2、监控系统基础应用
时序数据
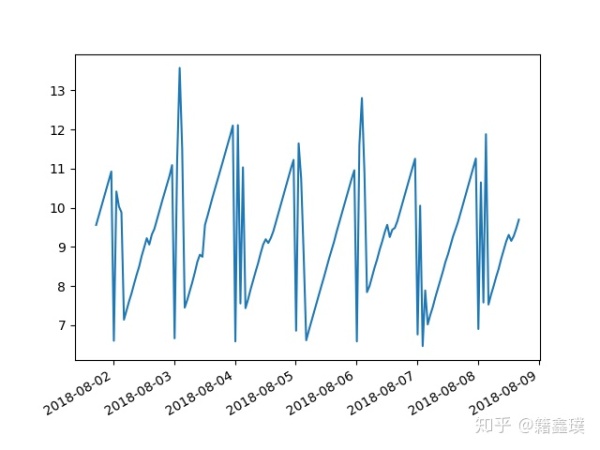
时序数据其实就是在一段时间内,通过反复侧量而获得的观测值的集合,这些集合是按照固定时间周期串联起来的,如果将这些观测值绘制在一个图形之上,它会有一个数据轴和时间轴,如下图,但是实际上我们采样的数据并非都是连续的,只不过绘制的图都链成了一个线了;
对于监控系统来讲,服务器的指标数据库、应用的性能监控数据、网络负载数据等都是时序数据,因为Prometheus抓出来的数据也都是时序数据;
数据抓取
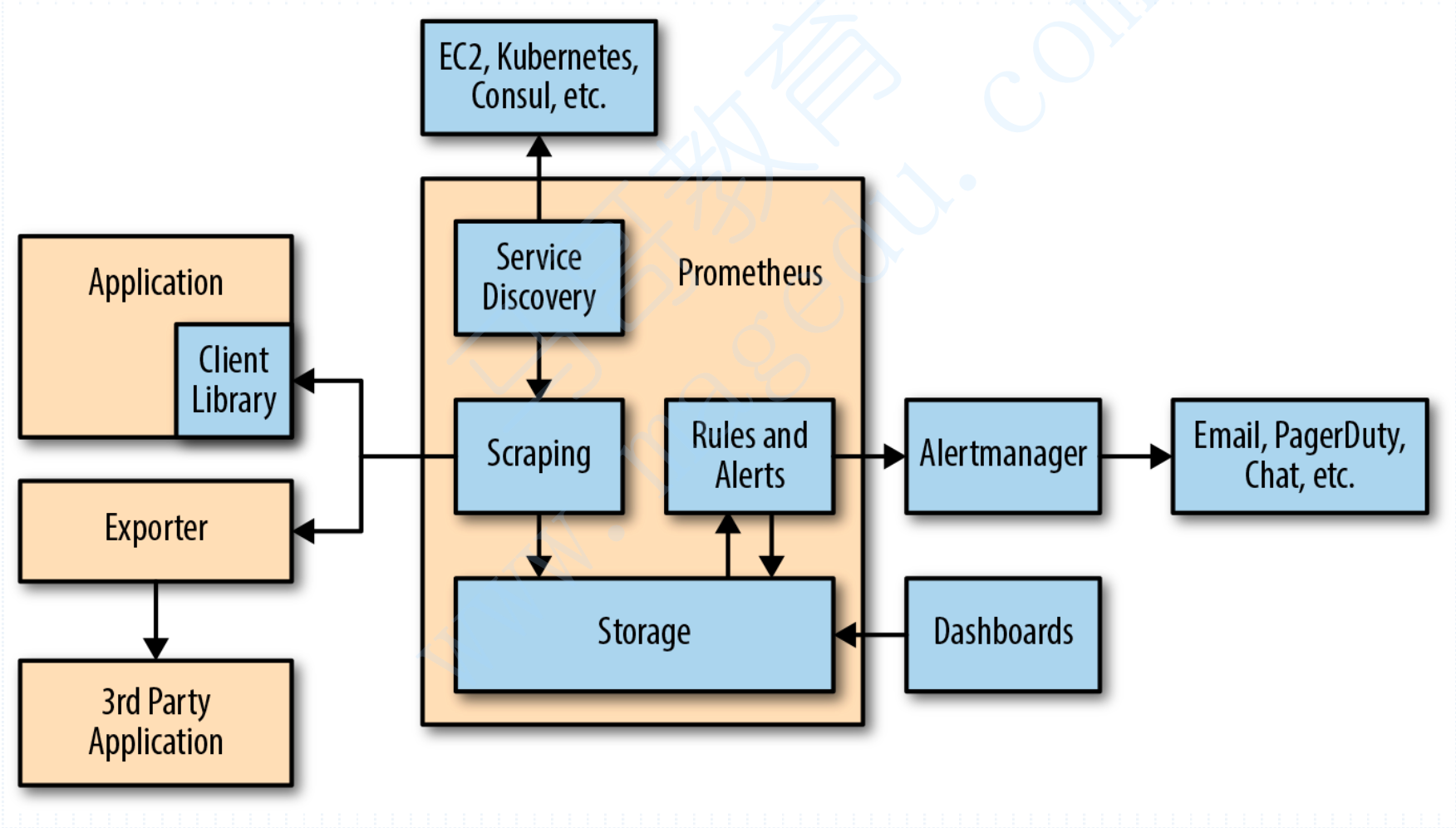
整个Promethues的监控生态当中,Prometheus Server是核心,它有四个核心组件,第一scrape用于数据采集,第二TSDB用于时序数据存储,第三ProQL数据查询,第四Server Discovery服务发现;
其中scrape是基于HTTP协议来实现的,这也就意味着每个待被抓取的指标,暴露服务必须是HTTP协议,在Prometheus当中,所有的数据抓取都是以pull模式抓取的,而且每一个生成指标数据的被采集段在Prometheus的语境当中被称作Target,这个Target指的实际上就是一个网络端点,一个IP+端口,如果对于HTTP协议而言,它还可能会有一个URL,而这个URL对于Prometheus而言,固定称谓为Metrics;
那么很显然,Target可能有很多个,而Metrics可能会更多,而它的抓取操作是根据Http call实现的,这就是为什么我们就不得不在被监控端安装一个expoter的原因;
Prometheus支持三种类型的途径从目标上“抓取(Scrape)”,第一种是Exporter,它就是一个HTTP的指标暴露器,第二Instrumentation这就是应用程序内建的测量系统,当然,还是通过HTTP协议暴露指标,第三pushgateway,无论是哪一种方式,对于Prometheus都是pull metrics;
