4、Django框架四
条件查询
与条件查询
方式三
方式四
或条件查询
非条件查询
聚合查询
分组查询
去重
关联结构
多对一
创建测试数据
增加操作
删除操作
修改操作
正反查询
正向查询操作
反向查询操作
一对一
一对一扩展
增删改数据
查询数据
ForeignKey方式
OneToOneField方式
多对多
ForeignKey方式
增删改查
ManyToManyField
ManyToManyField全自动
ManyToManyField半自动
增删改查
跨表引用
扩展
事物
与条件查询
方式三
方式四
或条件查询
非条件查询
聚合查询
分组查询
去重
关联结构
多对一
创建测试数据
增加操作
删除操作
修改操作
正反查询
正向查询操作
反向查询操作
一对一
一对一扩展
增删改数据
查询数据
ForeignKey方式
OneToOneField方式
多对多
ForeignKey方式
增删改查
ManyToManyField
ManyToManyField全自动
ManyToManyField半自动
增删改查
跨表引用
扩展
事物
条件查询
在日常的数据库开发中,条件查询用得非常之多,比如常见的SQL查询过程中用到的与(and)、或(or)、非(not),这种在where语句后面实现多条件查询的场景极其频繁,那么对于Django的ORM框架来讲,实现过滤查询的主要途径之一就是filter方法,但是我们经过测试,我们会发现,我们的filter函数,仅支持一个表达式,并不支持多个表达式联合,当然,这也有解决方法;
与条件查询
与条件查询,即AND查询,如果我们期望在filter函数内部使用AND这种多条件并行成立的查询语句,主要有五种,其实它们本质没有任何区别,生产的SQL语句是一摸一样的,可以说没有好坏之分,如何选择,看个人习惯;
# 方式一
print(Users.objects.filter(id__gt=1, name__contains="c")) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 方式二
print(Users.objects.filter(id__gt=1).filter(name__contains="c")) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 方式三
print(Users.objects.filter(id__gt=1) & Users.objects.filter(name__contains="c")) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 方式四
from django.db.models import Q
print(Users.objects.filter(Q(id__gt=1), Q(name__contains="c"))) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 方式五
from django.db.models import Q
print(Users.objects.filter(Q(id__gt=1) & Q(name__contains="c"))) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>方式三
可以看到方式三,它有点特殊,它是使用"&"符合联合两个filter查询对象来实现的,它是利用运算符重载的方式实现的,对结果集对运算符进行了重载;
但是实际上,它并不会将前面的查询集拿到,再拿到后面的查询集然后进行重载,它是将两个查询集在正式生成查询SQL之前,将两个查询集做and处理,然后生成一条SQL语句发往数据库进行查询;
print(Users.objects.filter(id__gt=1) & Users.objects.filter(name__contains="c")) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 生成的SQL:SELECT `users`.`id`, `users`.`name`, `users`.`age`, `users`.`gender`, `users`.`brith_date` FROM `users` WHERE (`users`.`id` > 1 AND `users`.`name` LIKE BINARY '%c%') ORDER BY `users`.`id` ASC LIMIT 21方式四
方式四和方式五本质没什么差别,它采用了一个Q对象,这个Q对象,就可以用来帮助我们来实现与(and)、或(or)、非(not)等条件的实现,它的内部原理其实和方式三是一样的,只不过它是将两个查询条件进行合并;
print(Users.objects.filter(Q(id__gt=1) & Q(name__contains="c"))) # <QuerySet [<Users: 2 cfj>, <Users: 4 csw>]>
# 生成的SQL语句:SELECT `users`.`id`, `users`.`name`, `users`.`age`, `users`.`gender`, `users`.`brith_date` FROM `users` WHERE (`users`.`id` > 1 AND `users`.`name` LIKE BINARY '%c%') ORDER BY `users`.`id` ASC LIMIT 21或条件查询
或条件查询,即OR查询,对于或条件查询,也有多种选择,主要有三种,一种是用in来完成,第二种和第三种都是使用或条件运算符来实现的,如下;
