TOC
监控系统基础
对于运维工程师来讲,或者对于是对于技术运营为主要职业目标的岗位来说,相关岗位三大核心技能,主要包括,故障管理、变更管理和资源管理,其中故障管理,也是所谓的SRE当中一个非常重要的地方,因为SRE的全称叫做,站点可靠性工程师,从某种意义上来讲,它的主要核心职能之一主要就在于提前发现问题,甚至是能够基于某种趋势、数据或者某种服务的运行状态提前发现问题,而后将故障扼杀于萌芽之中;
当然,这其中也包括一些有针对性的,有目的性的设计来完成,因为站点可靠性工程师的最核心目标是评估站点的可靠性有多高,MTTR的概念,我们称之为平均无故障时间和平均修复时间,其实说白了就是我们要衡量一个站点的可靠性有多高,它应该是用平均无故障时间+平均修复时间的;
而平均修复时间要想能够降低,首先第一关键任务就是在第一时间能知道发生了问题,而后我们又能快速的定位问题,剩下的就是解决问题了,而能够让我们第一时间发现问题的最为重要的工具其实就是监控系统,因为我们不可能每时每刻不停的不间断的监视着我们系统运行的每一个角落;
那么这个时候,监控系统就出现了,它通过所谓或主动、或被动、或黑盒、或白盒等方式在我们系统上的多个位置通过下探针或者是加传感器的方式等,能够实现向外暴露自己内部运行状态的相关数据,从而能够被我们的统一的集中式的中央监控系统,把这些数据收集过来,加以分析存储展示等相关功能;
监控分类
我们系统复杂到可能有多个主机来支撑我们系统的运行,那么相对于主机级就有很多对应的资源使用状态或者消耗状态,我们需要知道,比如CPU、Memory、Disk等等,这些我们都需要知道,所以系统是我们要监控的第一要点;
但是系统彼此之间要想能够通信,那很显然,我们要监控的是网络,比如我们对应的应用程序要想访问后端DB服务的时候,那带宽或者说对应的网络流量是否已经达到满荷状态,还是说非常小,峰值的时期大概占用率有多高,所以第二个我们对应的主机之间通信的流量,我们也需要第一时间知道,很显然,这是最底层的基础设施上的监控;
如果我们要是使用了Kubernetes这样的平台的话,我们就可以借助于Kubernetes这样的一个容器编排平台更好的对上层应用进行监控,但是如果没有这样的容器编排平台,是我们基于传统方式进行管理的,除了上述提到主机和主机之间网络的监控指标之外,我们通常还应该监控,我们的业务,至少说,在业务之上,我们通常还应该监控我们的应用,比如说,我们的基础设施层的应用,如消息队列、数据库、负载均衡器等等,这些非常重要的基础设置我们得对每一个应用加以监控,因为我们需要了解这个应用本身的工作状态,以消息对列为例,我们的对列是否已经满了,等等等等,我们都应该知道;
同样的我们对应的除了基础设施类的应用之外,我们自己的业务应用也需要监控,假如我们支付系统、商品系统、库存系统等等,每一个对应的应用的业务指标是否正常,我们也需要知道;
监控手段
所以对于这么一个复杂的系统,有这么多的角角落落需要进行监控,那很显然,我们指望人工的去通过Top之类的命令来做监控,显然是不大现实的,所以这个时候,就有了各种各样的辅助监控方式,比如上述提到的黑盒监控,也可以通过探针的方式进行监控,这个探针指的实际就是不断的去刺探对应的服务工作状态是否正常;
比如我们通过一些被动的方式监控服务器的网络流量之类的,来抓去服务器流量当中,有多少正常报文有多少非正常报文,这是一种,还有一种方式是,我们可以在对应的系统上,给它安装一些对应的监控代理程序,来帮我们去采集一些对应的指标数据,或者对应的监控项,比如在主机之上,以主机为例,在操作系统上部署一个应用程序,这个程序不断的请求主机中内核中所暴露的各种太状态信息,比如,CPU的对列、内核空间占用比例、用户空间占用比例、中断占用比例、空闲比例等等;
而对内存而言,有内存对总空间大小、正常的使用空间大小、Buffer的空间大小、Share的空间大小,空闲空间大小等等,我们也需要进行空间,这些就是这个对应的监控代理程序不断的通过内核提供的接口,去获取相关的数据来解决的;
