TOC
资源指标
如果我们真要去构建一个Kubernetes集群的时候,且不说一个完整的Kubernetes集群应该是什么样子的,至少一个集群当中应该有多个节点,而这多个节点之上又有可能运行有不等数量的Pod资源,很显然,作为管理员来讲,我们必须能够随时得知当前每个集群之上的每个节点的资源利用率,每一个节点之上的每一个Pod的资源利用率,Pod资源是否工作正常,以及被重启或者重建过多少次等相关信息,我们也不应该让没有被监控的任何组件投入到生产环境中去;
在Kubernetes时代这个逻辑依然是成立的,也就意味着我们通常必须要在Kubernetes集群之上去部署一个,用于监控当前Kubernetes集群的各个节点的资源使用状况,无论是系统级的、程序级的还是业务级的各种各样的指标数据,当然这个监控系统究竟是部署在Kubernetes之上还是工作于Kubernetes系统之外,那就另当别论的;
把一个系统围绕着Kubernetes构建时,能够工作于Kubernetes之上才能更好的去利用Kubernetes本身的特点,如果我们要对Kubernetes进行一个所谓的系统指标采集的操作,我们最好能够将这个采集的程序部署在Kubernetes之上,工作于一个Pod,并且使用Pod控制器来控制它,万一出现故障还能够使用编排系统自身的功能,重新对其进行恢复等工作,万一一个Pod无法实现整个集群的监控,我们还可以按需对其进行扩容和缩容等操作;
另外,Kubernetes的内建调度器,在调度时本身也需要根据指定节点当前的资源利用状态,以及Pod资源需求进行调度,所以究竟某一个节点之上,资源已经分配出去多少,至少实施利用率如CPU、内存、磁盘等资源是何等状态,我们应该及时获取,不光是我们作为管理员来讲需要获知,Kubernetes之上的很多组件也需要获知,比如像调度器,它也需要了解每一个节点之上的实时利用状态,和已分配的状态结果,因此指标数据的获取,在Kubernetes之上应该是一个基础功能,甚至是Kubernetes自身的命令比如kubectl top pod它也需要获取到相关节点的指标之后才能获得数据的,比如想看一下当前系统上的指定名称空间下每个Pod的CPU占用率,它的内存占用状态等,如果没有这么一个指标数据,那么我们就无法获知;
因为top本身就是要获取每个Pod资源状态,而Pod本身内部无非就是一个容器,容器是运行在集群中的某一个具体节点上的,而当前名称空间的所有Pod很有可能是分散在当前集群节点的各个节点,那这个top命令就意味着,Kubernetes需要联系每一个节点去采集相关节点上的Pod容器的资源状态,并完成聚合计算,再返回,那么很显然我们把这个功能交给Pod去实现这是一个不大容易完成的工作,因此,为了便于实现整个集群之上的资源指标采集,存储和获取Kubernetes直接在每一个节点上的Kubelet内建了一个指标采集接口,也就是说每一个节点的Kubelet内部有一个程序,专门负责采集当前节点上的各种指标数据,包括节点的资源利用率,当前节点之上所运行的每一个容器的资源利用,都能采集,所以从这个角度来讲,它更像是一个Kubelet内建的一个监控agent,它被称为叫做cAdvisor,早起它监听在每一个节点之上的TCP/4194端口之上,但是新版本的Kubernetes把这个端口都给关闭了,因为考虑到指标泄露带来的安全隐患,在必要时我们只需要向这个cAdvisor发起请求就可以,所以从某种意义来讲cAdvisor是Kubelet对外输出的某一API的端点,那这个端点通常需要我们的ApiServer去获取;
每一个节点虽然内建了cAdvisor但是我们执行kubectl top命令会发现还是会有问题,top命令还是得联系每一个cAdvisor取得数据还需要在本地进行聚合计算才可以获取结果,这多麻烦,因此,为了避免这样的问题存在,这个数据的采集操作等,我们可以在Kubernetes之上,专门部署一个数据聚合程序来实现,它可以直接运行为一个Pod,这个Pod自己负责,向Zabbix Server一样,通过每一个节点的cAdvisor去采集,并且聚合数据,采集过了的数据可以通过这个程序再对外提供一个API接口,而后我们的Kubectl的top命令,就可以向这个API发起查询请求,并将结果予以显示,这个聚合程序实时工作,不停的周期性的来获取当前集群上的节点级的、Pod级的等各种各样的指标数据,采集完以后,如果有必要,我们还可以将它存储下来,存储到指定的存储空间当中,随时等待监控系统或者实时资源指标采集和监控的方式来获取,因此我们的top命令以后再也不用去每一个节点获取数据然后再聚合再展示了,因此这儿已经有结果了,它只需要向这个数据聚合程序发起查询请求就可以了;
