TOC
PromQL聚合计算
大多数指标采集下来之后,我们也不可能一个一个去看它的样本值,这没什么实际的意义,假设我们的Web服务器跑了个二十个实例,这些实例上主机的响应时长,我们也不可能一个节点一个节点的看,所以在多数情况下,很有可能把多个Target上的同一个指标合并起来统一进行计算,比如求他的平均值之类的;
所以一般来讲,单个指标的意义不大,监控场景中,往往需要联合并可视化一组指标,这一组指标很可能是来自于不同Target的同一指标,也有可能是位于某一个对应的指标名称下的多个纬度,然后将这多个纬度给他联合起来进行计算,那么这种联合机制就是所谓的聚合操作,比如,计数、求和、平均值、分位数、标准差和方差等统计函数,将这些函数应用于时间序列样本之上,就可以生成具有统计学意义的结果,我们也可以对查询结果,按照某种分类机制进行分组(group by),将查询结果按组进行聚合计算,这也是较为常见的需求,例如分组统计、分组求平均值、分区求和等;
对于聚合操作,PromQL提供很多内置的聚合函数,它可以针对一组值进行计算,并返回单个值,或少量几个值作为结果,Prometheus内置提供了11个聚合函数,也称之为聚合运算符,这些运算仅支持应用于单个即时向量的元素,这也就意味着这些聚合函数是不支持使用在范围向量之上的,其返回值也是具有少量元素的新向量或标量,这些聚合运算符既可以基于向量表达式返回结果中的时间序列的所有标签纬度进行分组聚合,也可以基于指定标签纬度分组后再进去分组聚合;
sum():对样本值求和;
avg():对样本值求平均值;
count():对分组内的时间序列进行数量计算;
stddev():对样本值求标准差,以帮助用户了解数据的波动大小;
stdvar():对样本值求方差,它是求取标准差过程中的中间状态;
min():求取最小值,返回其时间序列及其值;
max():求样本值中最大的值,返回其时间序列及其值;
topk():逆序返回分组内的样本值,最大的前k个时间序列及其值;
bottomk():顺序返回分组内的样本值,最小的前k个时间序列及其值;
quantile():分为数,用于评估数据的分布状态,该函数会返回分组内指定分为数的值,即数值落在小于指定分位区间的比例;
count_values():对分组内的时间序列的样本值进行数量统计;
聚合表达式
PromQL中的聚合操作语法格式可采用如下面两种格式之一;
<aggr-op>([parameter,]<vector expression>)[without|by (label list)]
<aggr-op> [without|by (label list) ([parameter,]<vector expression>)]
# aggr:聚合操作符;
# op:operater;
# without:从结果向量中删除由without子句指定的标签,未指定的那部分标签则用做分组标准;
# vector expression:向量表达式;
# by:功能与without刚好相反,它仅使用by子句中指定的标签进行聚合,结果向量中出现但未被by子句指定的标签则会忽略;
# 分组求和
sum (node_filesystem_avail_bytes) by (instance)
