身也有它的的restfull风格的接口,因为Kubernetes本身也是restfull风格的,因此它如果Prometheus能够与etcd对接,就能够之间监控etcd,不过它必须要认证到etcd之上,才能够完成监控;
如果我们的Kubernetes之上跑了一个MySQL的Pod,我们想监控MySQL内部的select语句执行了多少次,满查询有哪些,那么对于这些功能,我们通过所谓的node_exporter是做不到的,通过cAdivisor也做不到,因为只能监控,容器自己占用了多少内存和CPU,它没法监控所谓应用程序程序级别的指标,所以向这种指标数据,我们就得程序自身向外输出,有些程序内建了允许Prometheus来抓取指标数据的接口,这个接口一般是/metrics,而这个/metrics就是来输出当前应用程序的各种指标数据的;
因为MySQL自身不是基于http协议工作的,所以MySQL是不支持的,那么我们可以这样,在MySQL这个Pod内部除了跑一个MySQL之外,再跑一个setcall,我们成为较边车容器,这个边车容器不断去获取MySQL的指标数据,把它转为http协议的接口向外输出,并且通过/metrics这么一个URL让Prometheus能够自动的去抓取它,只要有/metrics URL我们的Prometheus就能够动态的发现并自动将其纳入到监控中去;
还有一种方式,有些应用程序,本身是可以支持exporter的,直接内建了这个/metrics接口,有些复杂的应用程序Prometheus官方直接给它提供了一个exporter,以MySQL为例,Prometheus就专门为MySQL提供了一个叫做MySQL_Exporter的这个程序,我们直接将其单独跑为一个应用程序也行,而不跑位一个setcall(边车),同时为了使得这些程序能够被Prometheus动态抓取,一般来讲,如果以Pod方式运行的话,我们通常在Pod当中,要添加一个,annotation告诉Prometheus程序的Pod内部的哪一个端口的哪一个URL输出了指标数据;
如果提供了一个prometheus.io/scrape这么一个annotation并且值为true,就表示当前Pod是允许Prometheus抓取数据的,如果你创建的时候没有给定这么一个annotation,那么Prometheus就不会自动的将其纳入到监控目标中去;
如果prometheus.io/scrape等于true的话,那么我们还需要提供一个annotation,叫做prometheus.io/path,告诉Prometheus抓取时使用的URL是什么,如果不指定默认是/metrics;
如果prometheus.io/scrape等于true的话,那么我们还需要提供一个annotation,叫做prometheus.io/port,告诉Prometheus抓取时使用的套接字端口是什么,如果不指定默认是80;
数据提供方总结
节点级: node_exporter
Kubernetes节点级和容器级:cAdivisor(Kubelet)
ApiServer:如果通过cAdivisor查询不到,那么可以通过查询ApiServer的,因为ApiServer是允许列出对应资源类型的之下的所有资源对象的;
应用程序专用的:比如我们的MySQL_Exporter,也可以用户自定义开发;
kube-state-metrics:它主要用于派生出Kubernetes相关的多个指标数据的,这种指标数据主要跟计数器有关,比如kube-system名称空间下有多少个Pod,把每一个Pod作为一个计数,然后取一个和,这种数据我们就称之为派生指标,主要是跟计数器和元数据信息有关,包括制定类型的对象总数,资源配额容器状态等等,但是默认情况下Kubernetes之上没有state指标,所以我们需要一个专门的应用程序,kube-state-metrics是一个Pod,专门用来收集当前Kubernetes之上的各种各样的计数类的数据,收集完过来以后自己给它做聚合,并通过一个API向外输出;
因为Prometheus是一个有状态应用,因此部署完Prometheus以后不能对其随意进行伸缩,除非我们使用statefulset来部署Prometheus;
Prometheus组成
kube-state-metrics:用于在Kubernetes之上各个组件的计数指标数据;
node_exporter:需要监控节点级指标的话,还得在Kubernetes之上以DaemonSet方式部署node_exporter节点级数据采集器;
AlterManager:用于报警监控组件;
k8s-prometheus-adapter:要想自定义指标监控,我们还需要在Kubernetes之上额外部署一个组件,叫做k8s-prometheus-adapter,它主要将这些自定义指标数据转换为标准的Kubernetes自定义指标,主要是为我们的HPA等相关组件提供服务的吧;