Prometheus生态组件
Prometheus生态圈中包含了多个组件,其中部分组件可选;
Prometheus Server:收集和存储时间序列数据;
Client Library:客户端库,目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径;
Push Gateway:接收哪些通常由短期作业生成的指标数据的网关,并支持由Prometheus Server进行拉取操作;
Exporters:用于暴露现有应用程序或服务(不支持Instrumentation的)的指标给Prometheus Server;
AlterManager:从Prometheus Server接收到告警通知后,通过去重、分组、路由等预处理功能后以高效向用户完成告警信息发送;
Data Visualization:Prometheus WebUI;
Server Discovery:动态发现待监控的Target,从而完成监控配置的重要组件,在容器化环境尤为有用;
Prometheus数据模型
对于Prometheus而言,我们需要去以抓取的方式到每个Target上抓取可能不止一个时序数据,每一个指标纬度就会生成一个或多个时间序列,对于CPU这一个指标来讲,它可能就有多个指标纬度,比如定义一个指标为CPU_USAGE,但是对于CPU而言可能有多个纬度的使用率,比如内核空间的使用率,用户空间使用率,因此CPU_USAGE指标虽然是一个使用率指标,但它是一个统称指标,我们需要在他们背后附加很多标签,从而代表不同的序列,所以一个指标可能会生成N个时间序列,其实可以将一个指标想像成MySQL中的一个表,但这个表中有很多数据项,而标签则是where语句后面的过滤表达式;