# 分组统计
count by (mountpoint)(node_filesystem_avail_bytes{mountpoint=~'/boot|/'})
内置函数
内置函数不是聚合函数,内置的函数它可以在对应的时间序列上做计算的,所以我们可以将他们理解为Prometheus的函数,这些函数就没有聚合函数的约束和限制了,他们各自所适用时间序列类型略有不同;
rate(range-vector):rate函数需要传递一个范围向量,对这个范围向量对应范围内的数据做增长率计算,一般仅用于Conter计数器上,因为对Guage类型的数据做rate是没有意义的,Guage本身就代表了随着时间变化的量,而Conter没能直接表达随时间变化的结果,所以才需要使用rate进行计算,rate的计算结果还可以求和,将rate和sum联合起来计算时,是先算rate后求和;
increase:increase函数,和rate函数类似,increase函数在prometheus中,是专门用来针对Counter这种持续增长的数值截取一段时间的增量趋势的,这样的话,我们就可以利用它来得到CPU当前针对上一分钟的增量值了,对于rate函数,是取得平均每秒的数量的,比如我们取的是1m,那么就会将这个1m的值除以60s,最终得到每秒的平均值,那么对于increase函数来说,它就比rate函数要粗糙一些了,它是取段时间增量的总量,但是它并不对秒进行除法运算,比如说increase(node_network_receive_bytes_total[1m]),它就是取node_network_receive_bytes_total一分钟内,从开始到结束,增长的总量作为数值返回,它不进行除法运算;
语法: increase(node_cpu_seconds_total{instance="172.16.1.2:9100"}[1m]) # 截取cpu在这一分钟之内的增量值
sum: increase非常好用,但是它之能计算单核CPU的在一个时间区间内的增量值,但是又因为我们现在的服务器都是多核CPU,运维人员也一般都是关注整体的CPU示例比率,很少去关注每一核的CPU占比值,所以这个时候我们的sum就可以发挥作用了,它就是字面意思,求和,那么我们可以利用sum将所有核心的CPU使用量进行求和,然后再使用increase进行范围增量取值;
语法:sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))
by:by,即分组,可以看到上面的sum得到的结果是一个大结果,并且只有一个结果,如果我们要统计多台服务器的CPU增量率,那么如果不使用by也会变成一条线,因为sum是把所有的结果集,不管是什么内容,全部进行加和了,那么这个时候我们就需要用到by函数,将结果进行分组,那么这个例子,我们就可以以instance这个label作为分组的key了,by后面需要接一个lebel;
语法:sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
topk:该函数可以从大量数据中取出排行前N的数值,N可以自定义。比如监控了100台服务器的320个CPU,用这个函数就可以查看当前负载较高的那几个,用于报警;
二元运算符