Prometheus Server:通过exporter或者kube-state-metrics来采集数据,并自我存储到tsdb当中,内部采集的数据是否超出了合理区间,超出就触发报警;
监控架构
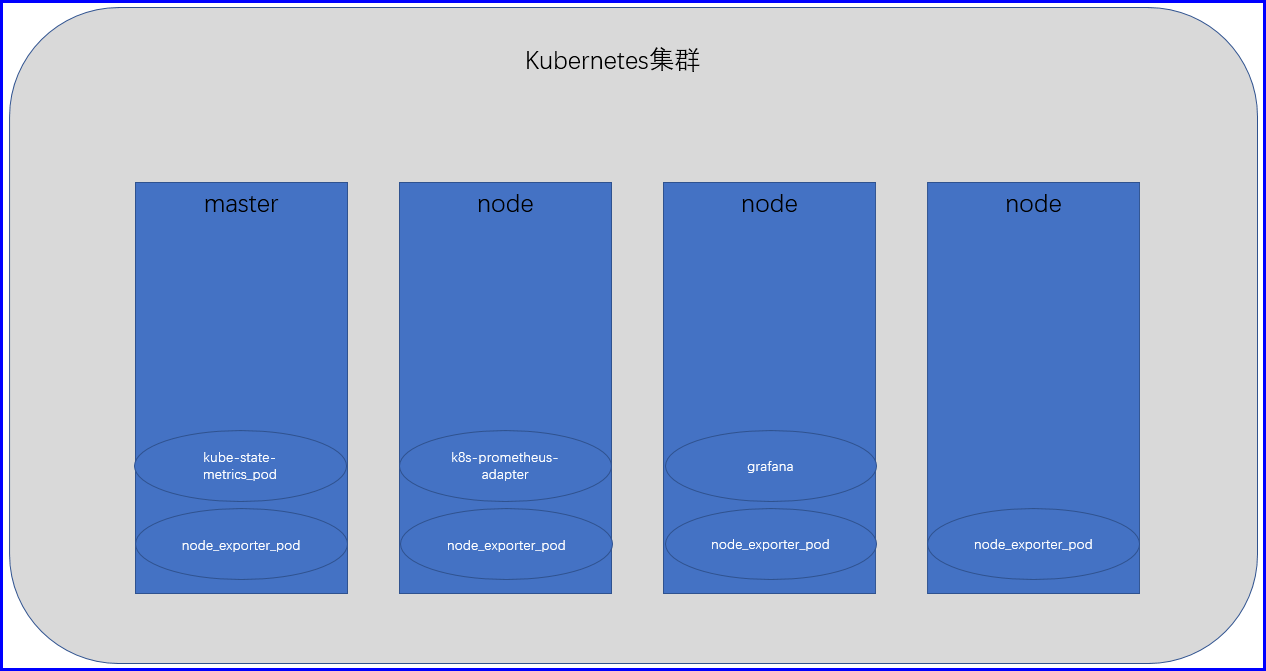
我们的Kubernetes集群有四个节点,第一,在Kubernetes集群的四个节点上使用DaemonSet分别部署一个node_exporter,让每一个节点都跑一个node_exporter,以便于把节点级别的数据,输出给我们的Prometheus Server,在集群之上以deployment的形式(一个副本即可),部署一个kube-state-metrics,这个kube-state-metrics通过查询ApiServser聚合etcd中的一些集群数据,合成计数器数据,从而能够让Prometheus去使用,再使用一个deployment去部署一个AlterManager(一个副本即可),以实现在必要时,向管理员进行报警;
再使用一个deployment或者statefulset去部署一个Prometheus Server,它也是一个Pod,这个Prometheus Server就通过这个一个kube-state-metrics以及这个每一个节点的node_exporter和cAdivisor来采集数据,然后Prometheus Server就通过PV把数据存储于这个持久系统之上;
此事我们的Prometheus就可以工作了,但是我们Prometheus提供我们的查询接口是ProQL,因为Kubernetes是没有ProQL的查询能力的,因此我们还需要在Kubernetes集群上再部署一个Pod,这个Pod叫做k8s-prometheus-adapter,它其实就是一个转换器,它能够向外通过http协议的api接口输出Prometheus的数据,向内使用ProQL去查询Prometheus的数据;
Prometheus部署
Prometheus监控Kubernetes需要安装多个组件,具体的请看Prometheus组成;
kube-state-metrics
用于向Prometheus提供Kubernetes集群之上的一些指标数据,比如Pod数量,Service数量,Deployment数量;
# 部署kube-state-metrics,用于统计Kubernetes集群之上各种各样的计数器类的数据
[root@node1 prometheus]# kubectl apply -f kube-state-metrics/
deployment.apps/kube-state-metrics created
configmap/kube-state-metrics-config created
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics-resizer created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
# 查看kube-state-metrics的service
[root@node1 ~]# kubectl get svc -n kube-system kube-state-metrics
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-state-metrics ClusterIP 10.107.118.157 <none> 8080/TCP,8081/TCP 17m
# 测试kube-state-metrics是否部署成功,一旦有metrics返回,那就说明我们的kube-state-metrics部署成功,它会以KV的形式展示
[root@node1 ~]# curl -I -m 10 -o /dev/null -s -w %{http_code} 10.107.118.157:8080/metrics
200node-exporter
用于监控节点级的指标,比如节点的CPU使用率、Memory使用率;
# 部署node-exporter,用于统计节点的相关指标数据,部署之前需要先将node-exporter-ds.yml添加master节点的污点,否则master节点将不会调度
[root@node1 prometheus]# kubectl apply -f node-exporter/
daemonset.apps/node-exporter created
service/node-exporter created
# 测试node_exporter是否部署成功,一旦有metrics返回,那就说明我们的node_exporter部署成功,它会以KV的形式展示
[root@node1 ~]# curl -I -m 10 -o /dev/null -s -w %{http_code} localhost:9100/metrics