Prometheus仅用于以“键值”形式存储时序式的聚合数据,它并不支持存储文本信息,其中“键”称之为Metrics,它通常意味着CPU的速率、内存使用率或者分区空闲比例等,同一个指标可能会适配到多个目标或设备,因而它使用“标签”作为元数据,使得Metric能够添加更多的信息描述纬度,这些标签还可以作为过滤器进行指标过滤及聚合运算;
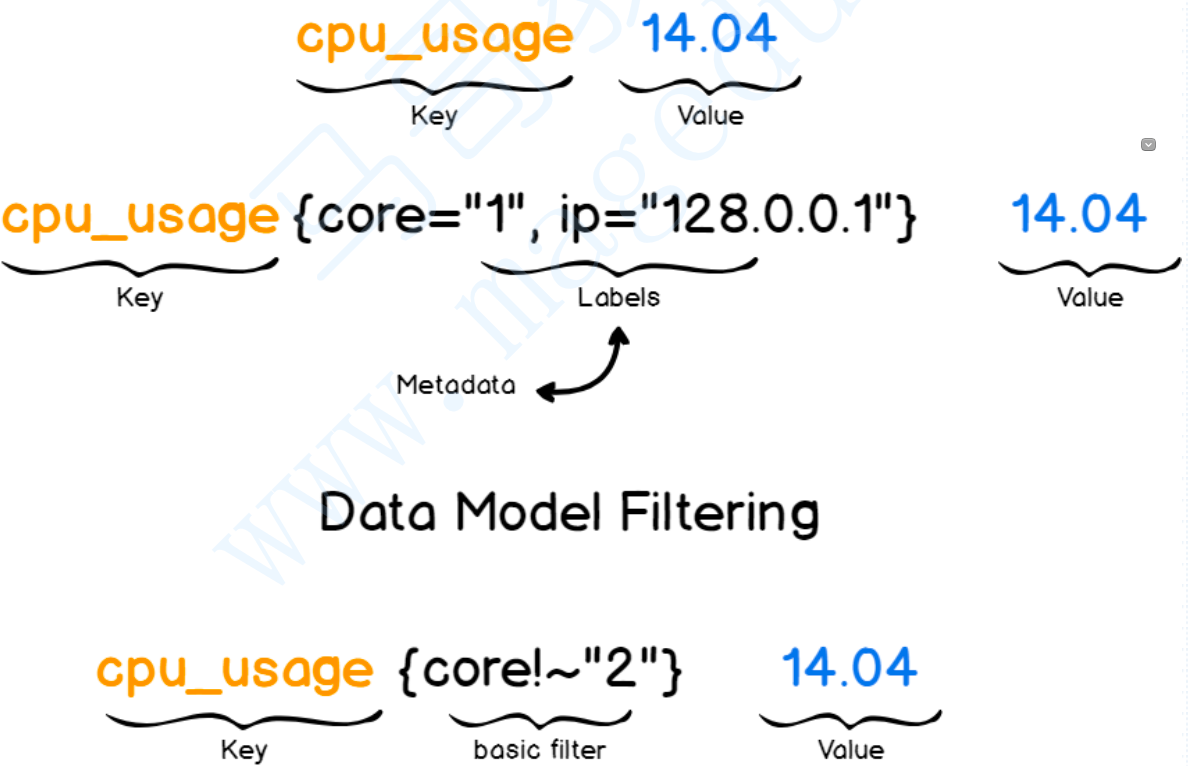
指标类型
在Prometheus当中,在存指标数据的时,指标也有类型的概念,指标类型不是数据类型,而数据类型都是以双精度浮点的,指标类型指的是,存储双精度浮点数据是以什么方式存储的,常见指标类型如下;
Counter:计数器,用于保存单调递增型的数据,第二次是数据是累加了第一次数据的结果,例如,站点访问次数等,它不能为负值,也不能减少,但可以重置为0;
Gauge:仪盘表,用于存储有起伏特征的指标数据,例如内存空闲大小等指标,同时Gauge是Counter的超集,但它存在指标数据丢失的可能性,Counter能让用户确切了解指标随时间的变化状态,而Gauge则可能随着时间流失而精准度越来越低;
Histogram:直方图,支持分位数统计,它会在一段时范围内对数据进行采样,并将其计入可配置的bucket之中,Histogram能存储更多的信息,包括样本值分布在每个bucket中的数量、所有样本值之和以及总的样本数量,从而Prometheus可以通过内置函数来计算样本平均值、计算样本分位值等;
Summary:摘要,Histogram的扩展类型,但它是直接由被检测端自行聚合计算出分位数,并将计算结果相应给Prometheus Server的样本采集请求,因而,其分位数计算是由监控段完成的;作业和实例
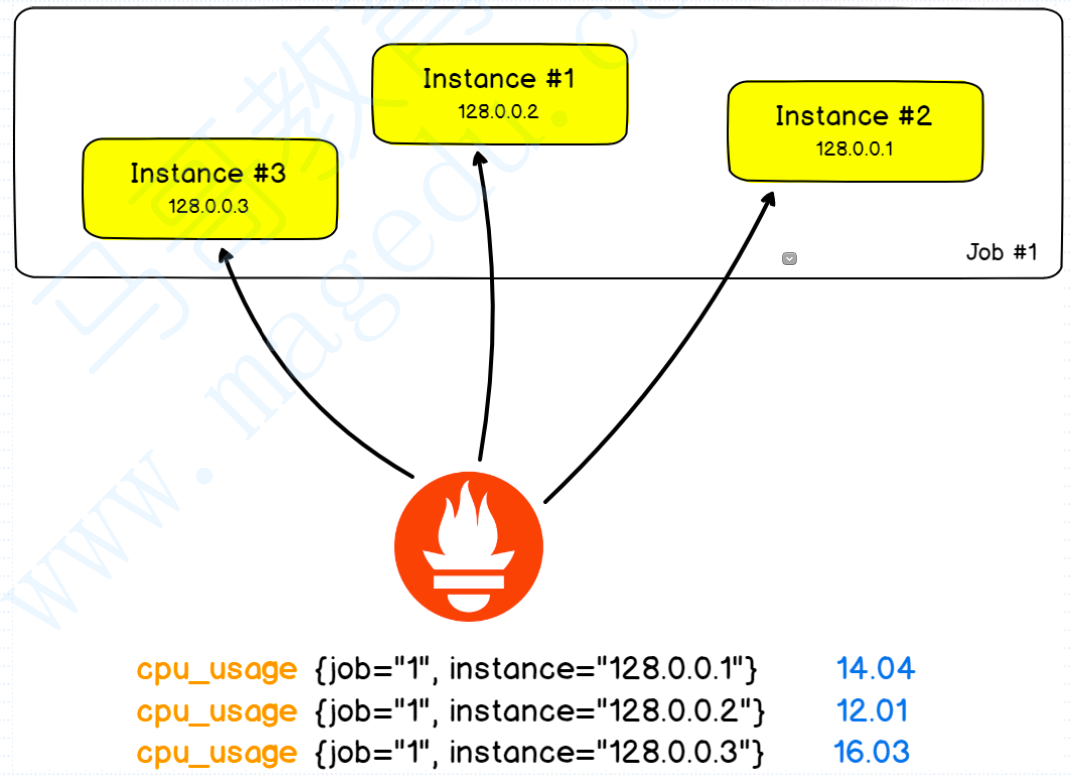