而在Kubernetes之上,各种各样的查询请求,都应该以资源的方式,或者资源状态的方式,因此在Kubernetes之上这些被整个到了的Metrics这个API群组当中,它的群组就叫做Metrics,但是这个群组默认是不存在的,因为它本身并没有被Kubernetes直接提供,需要由用户按需去部署这么一个Pod,并注册在当前的Kubenetes之上生成一个新的群组;
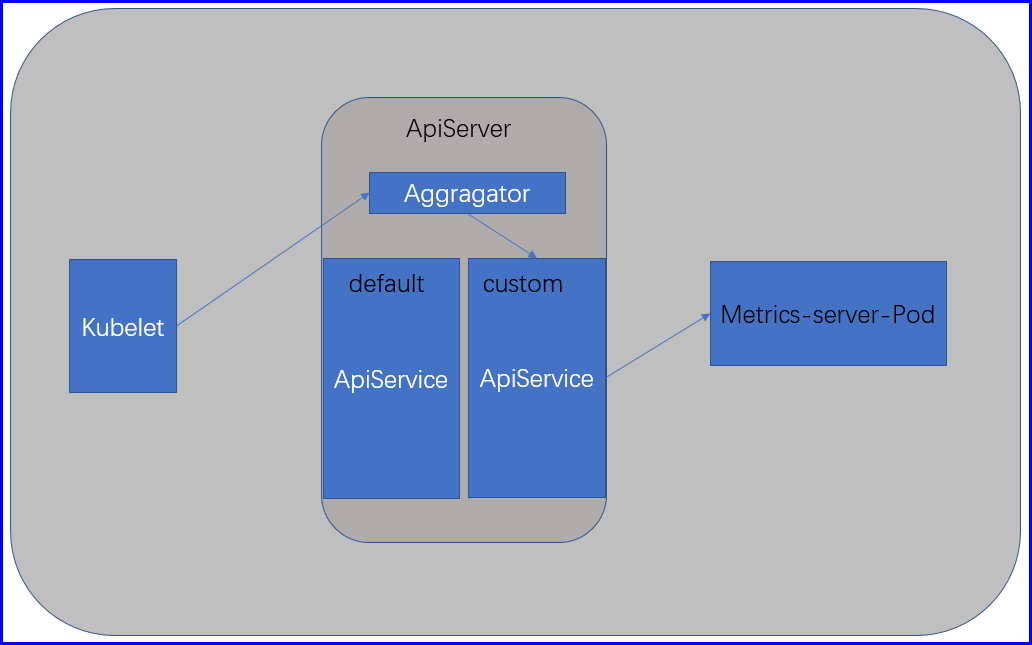
因为每一个API群组都是ApiServer所提供,所以我们可以理解为这个数据聚合程序它就是提供了一个自定义的资源类型,并且这个自定义的资源类型,是以ApiServer的方式在运行,这个ApiServer所提供的API要想能够让用户通过我们的Kubernetes的API来访问,那么我们的top命令,就不应该直接联系这个第三方的ApiServer,而是只能联系我们的内建的ApiServer,那么正常情况下,它联系的应该是我们的ApiServer内部的代理服务器Aggregator,我们可以在Aggregator上自定义一个群组名和版本,把客户端对于这个一个群组名的版本的访问给它代理至自定义的ApiServer上;
因此这个Pod其实就是一个自定义的ApiServer,用于扩展当前集群上的功能,它同时内部还有程序负责采集数据聚合数据的,当然需要注意的是,我们的Kubernetes所需要的指标除了节点和Pod级别CPU、内存和磁盘等指标之外,还有很多程序级的业务指标,比如Nginx的并发连接数,过去平均每一秒所接入的请求数等指标数据,这些都是监控系统所应该完成的任务,而Kubernetes内部只用到了最核心最核心的CPU、内存、磁盘空间、磁盘IO等几个指标,其他指标是用不着的,因此这个监控系统很可能也之能通过cAdvisor也之能获取到这个(CPU、内存、磁盘空间、磁盘IO)几个指标,因此这几个指标也被称之为核心指标;
当然,其他指标监控是需要的,所以早起的时候Kubernetes提供了一个HeapSter这么一个程序,来负责完成此类功能,这个HeapSter作为服务端能够联系每一个cAdvisor来采集节点级的指标数据,并且这个数据能够直接响应kubectl top命令的查询,但这种响应是实时查询,如果我们期望去查询过去的指标数据,因为我们的HeapSter默认不能去存储数据,所以它需要利用一个Data Sink来存储数据,而HeapSter所支持的Data Sink有很多,比如Influxdb,究竟支持多少种Data Sink这取决于HeapSter内部的插件支持将数据存储于哪一种存储系统当中,因此HeapSter也采用了高度模块化的架构,允许第三方组织维护一个内建的插件,从而对接外置的存储系统,只要能够存储下来,那么用户就能查询历史数据,不过很遗憾HeapSter的设计体系架构有问题,因此在近来的Kubernetes版本当中HeapSter已经被废弃了;
当然HeapSter加上这个,Influxdb只是当年解决方案之中的两个组件,还有第三个叫grafana,一个通用的数据展示面板,还可以整合在我们的Elasticsearch之上,不过在Elasticsearch之上它叫做Kibana,它是grafana的前身,那么HeapSter采集数据存入Influxdb当中,然后使用grafana进行数据展示,这也是早期Kubernetes之上的监控系统,一个唯一的通用的解决方案,但是HeapSter在设计体系存在各种各样的问题,所以到后来HeapSter的功能已经被另外一个组件替代了,这个组件到目前已经被CNCF纳入并且已经毕业的一个项目,叫做Prometheus;
Prometheus