200AlterManager
安装AlterManager,用于在Prometheus收集到的指标,达到管理员定义的阈值的时候,进行触发报警;
# 安装AlterManager,AlterManager需要用到持久存储,所以先创建pv
[root@node1 ~]# yum install -y nfs-utils
[root@node2 ~]# yum install -y nfs-utils
[root@node3 ~]# yum install -y nfs-utils
[root@node1 ~]# mkdir -p /data/volumes{1..3}
[root@node1 ~]# cat /etc/exports
/data/volumes1 172.16.0.0/16(rw,sync,no_root_squash)
/data/volumes2 172.16.0.0/16(rw,sync,no_root_squash)
[root@node1 ~]# exportfs -rav
exporting 172.16.0.0/16:/data/volumes1
exporting 172.16.0.0/16:/data/volumes2
[root@node1 ~]# systemctl start nfs
# 创建pv
[root@node1 ~]# cat altermanager-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nfs-v1
spec:
capacity:
storage: 5Gi
persistentVolumeReclaimPolicy: Delete # pvc删除策略
accessModes:
- ReadWriteOnce
- ReadOnlyMany
- ReadWriteMany
nfs:
path: /data/volumes1
server: 172.16.1.2
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nfs-v2
spec:
capacity:
storage: 5Gi
persistentVolumeReclaimPolicy: Delete # pvc删除策略
accessModes:
- ReadWriteOnce
- ReadOnlyMany
- ReadWriteMany
nfs:
path: /data/volumes2
server: 172.16.1.2
# AlterManager默认使用的storageClass,所以我们需要将其注释掉
[root@node1 alertmanager]# cat alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
spec:
# storageClassName: standard # 注释掉存储类
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
# 为了能让AlterManager在集群外部能访问,修改AlterManager的service类型为NodePort
[root@node1 prometheus]# cat alertmanager/alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
nodePort: 30080
selector:
k8s-app: alertmanager
type: "NodePort"
# 创建AlterManager
[root@node1 prometheus]# kubectl apply -f alertmanager/
configmap/alertmanager-config created
deployment.apps/alertmanager created
persistentvolumeclaim/alertmanager created
service/alertmanager created
[root@node1 ~]# curl -I -m 10 -o /dev/null -s -w %{http_code} 172.16.1.2:30080
200Prometheus
正式部署Prometheus-server监控端;
# 部署prometheus,修改prometheus的Service的service为NodePort,让其在集群外可以访问
[root@node1 prometheus]# cat prometheus-service.yaml
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: kube-system
labels:
