TOC
持久化查询
可以看到不管是一对一还是一对多,这种查询语法可能有时候写起来不是一件容易的事,而且如果没有保存下次还需要重新编写语句,这可能是一种比较繁杂的事情,所以,在很多时候,我们希望能够将我们精心编写好的复杂查询语句给它保留起来,那么Prometheus就提供了这种接口,即,持久查询,但这不是一种让我们任意表达,或者说,任意编写的接口;
记录规则
在样本数据量较大,工作繁忙的Prometheus Server上,对于那些查询频率较高,而且较为复杂的查询来讲,不仅编写查询语句困难,而且对于这种实时查询可能会存在较高的查询延迟情况,那么这个时候,我们就可以使用Prometheus内建的记录规则功能,予以保留;
记录规则,Prometheus能预先将频繁用到计算消耗较大的表达式,周期性进行运算这种表达式,而把表达式的结果,存储为一个时间序列,比如在Prometheus,我们很有可能会用到那种计算复杂,并且需要参与计算的数据量较大查询语句,这个结果很有可能将来还需要被Grafana展示,因为Grafana一般都是实时查询的,如果遇到这种类型的指标,实时查询可能会对Prometheus的整体工作效率产生较大的影响,因为计算代价非常高;
为了避免这种问题,就可以使用记录规则,让Prometheus Server把这种计算规则或者说查询语法给它保存起来,然后由Prometheus Server自己在后台周期性进行运算,并且将结果存储为一个时间序列,那么随后Grafana就不需要查询这种实时计算的指标了,而是直接查询预先在后台计算的结果就可以了,这就是记录规则;
记录规则其实就是保存在Prometheus配置文件中的查询语句,在Prometheus Server启动的时候,在加载配置文件之后,它能够类似于批处理的任务在后台周期性执行,所以这种查询速度,是远优于实时查询的;
记录规则配置
记录规则将生成新的时间序列,因而其名称必须是规范的指标名称格式,记录规则定义在规则组中(rule group),如果有多条规则的话,各个规则按给定的顺序进行,首先定一个规则组,然后在每一个组当中定义一条一条的规则,然后在定义表达式,最后我们需要在Prometheus配置文件中去载入我们的规则,就类似定义基于文件的服务发现很相像;
# Prometheus配置文件
global:
alerting:
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: # 定义rules记录规则文件
- rules/*.yaml
scrape_configs:
# rules配置文件
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum by (job) (http_inprogress_requests)
示例
分别求出服务器的CPU、内存和磁盘当前的可用百分比,公式为100%-已使用百分比=剩余百分比;
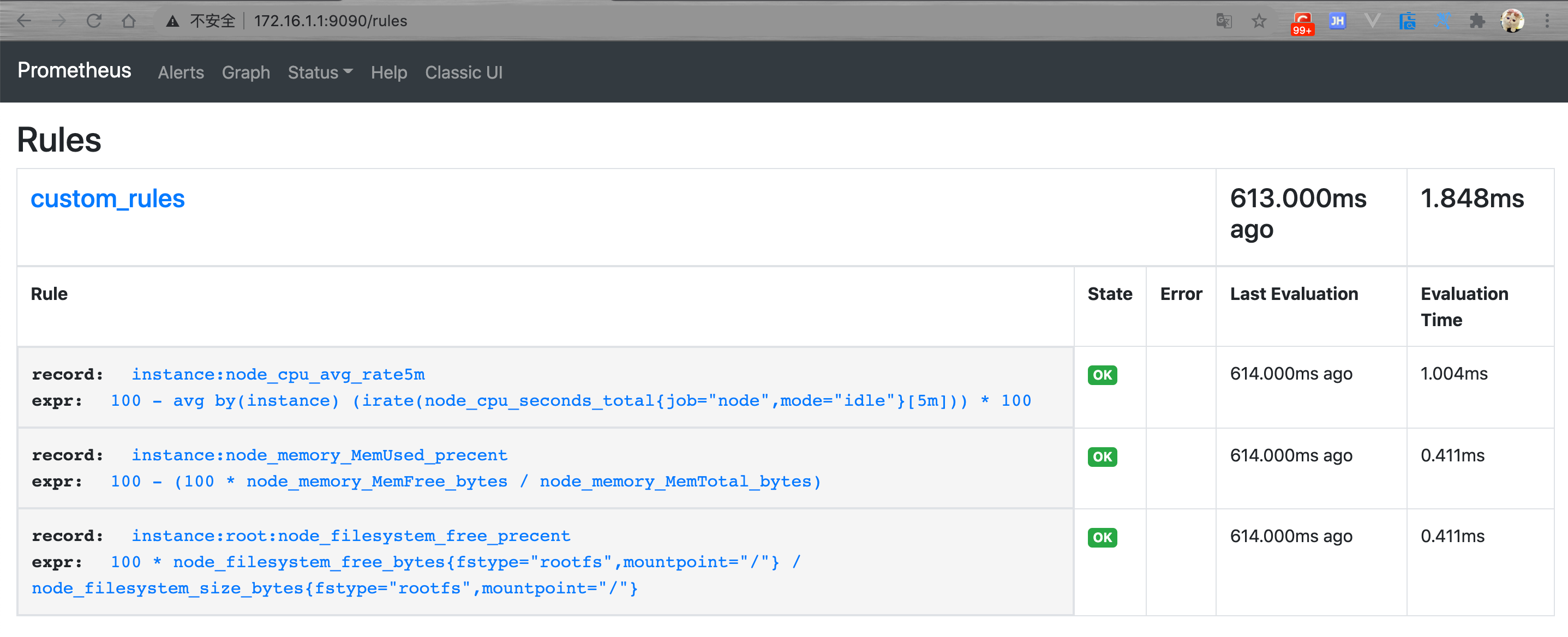
[root@node1 ~]# cat /usr/local/prometheus/rules/custom-metrics.yaml
groups:
- name: custom_rules
interval: 5s
rules:
- record: instance:node_cpu_avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job='node',mode='idle'}[5m])) by (instance) * 100
- record: instance:node_memory_MemUsed_precent