它是一个非常著名的监控系统,同时Prometheus自身是一个高性能的时间序列数据存储和查询接口,因此Prometheus一样得结合grafana,同时Prometheus内部内置了非常强大的查询接口,叫做ProSQL,用户可以通过它的http接口组合非常复杂的查询条件来获取用户所关注的数据;
当然我们也能够借助于ProSQL这样的接口将数据给它用非常直观的方式予以展示,但是需要注意的是Prometheus采集数据时,也能够通过cAdvisor来获取数据,但是Prometheus自己本身也能够在每一个节点之上部署一个Prometheus的专用agent(nodeExporter)来采集更为复杂的指标,这有可能是cAdvisor本身所不支持的指标,因此从某种意义上来讲,它是一个完整意义上的监控报警系统,它的报警插件要使用AlertManager来实现;
AlertManager这样的报警实现,需要由用户自己定义才能使用,但是Prometheus能够实现非常复杂的高度监控级别,更重要的是Prometheus内建了弹性监控接口,它可以支持自动发现机制,来发现每一个可被监控的对象,比如Pod经常性的删除和创建,那么Prometheus就能够自动添加它所发现的Pod,并且某个Pod失去了以后还能自动移除等各种各样的高级功能,所以特别适合容器平台的容器相关指标的数据采集,同时Prometheus能够在每一个节点之上部署一个叫做nodeExporter的组件来专门实现节点级的更为完善的系统级的资源采集,并能使用其他专用Exporter某一个具体的复杂应用指标,比如我们部署一个MySQL的Exporter也能让它监控MySQL内部的各种各样的指标数据,这对cAdvisor是完成不了的;
因此新版本当中Kubernetes就把这个监控系统,从HeapSter改为了Prometheus,但是Prometheus过于重量级了,因为这个监控越强大,那么这个量级就越来越重,如果用户不太需要必须用到Prometheus的功能又得需要核心指标功能,比如想运行一个kubectl top命令,但是为了一个top命令就是部署一个Prometheus实在是太重了;
因此新版本的Kubernetes把他们内部对应的指标,分成了两类;
指标
核心指标:CPU、Memroy、Disk等,这些指标用cAdvisor就可以采集,核心指标数据的,而核心指标数据的提供是由Metrics-Server提供的,它是cAdvisor之后的数据聚合器,这是 Kubernetes正常工作所需要的核心度量,从 Kubelet、cAdvisor 等获取度量数据,再由Metrics-server提供给 Dashboard、HPA 控制器等使用;
扩展自定义指标:除了CPU、Memroy、Disk这些核心指标之外我们还能去采集指定应用程序的指标,应用程序的业务指标,那么这个时候cAdvisor是做不到的,那么我们就可以使用Prometheus来扩展由用户自定义指定Kubernetes所不支持的外部指标数据;
Metrics-server来负责专门提供核心指标,该指标数据从cAdvisor里面获取;
Prometheus来专门负责提供自定义指标,该指标数据从cAdvisor里面获取nodeExporter里面获取;
早期这两个功能是由HeapSter一个组件来提供的,而HeapSter由于设计体系的缺陷,使得它的变动和扩展非常的麻烦,而有了Prometheus和Metrics-server以后这个功能就变得简单多了,因此我们现在要引入一个核心指标群组、自定义指标群组,而这个群组所提供的自定义资源类型或者API接口需要由外置的ApiServer提供,所以Metrics-server用来负责提供metrics.k8s.io这个群组的核心指标数据,而Prometheus负责custom-metrics.k8s.io提供自定义指标,这是两个不同的群组,而这两个群组背后都是通过自定义ApiServer来提供的,比如Metrics-server需要额外运行一个Pod,这个Pod就是运行Metrics-server的服务的,Prometheus也一样,也需要额外运行一个Prometheus的agent Pod服务来提供的;