但是还是那句话,即便我们在主机级安装了一个所谓的监控代理程序,但是它也未必能够监控我们所谓的应用程序,所以,应用程序自己尤其是现代开发的应用程序,他们通常就自带了能够暴露自己运行状态的接口,如果没有暴露的话,那么这个时候我们职能使用黑盒的方式从外部使用所谓的探针进行监控,或者我们在外部加一个专门的代理去抽取对应的应用程序的指标数据;
拿Redis为例,Redis所提供的redis info这样的接口暴露了当前Redis所有的指标接口,那像这种我们也可以借助于一个专门的应用程序将这些数据周期性的读出来,然后兼容到我们对应到监控系统上去也是可以的;
监控系统
当我们在系统上安装了各种各样的探针,那么随后我们就应该将这些探针所抓去的数据将他们收集到一个统一的位置进行统一分析,统一存储,这样子我们随后将他们作为我们的运维工具使用才更加的便捷,通常情况下,我们就应该在我们整体的核心系统外部,部署一个所谓的监控系统程序,而上述说到的这些技术手段,主要就是让我们的监控服务器,与之进行通信,并获取到对应系统之上的某个特定测量纬度,向上述所提到的,CPU空闲比例,CPU消耗在内核当中的比例,这些都是测量纬度,我们期望知道它在哪个属性上,到底有什么样的状态变动,而每一个测量纬度,我们通常称之为一个指标(Metric);
而我们对应的监控系统就要对每一个系统之上的指标进行采集,而后将采集到到数据纳入到当前监控系统之中,而后用用户所需要的方式提供给用户,我们要想第一时间知道我们的系统是否发生故障了、是否异常了、是否超出阈值了等等,那么很显然,我们需要持续的监控着被监控对象才行,持续得去获取对方之上特定指标数据,才可以;
而这个持续,它不是我们理解的这种连续性的,它实际上是一种离散性的持续,离散性持续就是周期性的去采集数据,这里的采集其实可能有两种方式,第一,正常情况下应该有哪些监控系统上的哪些被监控指标,我们就需要在我们的监控系统上指明要监控哪个主机,这一个主机叫做一个监控对象,但是在这个对象上可能有很多很多的指标需要采集,一个主机并非一个指标,而且更何况一个主机之上除了系统级指标之外,很有可能还有基础设施类的应用指标,业务类应用指标等;
这些每一个指标我们都得采集,所以每一个主机之上,都有可能多达上百个指标,甚至更多,而这种在一个较大规模的系统当中,很显然,指标数量多大上万是很正常的,而这种周期性的采集,就意味着需要针对这多达上万个甚至是数万个数十万个指标要不停的按照固定的频率进行采集;
时序数据库
当指标采集到我们的监控系统之后,如果用户不看,那么数据就消失了,因此,为了能够让用户对这些曾经采集到的数据在这个采集点时间过后再查看,那我们应该将采集的每一个指标的每一个时间点的数据,我们称之为样本数据,都要给它存储下来,才能确保采集时间点过去之后还能看的效果;
所以这些样本数据,我们还必须把它存储下来才可以,那么这个时候我们通常需要一个存储系统,而且需要注意的是,这儿的数据我们要针对数据指标来讲,它的数据一定是按照时间顺序生成了很多数据,这样的数据,我们通常称之为时间序列数据(TSDATA);
通常这种数据它的存储格式一般都是类似追加的方式来进行数据存储,所以这种存储时序数据的专门的高性能存储系统,就被称之为TSDB,即时间序列数据库,它也是NoSQL系统中的一类,他们都是非关系型数据库;
当然,这儿我们使用关系型数据库也可以,只不过对于关系型数据库的每一次写入,都是有很高的系统性能开销的,比如我们要查逐渐冲突、唯一键冲突之类的,因而对于较大规模的系统来讲,如果使用关系型数据库存监控数据库的话,很快对应的后端存储系统就会成为系统平静瓶颈;
像Zabbix就是使用关系型数据库来存储数据的,所以Zabbix在遇到系统规模到一定的时候一定会遇到各种各样的问题,我们必须得对后段数据库系统做性能优化或者进行各种优化措施才能解决相关问题的;