二元运算符也是Prometheus的最强大的功能之一,二元运算符又是一种非常高级的运算逻辑的一个非常重要的表达式,PromQL支持基本的算数和逻辑运算,我们完全可以将两个向量表达式链接起来,逐一比较,类似就并集、交集等;
支持使用操作符链接两个操作数就称之为二元运算符,它支持两个标量之间进行运算,比如1+1,支持即时向量和标量之间运算,比如1+sum (node_filesystem_avail_bytes) by (instance),同时也支持两个即时向量之间的运算;
# 算数运算
+:加法;
-:减法;
*:乘法;
/:除法;
^:幂运算;
# 比较运算
==:等值比较;
!=:不等值比较;
>:大于;
<:小于;
>=:大于等于;
<=:小于等于;
# 逻辑运算(目前仅支持在两个即时向量之间进行,不支持标量参与运算)
and:并且;
or:或;
unless:除了;
向量匹配
即时向量匹配运算是PromQL的特色之一,运算时PromQ会为左侧向量中的每个元素找到匹配的元素,其匹配行为有两种基本类型,即一对一和一对多;
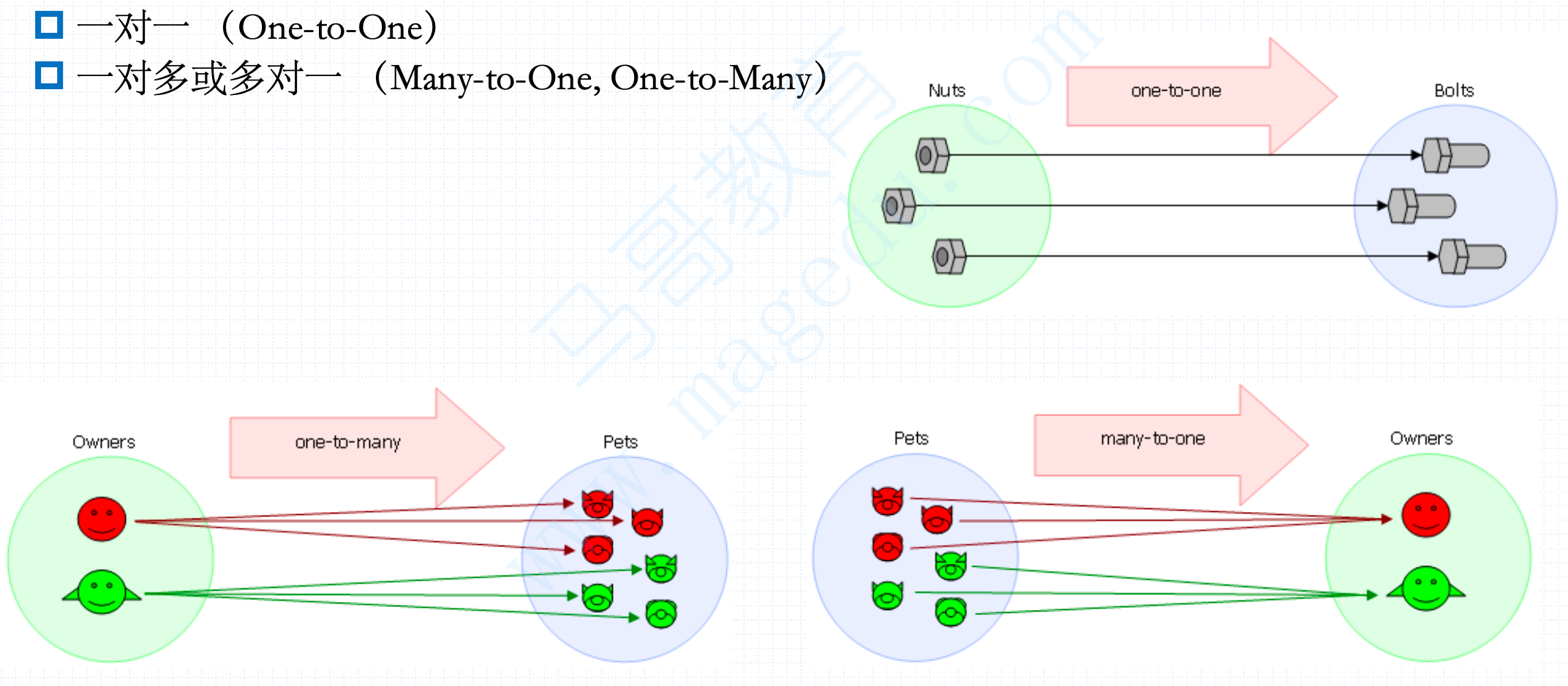
一对一匹配
即时向量的一对一匹配指的是,从运算符的两边表达式所获取的即时向量间一次比较,并找到唯一匹配(标签完全一致)的样本值,因为这是即时向量,意味着当前时间获取的最新值,当找不到匹配项的值时,则不会出现在结果中,这一操作在使用AlterManager做报警时大量使用;
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op>on(<label list>) <vector expr>
ignoring:定义匹配检测室需要忽略的标签;
on:定义匹配检测时只使用的标签;
示例
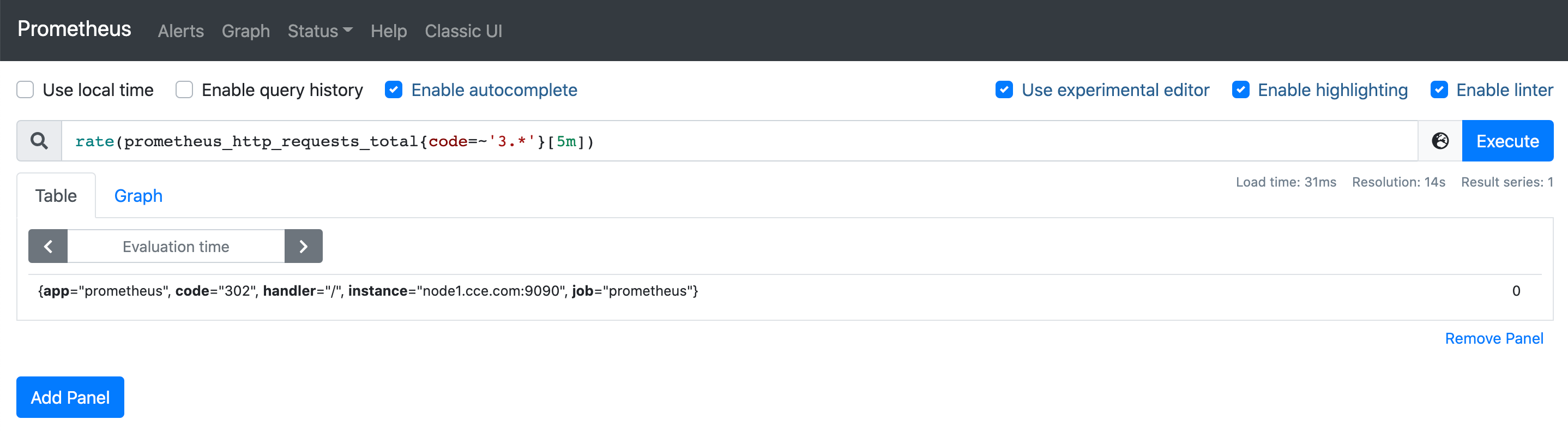
如下示例,左侧部分表示,找到http_requests_total指标标签为3开头响应吗的时间序列,并取出5分钟以内的指标数据,然后使用rate求得平均值,可能有302、303等能匹配到很多个时间序列,分别求出各类3xx响应码的请求增长速率;
注意:计算会生成新的时间序列,新序列和源序列标签是一样的;
右侧部分表示,计算http_requests_total标签所有的时间序列(不光有3xx响应吗,还有2xx响应吗等)的5分钟内每秒钟的增长速率;
注意:计算会生成新的时间序列,新序列和源序列标签是一样的;
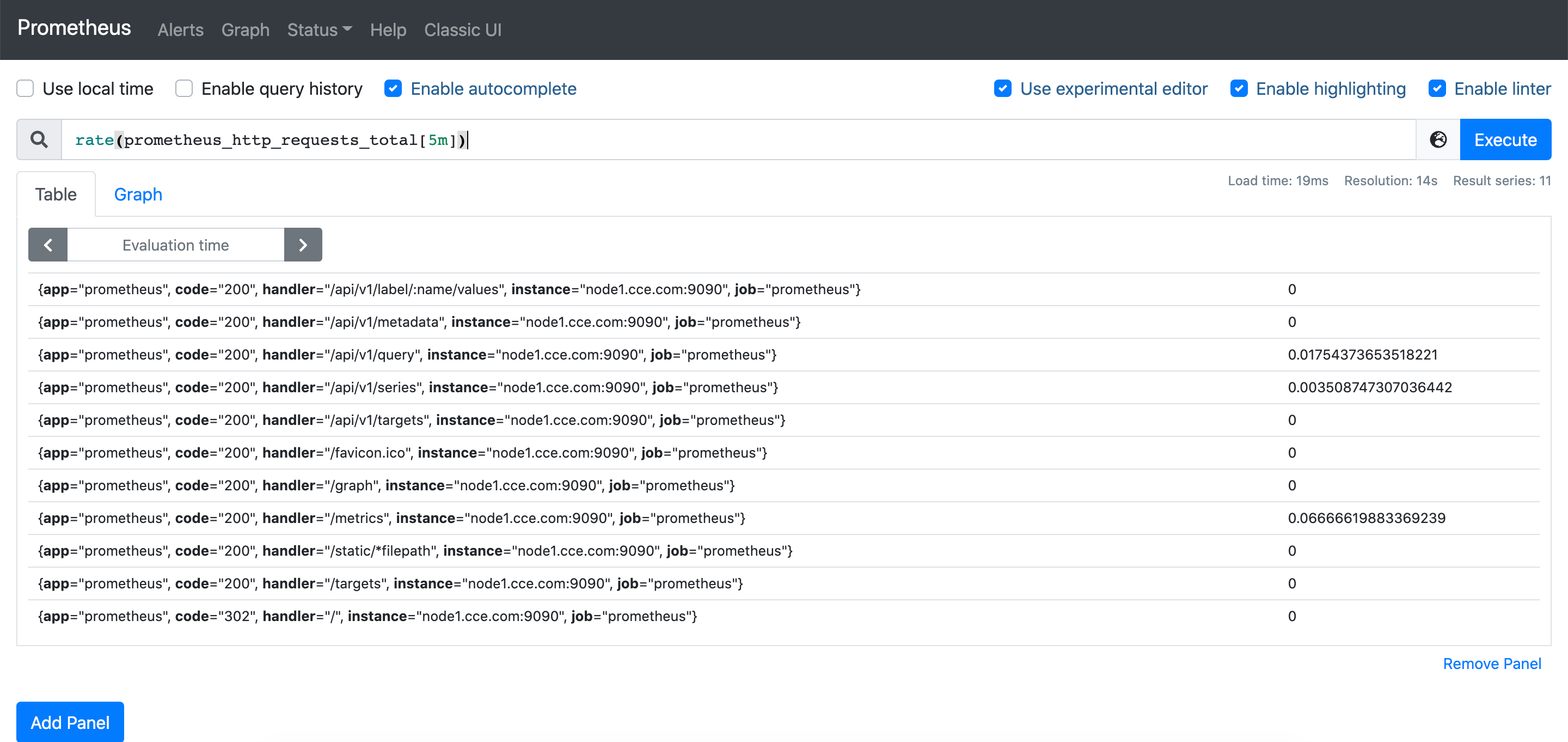
当左右两边都得到结果之后,PromQL会在操作符左右两侧的结果元素中找到标签完全一致的元素进行比较,其意义为,计算出每类请求中的5xx响应码在该类请求中所占的比例;
rate(http_requests_total{status_code=~'3.*'}[5m]) > 0.1 * rate(http_requests_total[5m])
# 计算响应码为3xx5分钟的平均速率是否大于所有请求5分钟速率的10%
案例
如下案例,以http响应码统计速率为例,首先第一批为单类请求方法和响应码指标统计速率,第二批为单请求方法统计速率,不做响应码限制;
# 第一批(请求方法和响应码统计)
rate(http_errors{method="get",status_code='500'}[5m]) 24 # 统计请求方法为get响应码为500的每五分钟的平均增长速率为24个