expr: 100 - (100 * node_memory_MemFree_bytes/node_memory_MemTotal_bytes)
- record: instance:root:node_filesystem_free_precent
expr: 100 * node_filesystem_free_bytes{fstype="rootfs",mountpoint='/'}/node_filesystem_size_bytes{fstype="rootfs",mountpoint='/'}
# 修改规则需要重启Prometheus Server
告警规则
除了记录规则还有一种规则也能够保存下来,即告警规则,告警规则是另一种定义在Prometheus配置文件中的一种PromQL表达式,它通常是一种Bool表达式,返回值要么是True要么是False,主要用于告警;
Grafana
直接在Prometheus上编写规则,这种规则不便保留下来,而且这种展示的图形很多时候也不是那么美观,那么就可以使用Grafana来进行缺陷的不足,Grafana是基于GO语言开发的通用的可视化工具,它支持从多种不同的数据源加载并展示数据,Prometheus只是其中一个,还有IfluxDB、OpenTSDB、Graphit、Loki、Elasticsearch、Tempo、MySQL、PostgreSQL等;
Grafana默认监听于TCP协议的3000端口,而且Grafana自己也可以通过3000端口的/metrics路径也可以生成自己的指标,Grafana有几个概念;
数据源(Data Source):提供用于展示的数据存储系统;
仪表盘(Dashboard):组织和管理的可视化面板(Panel);
团队和用户:提供了面向企业组织层级的管理能力;
[root@node1 src]# tar xf grafana-8.0.0.linux-amd64.tar.gz
[root@node1 src]# mv grafana-8.0.0 /usr/local/grafana
# 新增启动脚本
[root@node1 ~]# cat > /usr/lib/systemd/system/grafana.service << EOF
[Unit]
Description=Grafana
After=network.target
[Service]
Type=notify
ExecStart=/usr/local/grafana/bin/grafana-server -homepath /usr/local/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动Grafana
[root@node1 ~]# systemctl daemon-reload
[root@node1 ~]# systemctl start grafana.service
[root@node1 ~]# netstat -ntlp|grep 3000
tcp6 0 0 :::3000 :::* LISTEN 1818/grafana-server
# 默认账号密码为admin
# grafana自己也提供了一个/metrics接口,来暴露自己的指标,所以我们也可以将Grafana纳入到Prometheus监控当中,然后使用Grafana监控
# 配置Grafana为一个Target
[root@node1 ~]# cat /usr/local/prometheus/targets/nodes-linux.yaml
- targets:
- node1.cce.com:3000
labels:
app: grafana
job: grafana