对于Zabbix来讲,它出现的时间还是很早的,曾经一度也是市面上主流的监控系统,但是随着业务规模的发展,它已经显得有点那么一点不合时宜了,但是对应的系统规模没有到那么大的规模场景当中,Zabbix依然是很好的选择,因为无论是文档、还是成熟度,甚至是稳定性,Zabbix既然是无可比拟的;
现在设计的监控系统,基本上他们的数据样本存储,都使用了TSDB的方式来存放,虽然Zabbix使用来MySQL,有点落后显得不合时宜,但更早的监控系统,如Cacti,而Cacti使用的rrd的一个数据库来完成的,rrd其实到今天为止,不能说不合时宜,只不过它的存储逻辑可能也确实不是那么好用了,另外在Cacti时代的的一个监控工具同样的还有Nagois,这些曾经一度能与Zabbix争锋的系统,但是Zabbix以它所谓的功能完备、系统稳定、解决方案统一以致于成为非常非常主流的监控系统;
但是,当应用发展到以分布式为核心特性,甚至是以微服务为主导的现代应用架构下的时候,Zabbix无论是对于动态的监控模式的支持不是特别理想,还有它采用传统的关系型数据库作为后端存储,都已经成为了一个弊端了;
样本
监控系统要将每一个对应的指标数据,都周期性的采集过来,而这些数据副本我们要存下来才能在过后被我们的系统管理人员所分析和利用,而这些数据我们就称之为历史数据,因为他们是过去采集的历史样本;
聚合
多数情况下,对于单个指标来讲,我们采集的数据它对我们对意义和作用不大,比如说,我们采集出来我们CPU在内核空间的使用比例,单单仅仅这一个指标,通常来讲,它的可参考价值真的不是特别大,单个指标的参考价值,一般不会特别大;
这个就意味着,我们需要将这单个指标的历史数据给它聚合起来,做统一分析,才能发现其中内在的问题,但是传统的聚合方式对于监控系统可能并不一定能够让我们真正发现潜在问题所在,也可能被误导,我们监控在一个时间序列上采集了很多很多相关的数据,然后想知道平均的趋势大概有多大,以为我们的系统没有问题,但是事实上,很有可能出现异常值存储,只不过这个异常值被平均下来了,就类似人均收入一样,虽然说上海人均收入1万,但是依然有很多人哪些7千以下的工资;
所以在聚合上,我们就应该有方差、标准差、中位数、百分位数等等等等,来进行做辅助分析,这样子才能更好的去揭示,我们对应的系统是否存在问题,如果没有这样的聚合分析的话,我们想去找到实际的问题所在可能是个不太实际的问题;
所以聚合对于监控系统来讲是一个至关重要的操作,那也就意味着我们的数据存下来,不光要存历史数据,还要存趋势数据,所谓趋势数据就是经过聚合分析之后的数据,这个聚合分析就是在原来的数据样本之上,我们还有额外存储一些数据,存储的就是聚合分析的结果;
展示系统
虽然我们有各种各样的指标数据、趋势数据,作为系统管理人员来讲,看着那一堆的数据恐怕也没什么太大的分析价值,因而,我们通常还应该有非常直观和漂亮的展示系统;
比如使用柱状图的形式来展示趋势,或者说用线妆图的形式来展示波动等等,很显然,比我们直接看数值直观多了,因而,我们还需要在我们的监控系统之上提供一个很好的展示接口;
预警系统
但即便如此,就算有一个很漂亮的展示接口,我们也需要用户看才能知道问题所在,如果我们正在家里休息,对应的服务突然大规模长时间的异常,所以对应的,我们还需要对周期性的监控下来的数据进行特定的判定;
比如我们使用一个布尔表达式,来判定对应的监控指标,每个采样点的数据,是否超过来阈值,一旦进入异常阶段,当然,一进入异常就通知用户,也没有这个必要,因而,为了避免这种误报的可能性,报警系统应该有一个状态值;
比如,当突然一个对应的指标本来是正常的,突然间出现异常了,超出阈值很多,那么这个时候,我们可能会认为系统可能出现故障了,但这个状态变化,叫做软状态,我们一般不应该第一时间就开始通知用户的;
我们应该是等这个值,持续一段时间依然一直居高不下,一直超出阈值,那么这个时候,我们这个时候就应该将软状态变成硬状态,然后通知用户,而这种通知,我们通常叫做告警;