rate(http_errors{method="get",status_code='404'}[5m]) 30
rate(http_errors{method="put",status_code='501'}[5m]) 3
rate(http_errors{method="post",status_code='500'}[5m]) 6
rate(http_errors{method="post",status_code='404'}[5m]) 21
# 第二批(请求方法统计)
rate(http_requests{method="get"}[5m]) 600 # 统计get请求每五分钟的平均增长速率为600
rate(http_requests{method="delete"}[5m]) 34
rate(http_requests{method="post"}[5m]) 120
上述示例,当我们要求分别求出post、get请求错误码为500在整个http_requests对应的method的占比时,我们可以通过以下规则实现,需要使用ingoring来忽略标签,因为一边想码为500一边为所有的响应码,可能有2xx、3xx等所以需要忽略响应码,其他标签完全匹配即可;
# example
# 响应码为500 / 整个http请求 结果通过method进行一一匹配
rate(http_errors{status_code='500'}[5m]) / ingoring(code) rate(http_requests[5m])
# result
{method='get'} 0.04 # 24 / 600
{method='post'} 0.05 # 6 / 120
# 因为上述example忽略了code标签,所以只需要method一对一匹配即可,最终得到的值就是rate(http_errors{method="get",status_code=~'500'}[5m])和rate(http_requests{method="get"}[5m])匹配,rate(http_errors{method="post",status_code='404'}[5m])和rate(http_requests{method="post"}[5m])匹配;
一对多匹配
一对多匹配,对于"一"侧的每个元素,可与"多"侧的多个元素进行匹配,至于哪一边是"多",可以明确使用group_left或group_right来指定;
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op>on(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op>on(<label list>) group_left(<label list>)<vector expr>
ignoring:定义匹配检测室需要忽略的标签;
on:定义匹配检测时只使用的标签;
group_left/group_right:指定多的一方;
案例
如下案例,以http响应码统计速率为例,首先第一批为单类请求方法和响应码指标统计速率,第二批为单请求方法统计速率,不做响应码限制;