kubernetes.io/name: "Prometheus"
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
nodePort: 30090
selector:
k8s-app: prometheus
type: "NodePort"
# 此处没有存储类,所以注释掉prometheus的存储类额
[root@node1 prometheus]# tail -6 prometheus-statefulset.yaml
# storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "3Gi"
# 部署prometheus
[root@node1 prometheus]# kubectl apply -f prometheus/
configmap/prometheus-config created
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus created
statefulset.apps/prometheus createdk8s-prometheus-adapter
prometheus内部的查询接口是基于一个ProQL来进行的,但是Kubernetes没有这个PorQL的查询能力,所以我们需要部署k8s-prometheus-adapter能够将内部自建的这个prometheus的ProQL的查询能力转为restfull类型的接口,从而对接到ApiServer的Aggregator上去,因此能够做自定义指标数据使用,从而我们的k8s-prometheus-adapter就是一个自定义的ApiServer,但k8s-prometheus-adapter内部没有数据,它需要连如ProQL来查询;
可以看到custom-metrics-apiserver-deployment.yaml,里面使用tls类型的证书做双向认证,并且需要使用secret来进行存储证书,因此我们还需要自己给这个k8s-prometheus-adapter做一个证书,而签署证书的机构,就是kubernetes.ca,就是ApiServer所信任的这个CA;
k8s-prometheus-adapter:https://github.com/DirectXMan12/k8s-prometheus-adapter
# 生成一个密钥
[root@node1 k8s-prometheus-adapter]# openssl genrsa -out serving.key 2048
# 生产一个证书签署请求
[root@node1 k8s-prometheus-adapter]# openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
# 使用kubernetes自己的CA签署证书
[root@node1 k8s-prometheus-adapter]# openssl x509 -req -in serving.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out serving.crt -days 36500
# 创建名称空间
[root@node1 k8s-prometheus-adapter]# kubectl create ns custom-metrics
# 基于创建出的证书做一个secret
[root@node1 ~]# kubectl create secret generic cm-adapter-serving-certs --from-file=/etc/kubernetes/k8s-prometheus-adapter/serving.key --from-file=/etc/kubernetes/k8s-prometheus-adapter/serving.crt -n custom-metrics
[root@node1 ~]# kubectl get secrets -n custom-metrics cm-adapter-serving-certs -o yaml
# 修改custom-metrics-apiserver-deployment.yaml的配置
[root@node1 manifests]# grep 'prometheus-url' custom-metrics-apiserver-deployment.yaml
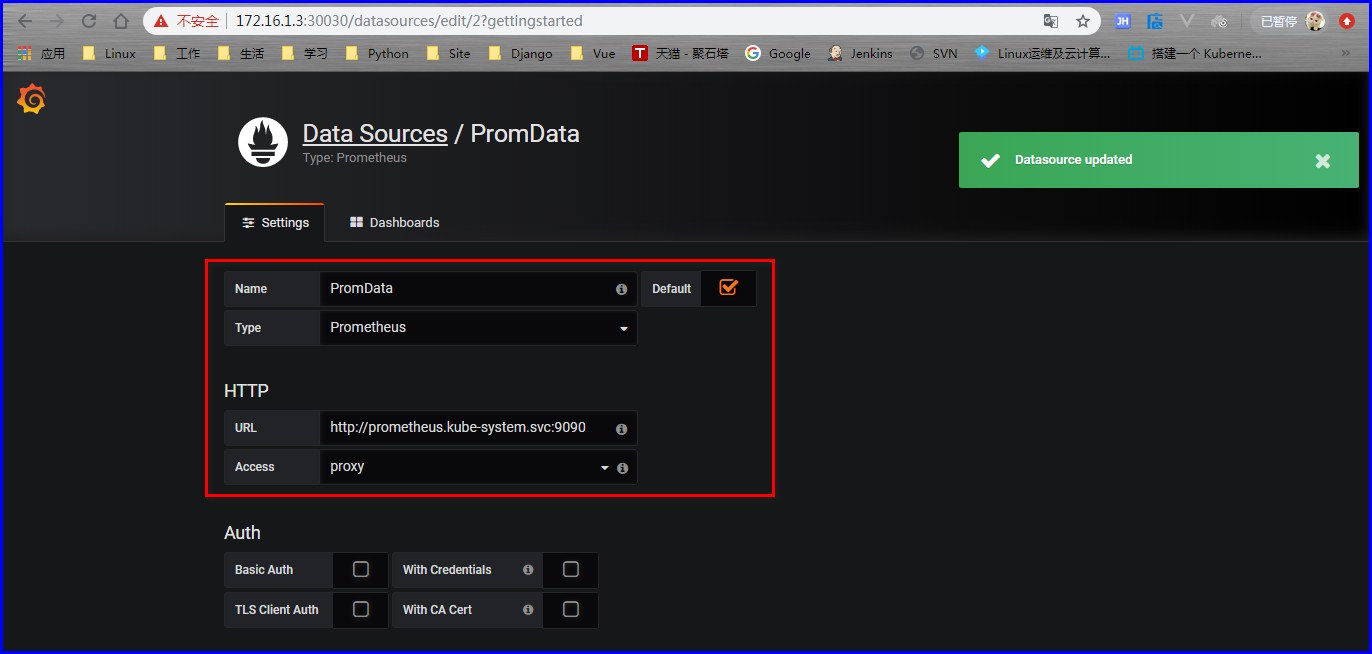
- --prometheus-url=http://prometheus.kube-system.svc:9090/ # 默认是在prom名称空间,这里需要修改,我们的prometheus在kube-system