说白了就是发生通知信息给用户,在Zabbix里面,它还设计了一些高级的玩法,比如这个告警信息,发送一个小时之后依然没能得到解决,那就升级发送,发送给领导,过了一个小时候还没解决就再升级,就发送给公司的领导了,因为它可能会认为这个影响面越来越大,级别越来越高,必须引起更多的人注意才行,我们称之为告警升级;
总结
大体上一个监控系统的主要组成部分主要有几个,第一,采集,被监控端要有监控代理/数据接口,监控代理也罢,数据接口也罢,它也未必能够应用所有场景,所以也可能有所谓的探针监控还有黑盒监控;
对于传统对网络设备来讲,比如要监控一个交换机,要监控交换机很难在交换机里面安装一个应用程序,它恐怕自己也未必能使用什么高级的方式向外暴露接口,而用的都是所谓的SNMP,简单网络管理协议,这是一个非常传统的,在七八十年代,让我们能够监控网络设备内部的工作状态的相关的接口,大多数网络设备都有,到今天来看,显得很粗陋,但是它也确实是这些网络上不可多得的接口,毕竟很多的网络是把更多的资源拿来去实现数据报文 处理的,而不应该拿来去做这些应用方面的操作,所以这个时候可能我们需要使用所谓的SNMP的这种机制去完成数据采集的,等等;
第二,存储,我们的指标数据还需要存储,存储可能里面还需要一个分析引擎,可能还需要自带上一些很多聚合函数,甚至是一些趋势分析函数,做一些简单的线性回归分析,做一些预测等等,对于存储有的用SQL存,比较有代表性的,如Zabbix所使用的,MySQL,有的使用NoSQL存,而NoSQL当中比较流行的就是时序数据库,可以查看db-engines.com,查看主流数据库排名情况,其实Prometheus本身是一种时序存储和系统,只不过这个时序存储系统有一个数据抓去器;
第三,展示,展示通常就是用非常直观的数据展示面板来帮我们展示像柱状图、雷达图、线状图,像Zabiix内建了有Zabbix的Web,像Prometheus内建了PromQL表达式,只不过它内建的图形非常的丑陋,因为市面上有专门的对接这种数据存储系统的展示工具,比如Grafana,它可以把Prometheus作为数据源来进行展示,它无非就是利用Prometheus内置的数据查询和分析接口,来查询、聚合之后来进行展示的,Grafana也可以把Zabbix作为它的数据源,其实Grafana支持的数据源有数十种之多;
第四,告警,它无非就是把对应的指标数据的异常状态,而且是持续异常状态反馈给用户,就叫做告警,其实就是一种通知机制,所以我们需要有很多的媒介来进行通知,这里的媒介包括,能够触达到用户的联系方式都可以,比如邮箱、叮叮、微信、短信等等;
常见的开源实现
在很早之前传统的监控系统都是使用的Cacti,它是一个很好的数据抓取和存储工具,它还使用了RRD来存储,只不过它的报警功能非常的微弱,以致于后面它不得不与Nagios进行结合,而且Cacti的数据抓取操作,还不得不借助于Linux的Crontab来实现,这个实在不是很高明;
但是,在上一个十年,也就上0几年的时候确实,还是非常主流的,因为那个时候Zabbix还没有成熟起来,而Zabbix成熟起来之后,迅速的Cacti和Nagios就落寞了,现在恐怕用得人已经不多了,不过到今天为止,Zabbix虽然起来了,但是Zabbix可能依然无法取代Nagios的强大报警能力,这个确实是Nagios一个非常大的特性;
而新时代的监控工具,Prometheus,它就是为分布式、微服务而生的,而且它已经在CNCF旗下,作为一款云原生项目,并且它也有非常好的服务发现能力,能动态纳入各个被监控的对象,而无需你需要一个一个手动的去配置,这比起Zabbix可方便多了;
虽然Zabbix到今天为止也能支持服务发现这种机制,但是使用起来是非常难受的,所以说,真正的云原生的监控,Zabbix已经不适配了,当然,也有很多人在它的分布式系统当中,也有人使用国人开发的这种监控系统,也非常不错,只不过国人开发的监控系统,如果开源的话,他们多数都是那个人为了在这个公司作出业绩来,为了使得自己的KPI更好看而开发的,很有可能离开了这个公司,就不再维护了,比如像著名的OpenFaIcon,这是小米的,只不过到今天,这个项目到创始人已经到滴滴去了,还有一个夜莺、美团点评的CAT;