于是他们都需要通过ApiService注册到我们的当前的集群上来,才能够被使用的,但是核心指标的采集通常都是为了能够实时获取这些指标数据,得根据指标数据的结果来判定下一步的行为的,因此Metrics-server采集的指标是不存储的,没法查询过去的历史数据,而Prometheus是可以存储的,所以从这个角度来讲Metrics-server只提供实时指标,而Prometheus是一个监控系统,不断能够提供实时指标还能提供历史指标;
CNCF的Metrics-server:<a href="https://github.com/kubernetes-sigs/metrics-server">https://github.com/kubernetes-sigs/metrics-server</a>
Kubernetes的Metrics-server:<a href="https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server">https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server</a>
部署Metrics-server
因为Kubernetes下面给出的Metrics-server配置清单是只符合特定版本,所以这里直接使用CNCF下面的版本,但是还是需要稍加修改,在metrics-server-deployment.yaml增加一行command,具体的看附件,至于image可以使用google的registry.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6;
[root@node1 ~]# ls metrics-server/
aggregated-metrics-reader.yaml auth-reader.yaml metrics-server-deployment.yaml resource-reader.yaml
auth-delegator.yaml metrics-apiservice.yaml metrics-server-service.yaml
[root@node1 ~]# kubectl apply -f metrics-server/
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
# 查看ApiGroup
[root@node1 ~]# kubectl api-versions|grep metrics
metrics.k8s.io/v1beta1
# 查看ApiService
[root@node1 ~]# kubectl get apiservices.apiregistration.k8s.io |grep metrics
v1beta1.metrics.k8s.io kube-system/metrics-server True 26m
[root@node1 ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node1.cce.com 333m 16% 728Mi 19%
node2.cce.com 105m 5% 358Mi 9%
node3.cce.com 131m 6% 384Mi 10%
[root@node1 ~]# kubectl top pod -n kubernetes-dashboard
NAME CPU(cores) MEMORY(bytes)
dashboard-metrics-scraper-76585494d8-d5pdr 1m 12Mi
kubernetes-dashboard-6b86b44f87-bf5p9 2m 15Mi
总结
metrics-server通过一个固定server'访问入口向前端提供访问,这个server其实就是扩展Kubernetes集群的功能,同时也包含了自定义的ApiServer,用户的请求到达kube-aggragator以后会直接代理给metrics-server的ApiService,然后请求会直接流行metrics-server的service继而达到metrics-server的Pod;