# 第一批(请求方法和响应码统计)
rate(http_errors{method="get",status_code='500'}[5m]) 24 # 统计请求方法为get响应码为500的每五分钟的平均增长速率为24个
rate(http_errors{method="get",status_code='404'}[5m]) 30
rate(http_errors{method="put",status_code='501'}[5m]) 3
rate(http_errors{method="post",status_code='500'}[5m]) 6
rate(http_errors{method="post",status_code='404'}[5m]) 21
# 第二批(请求方法统计)
rate(http_requests{method="get"}[5m]) 600 # 统计get请求每五分钟的平均增长速率为600
rate(http_requests{method="delete"}[5m]) 34
rate(http_requests{method="post"}[5m]) 120
上述示例,当我们要求分别求出post、get请求错误码为500在整个http_requests对应的method的占比时,我们可以通过以下规则实现,需要使用ingoring来忽略标签,因为一边想码为500一边为所有的响应码,可能有2xx、3xx等所以需要忽略响应码,其他标签完全匹配即可;
# example
# 响应码为500 / 整个http请求 结果通过method进行一对多匹配,左侧为多,右侧为一
rate(http_errors[5m]) / ingoring(code) group_left rate(http_requests[5m])
# result
{method='get',code='500'} 0.04 # 24 / 600
{method='get',code='404'} 0.05 # 30 / 600
{method='post',code='500'} 0.05 # 6 / 120
{method='post',code='404'} 0.175 # 6 / 120
# 因为上述example忽略了code标签,所以只需要method一对多匹配即可,http_requests为多的一方,http_errors为一的一方,最终得到的值就是rate(http_errors{method="get",status_code='500'}[5m])和rate(http_requests{method="get"}[5m])匹配,
rate(http_errors{method="get",status_code='404'}[5m])和rate(http_requests{method="get"}[5m])匹配,
rate(http_errors{method="post",status_code='500'}[5m])和rate(http_requests{method="post"}[5m])匹配,
rate(http_errors{method="post",status_code='404'}[5m])和rate(http_requests{method="post"}[5m])匹配;