Prometheus
接下来,就开始正式进入主题,以Prometheus为例,阐述监控系统的采集、存储、展示以及报警等功能的实现,以及如何将它对接到现代比较主流的容器编排系统Kubernetes上,来监控我们的Kubernetes系统;
其实Prometheus的创始者,是Google出来的一个员工,但他后来到SoundCloud工作了,当他就职SoundCloud之后模仿Google的监控BorgMon,也就是Borg的监控系统(Kubernetes的前身),开发了Prometheus监控系统,所以说Prometheus更加适用于Kubernetes的,因为它从设计上,就有了这样的考虑,其实Prometheus到今天为止已经出现很多年了,2012年就开始研发了,只不过2015年才发布出来,2016年五月份,加入了CNCF,所以它也是云原生基金会的产品之一,差不多在2016年6月份发布1.0版,到今为止已经达到2.x系列;
Prometheus本身它有几个比较显著的特点,才使得其这么流行如当下,第一,它的时间序列数据,通常都是统统称之为Metric;
第二,Prometheus数据格式,Prometheus格式对于指标数据的格式也有了自己的定义,有了自己独创的指标格式,我们称其为Prometheus格式,Prometheus格式到今天已经是非常非常流行了,以致于大量的开发的新的程序,或者传统程序在版本迭代时,都会内置一些监控指标,这种指标的格式就是Prometheus格式的Metric;
第三,多纬度的标签,它这个Metric有一个非常大的特点,就是支持多纬度的标签,而且每个独立的标签组合,都代表一个独立的时间序列的样本数据,它的数据模型非常的随意,不想SqlServer或者像MySQL这样的,事先定义好表结构,而Prometheus在一个对应的指标上,添加一个标签,并且标签增删随意;
第四,数据处理,Prometheus也可以对我们的时序数据做聚合、切割、切片,它内置了这种各种高级操作机制;
第五,并且它还支持双精度浮点型数据,因此Prometheus所能表达的数据的能力更加的但是,它也有缺点,Prometheus所存储的样本数据都是双精度浮点型数据,所以它就不能存储文本,所以它没办法去采集日志然后给它存储下来,Zabbix是可以存日志的;
Prometheus工作原理
Prometheus是一款时序数据库,它自己就直接带了存储引擎,它又带了数据抓取器,而且它把数据抓取过来之后就把数据存储在自己内建的时序数据库当中,但是它的功能并非止步于时序存储,而是专门用于实现目标监控的一个关键组件,因为它带有采集器,而且这个采集器有很灵活、高效的可配置能力;
因而,从某种意义上来讲,它的监控能力才是根本,时序存储反倒是为了监控的存储而特别设计的,但话又说出来,它但时序存储默认保存数据的时长是有限的,默认是一个月,如果我们要想保存更长时期的历史数据,使用它内建的时序数据库就不行了,我们需要对接远程存储系统,比如InfluxDB或者OpenTSDB都可以,很多人都在使用InfluxDB这样都存储系统,我们可以对接到Prometheus上,让它作为Prometheus长期存储监控数据的存储后端;
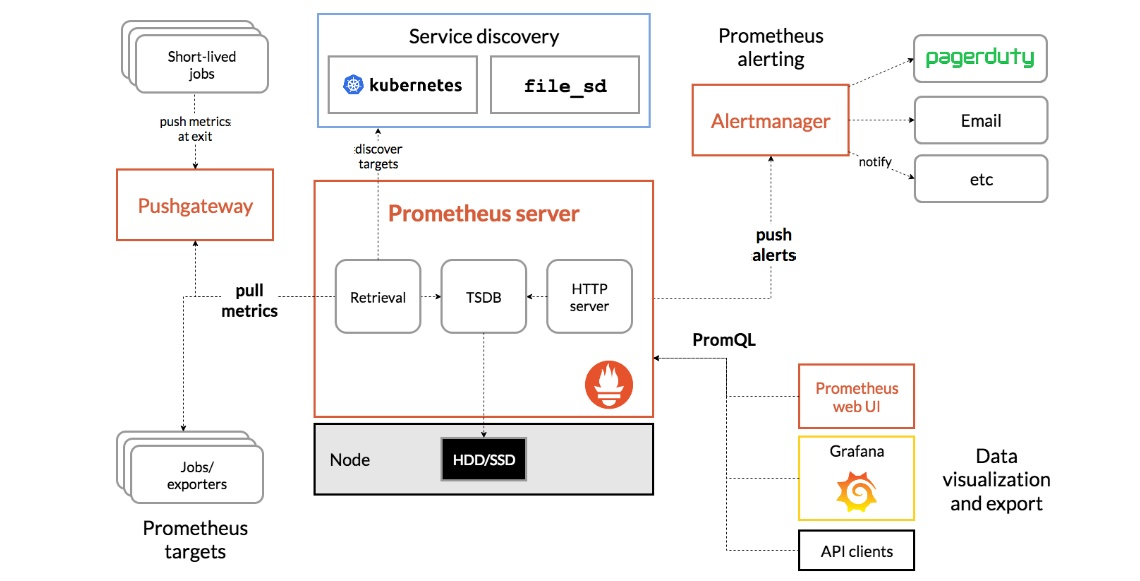
Prometheus内建插件支持多种存储系统,所以说,Prometheus要想能够完整的工作起来,并且长期存储数据,需要对接的生态组件非常的多,除了上述的外部存储之外还包括很多组件,比如PushGateway、AlterManager和Grafana等,就可构成一个完整意义上的IT监控系统;