除了kubectl top这个命令需要用到metrics-server之外,还有一个组件也需要用到,叫做HPA水平Pod自动伸缩器,我们创建HPA控制器之后,HPA是工作与deployment或者statefulset控制器之上,我们可以有一个deployment,由此deployment的replicaset控制的应该运行的有多少个Pod资源,如果某一天我们发现,这个deployment下面的三个Pod副本,每一个Pod我们给它指定的CPU或者内存占用率达到了百分之八十,内存也比较高,如果我们的资源指标占用比较高,那么在deployment的控制器下负载是高还是低,我们的人工检测或者使用kubectl top命令来获取资源利用率,需要人为手工去扩展集群规模;
那么这种情形在HPA控制器的控制下,它是一个比deployment更高级的控制器,它工作于deployment之上,它通过类似于kubectl top这样的命令,监视者指定的这个deployment控制器当前的所有Pod资源的资源占用比例,如果评论所以的Pod系统资源占用比例高达百分之八十,那么此时假设我们的管理员设定了达到百分之八十,那么就由我们的HPA控制器自行处理,那么此时我们的HPA控制器,会自动的按照这个比例计算的结果自动新增一个新Pod或者多个新Pod进来,应该添加多少个,HPA会通过计算结果的均值得知,必须要确保能满足所有Pod的资源占用量低于我们所期望的水平线下才行;
因此HPA能够为我们的传统的控制器自动伸缩,这个Pod规模,万一平均每个Pod的资源占用率低于百分之二十,HPA会认为资源浪费,然后自动移除几个Pod,确保所有Pod的资源占用比例要大于百分之二十小于百分之八十(具体大于多少小于多少由管理员设定),那么对于HPA控制器应该也有一个规模下线,因为即使我们的程序部署上去所有的Pod都只占用百分之一那么如果没有下限就会出问题,确保至少有几个Pod存在,同时,我们还可以定义规模上限,如果Pod规模达到上限,即使我们的资源使用率达到了峰值也不会再添加,当然一旦低于下限也不会减少;
所以HPA如果不能获取都当前被这个指定的deployment下面的Pod的计算资源使用率的话,那HPA是没法作为评估标准,目前来说HPA又分为两个版本一个是HPAv1,一个是HPAv2;
扩展
HPAv1只能根据计算CPU资源的占用率,内存貌似也支持,来进行伸缩,但是,在有一种极端场景,每一个Pod计算资源都不是太高,但是每一个Pod已经负载了3000个请求,而3000个是我们单个Pod并发请求的上限,很显然这个时候也满载了,这个情况下我们的HPAv1控制器却没办法通过添加Pod数量来实现减轻已有Pod负载的,因为它只关注CPU和内存,因此如果我们要关注业务级指标的话,比如我们的Nginx连接数量, 或者当前MySQL的IO数量,这些情形HPAv1都不支持;
HPAv2,支持自定义指标,目前来讲,通常它的提供都是由Prometheus来实现,简单来讲,Prometheus其实算得上是一个监控系统,监控系统也会采集数据的,但是监控系统采集的数据不一定都是指标数据,因为我们能够监控的数据有多种类型,每一种类型都可以是指标数据的,也不一定能够被kubernetes之上的API使用,我们必须将其转为指标数据格式,或者仅保留支持转为指标数据格式的采样结果,才能够让其作为指标使用,而且这个指标既包含核心指标,又包含自定义指标,比如业务级别的指标,这些在核心指标都不包含的,但是Prometheus能够监控,并能够采集到,但是采集到的本身的数据并非是指标格式的,所以我们需要将其转为指标格式,并映射成一个ApiService从而能够将其路由之后被Prometheus来处理才可以使用;
Metrics-server本身之能提供最核心的指标资源数据,CPU、Memory、Disk如果想获取更多的指标数据,通常使用Prometheus,但是Prometheus自身只是一个监控系统,它采集到的只是存储在存储系统当中,并能够使用Grafana等展示界面展示,它不能在Kubernetes上以API接口的形式访问,要想能访问,我们还得把Prometheus采集到的数据转为指标数据,并通过一个自定义的API接口向外进行输出,所以从这个角度来讲Prometheus既可以作为监控系统,也可以作为自定义指标数据的供给方来使用,如果作为自定义指标的供给来使用的话,那么我们就得向部署Metrics-server意义,把我们的Prometheus部署到我们的Kubernetes集群上才行;