在Prometheus上,每一个能生成指标的Exporter或者Instrumentation都可以被独立识别为一个Target,比如我们有一个LInux系统,Linux系统是无法基于HTTP输出指标的,所以我们需要部署一个Exporter,所以Prometheus就需要基于这个Exporter的地址和端口来抓取数据了,像这种能够基于自己的地址和端口来暴露数据的采集点就叫做一个Target;
那这就很显然了,比如我们机房有100个主机,那100个主机都安装上Exporter,那他们都属于主机级的采集点,我们可以将同类型的采集点给它归类起来,统一进行管理,那这些具有同类型的采集点,在Prometheus里面就被称之为一个作业;
PromQL
对于Prometheus而言,它提供的内置数据查询语言,就叫做PromQL,支持用户进行实时针对Prometheus存储下来的数据做查询或者聚合操作,因而Prometheus会周期性的采集数据,每一个数据都会存下来,存的时候每个数据其实都是K/V型的数据,它的K就是它所属时间序列的标识,V就是样本值;
而后,我们想看某一个特定的时序样本值的时候,我们就需要基于这些K做过滤,整个K由指标名称和标签组成,于是我们可以针对指标名称做过滤,也可以针对标签做过滤,那么这个时候PromQL就是针对K所描述出来的查询表达条件,这个表达条件既可以基于K,做过滤,也可以基于标签做过滤;
因此我们对应的数据在其内部,所查询出来的结果,可能有多种数据类型,比如有常量,有向量,所谓向量就是带方向的数据,在PromQL有两种向量,第一是即时向量,第二种是时间范围向量;
Alter
对于Prometheus而言,告警分为两部分,第一Prometheus自己可以产生告警触发,但它只能触发,无法告警,它会将告警操作交给AlterManager,由于AlterManager真正去执行告警,而且告警时,可以根据故障的类别告知不同的告警接收人,这个时候我们就需要对告警谁知告警路由;
基础使用
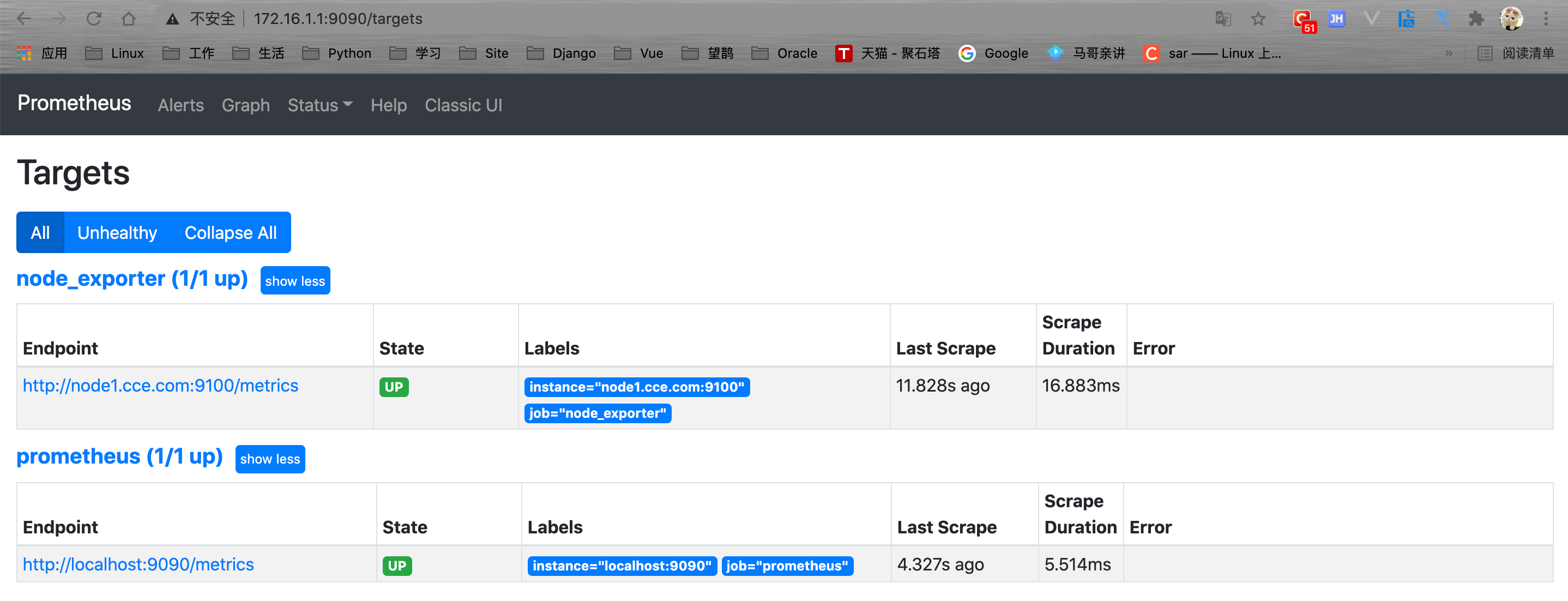
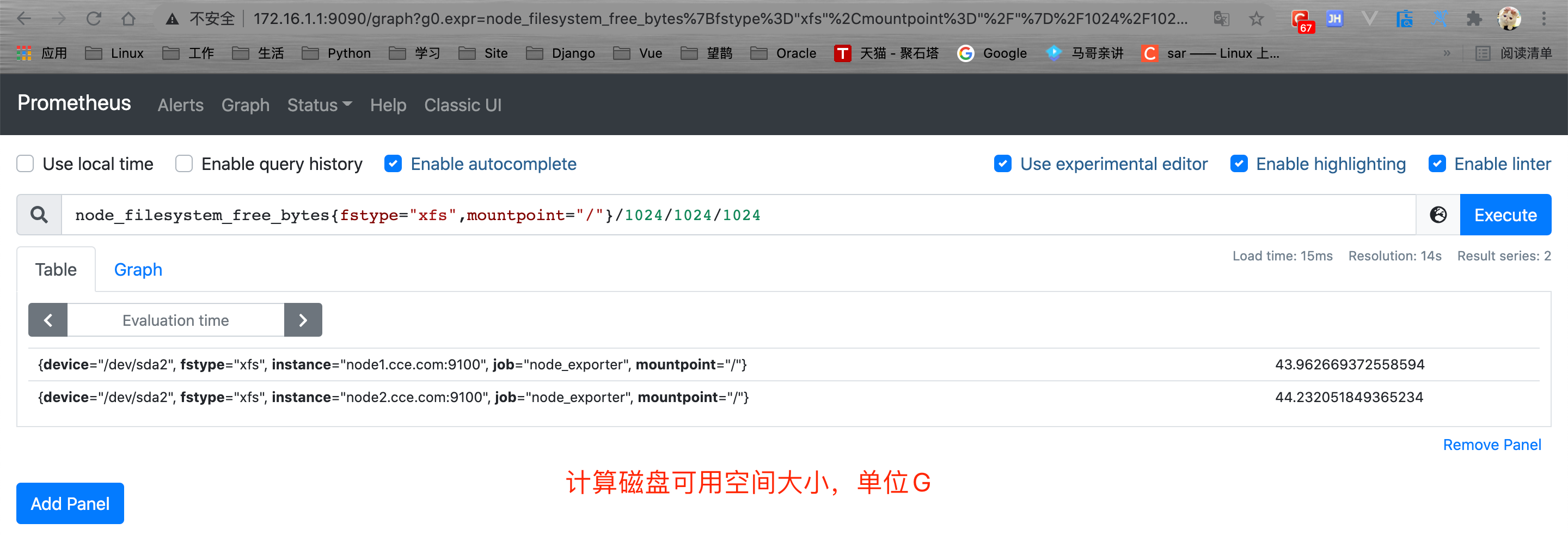