# 部署k8s-prometheus-adapter
[root@node1 ~]# kubectl apply -f k8s-prometheus-adapter/manifests/
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created
deployment.apps/custom-metrics-apiserver created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-resource-reader created
serviceaccount/custom-metrics-apiserver created
service/custom-metrics-apiserver created
apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created
configmap/adapter-config created
clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created
clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics created
# 查看自定义Api群组是否成功
[root@node1 ~]# kubectl api-versions |grep custom.metrics
custom.metrics.k8s.io/v1beta1
# 查看各组件是否运行正常
[root@node1 ~]# kubectl get all -n custom-metrics
NAME READY STATUS RESTARTS AGE
pod/custom-metrics-apiserver-7666fc78cc-56mq8 1/1 Running 0 103s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/custom-metrics-apiserver ClusterIP 10.98.164.69 <none> 443/TCP 104s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/custom-metrics-apiserver 1/1 1 1 104s
NAME DESIRED CURRENT READY AGE
replicaset.apps/custom-metrics-apiserver-7666fc78cc 1 1 1 104s
# 测试自定义资源指标,借助于kubectl使用原始格式直接获取Api群组下面的所有resources
[root@node1 ~]# yum install -y jq # 安装jq对json格式的数据进行解析
[root@node1 ~]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .|less
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "jobs.batch/kube_endpoint_created",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
...
# 获取指定的资源字段
[root@node1 ~]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .resources[].name
"namespaces/kube_pod_container_status_waiting_reason"
"namespaces/kube_pod_start_time"
"jobs.batch/kubelet_container_log_filesystem_used_bytes"
"persistentvolumeclaims/kubelet_volume_stats_inodes"
"namespaces/kube_pod_container_status_terminated"
"pods/kube_pod_container_resource_requests_cpu_cores"
"pods/kube_pod_container_status_running"
# 安装grafana
[root@node1 ~]# kubectl apply -f grafana/grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana createdGrafana配置
Grafana模版地址:https://grafana.com/grafana/dashboards
配置Grafana的数据源
附件列表