主要原因是因为,Prometheus如果我们完整的称呼它的话,它被称为Prometheus Server,它自己内置了存储能力,又内置了数据采集器,而且它的采集是工作于Pull模式的;
数据采集模型
数据采集模型一般有两种,第一种是pull一种是push,就是拉和推的概念,但无论是pull还是push,都是针对监控系统来讲的,pull的意思就是由监控系统自己主动的联系被监控端,把数据取回来,这就是pull的概念;
而push则是被监控端,主动联系监控系统,提交自己的指标数据,就是由被监控段把数据推给我们的Prometheus Server,所以从Prometheus Server来讲,push就是等待接受数据,这也就是push的概念;
Prometheus工作于,pull模式,仅支持pull模式,对于pull而言,无论监控谁,我们必须实现在Prometheus Server上定义出来,不定义出来它一定不会去拉取的,还有,任何一次数据采集都得有Prometheus Server自己主动去采集,所以对Prometheus Server的压力比较大,因而他们各有优劣;
因为Prometheus也支持pull模式,所以Prometheus如果要实现push的话,就不得不借助于另外一个系统,来帮忙接收别人push的数据,这个组件就是PushGateway,而我们的Prometheus Server定时去像PushGateway去pull数据,这样我们的Prometheus Server就不直接到被监控端去拉去数据了,直接在PushGateway端拉取数据即可,仍然g工作与拉取模式;
并且Prometheus Server内建有一个非常强大的查询接口,就像MySQL的SQL引擎一样,可以使用SQL语句就能完成数据处理了,Prometheus这个内建的查询引擎同样提供了一个类SQL语句一样的接口,只不过它不叫SQL,而是PromQL,我们要给它传递就的Prometheus的查询表达式,这也是Prometheus的最主要的核心功能之一;
当然,还有一个非常重要的组件,Prometheus自己能够出发报警,但是它不会发送报警,比如我们使用PromQL的布尔表达判定一下,判定这个数据是否符合我们的期望,如果不符合,我们采取什么措施,所以Prometheus还得再对接一个组件,即AlterManager,它就是一个查询报警器,它就是根据PromQL定义的查询表达式实现告警的;
比如说,只要我们定义了监控规则,如果这个监控规则触发了,需要报警的时候,那么它就会送给AlterManager,由AlterManager借助于邮件、微信、叮叮等发送告警给用户,所以说Prometheus由两部分组成,Prometheus Server只是产生告警,真正告警发送说由我们AlterManager实现的;
还有一个组件,即,Exporter,因为有很多的应用没有自带指标接口,我们又得监控,比如像MySQL,我们如果要想使用Prometheus监控MySQL,但是MySQL自己又没有内建Prometheus的指标接口,所以这个时候我们就需要借助于代理实现,让代理去抓取这个数据,抓取出来之后,转换成Prometheus能够兼容的格式,这些我们就称之为指标暴露器,即Exporter,它能够查询MySQL的指标数据,然后由它来将指标暴露给Prometheus Server,所以Prometheus去监控MySQL的时候不是直接去找MySQL的,而是直接去找这个MySQL的Exporter;
市面上有很多的应用程序是都没有自带这些指标接口的,所以我们就不得不给它对接一个指标暴露器,而指标暴露器都是一对一的,比如我们有四个MySQL需要监控,那么一个指标暴露器只能对接一个MySQL,所以从某种意义上来讲我们可以理解这个Exporter为指标抓取代理器,Prometheus有很多指标暴露器,同时我们也自己开发一个指标暴露器,几行代码就能做到;