下面就简单的部署Prometheus结合Node_exporter来实现基础的系统监控,并通过Prometheus来查看当前系统可用的磁盘大小;
# 安装Prometheus
[root@node1 src]# tar xf prometheus-2.26.0.linux-amd64.tar.gz
[root@node1 src]# mv prometheus-2.26.0.linux-amd64 /usr/local/prometheus
[root@node1 ~]# ls /usr/local/prometheus
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
# 创建数据目录
[root@node1 ~]# mkdir -p /data/prometheus
# 给定启动脚本
[root@node1 ~]# cat > /usr/lib/systemd/system/prometheus.service << EOF
[Unit]
Description=Prometheus Server
After=network.target
[Service]
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.read-timeout=5m --web.max-connections=10 --storage.tsdb.retention=15d --storage.tsdb.path=/data/prometheus --query.max-concurrency=20 --query.timeout=2m
User=root
[Install]
WantedBy=multi-user.target
EOF
# 启动Prometheus
[root@node1 ~]# systemctl start prometheus.service
[root@node1 ~]# netstat -ntlp|grep 9090
tcp6 0 0 :::9090 :::* LISTEN 1815/prometheus
# 配置node_exporter
[root@node1 src]# tar xf node_exporter-1.1.2.linux-amd64.tar.gz
[root@node1 src]# mv node_exporter-1.1.2.linux-amd64 /usr/local/node_exporter
# 给定启动脚本
[root@node1 ~]# cat > /usr/lib/systemd/system/node_exporter.service << EOF
[Unit]
Description=Prometheus Node Exporter
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter \
--collector.mountstats \
--collector.systemd \
--collector.ntp \
--collector.tcpstat
ExecReload=/bin/kill -HUP \$MAINPID
TimeoutStopSec=20s
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
[root@node1 ~]# systemctl start node_exporter.service
# 配置prometheus
[root@node1 ~]# cat /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['node1.cce.com:9100']
# 重启Prometheus
[root@node1 ~]# systemctl restart prometheus.service