# 方式一
print(Users.objects.filter(id__in=[1, 2])) # <QuerySet [<Users: 1 cce>, <Users: 2 cfj>]>
# 方式二
print(Users.objects.filter(id=1) | Users.objects.filter(id=2)) # <QuerySet [<Users: 1 cce>, <Users: 2 cfj>]>
# 方式三
print(Users.objects.filter(Q(id=1) | Q(id=2))) # <QuerySet [<Users: 1 cce>, <Users: 2 cfj>]>非条件查询
非条件查询,即NOT查询,非条件查询主要使用Q对象来实现,Q对象支持使用"~"取反运算符来实现取反操作,如下;
# 单条件取反
print(Users.objects.filter(~Q(id__in=[1, 2, 3]))) # <QuerySet [<Users: 3 yml>, <Users: 4 csw>]>
# # 多条件取反一
print(Users.objects.filter(~Q(id__gt=1) | ~Q(id__lte=3))) # <QuerySet [<Users: 1 cce>, <Users: 4 csw>]>
# 多条件取反二
print(Users.objects.filter(~(Q(id__gt=1) & Q(id__lte=3)))) # <QuerySet [<Users: 1 cce>, <Users: 4 csw>]>聚合查询
到现在,我们通过结果集方法、Lockup表达式和条件查询,已经可以实现非常复杂的查询了,那么接下来就是我们在日常开发中常见的聚合查询,聚合查询属于SQL中的高等级查询,那么在Django的ORM框架中,也提供了相关支持,在Django的ORM中聚合主要是使用结果集的aggregate方法来实现的;
语法结构:结果集.aggregate(别名 = 聚合函数("聚合字段名")) 在aggregate方法中,我们可以传入聚合函数,进行聚合查询,主要有常见聚合函数有,最大、最小、求和及总数几项,它们均在from django.db.models模块下,如下示例;
from django.db.models import Max, Min, Avg, Sum, Count
# 求总数
print(Users.objects.all().aggregate(Count('name'))) # {'name__count': 4}
# 求平均值
print(Users.objects.all().aggregate(Avg('age'))) # {'age__avg': 28.0}
# 求和
print(Users.objects.all().aggregate(Sum('age'))) # {'age__sum': 112}
# 求最大值
print(Users.objects.all().aggregate(Max('age'))) # {'age__max': 48}
# 求最小值
print(Users.objects.all().aggregate(Min('age'))) # {'age__min': 14}
# 聚合合并
print(Users.objects.all().aggregate(Sum('age'), Avg('age'))) # {'age__sum': 112, 'age__avg': 28.0}
# 取别名
print(Users.objects.all().aggregate(sum=Sum('age'), avg=Avg('age'))) # {'sum': 112, 'avg': 28.0}分组查询
Django当中的ORM框架分组主要是通过annotate函数来实现的,对于SQL的分组需要搭配聚合函数来实现,annotate函数也一样,需要搭配聚合函数来实现,但是annotate和aggregate不同的,aggregate的返回结果是一个字典,而annotate则返回一个QuerySet查询集,查询集里面的元素是对象,这个对象就是数据库中查询的结果,返回后由ORM模型类创建出的对象。语法如下;
语法结构:结果集.values("分组字段").annotate(聚合函数("聚合字段名")) 使用annotate进行分组,需要搭配values方法来实现,values方法主要用来指定分组的字段名,需要注意的是,values方法必须在annotate方法之前,如下示例;
print(Users.objects.values('gender').annotate(count=Count('gender')))
# <QuerySet [{'count': 2, 'gender': 1}, {'count': 2, 'gender': 0}]> 有时候,我们会发现,分组失效了,语法没问题,但是得到的分组结果不对,这主要是因为,我们在模型类中,指定了ordering元属性,默认的排序字段,这个字段会影响分组,如下;
# modles.py模型类
class Users(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(null=False, max_length=14)
age = models.IntegerField(null=False)
gender = models.SmallIntegerField(null=False)
brith_date = models.DateField(null=False)
class Meta():
db_table = "users"
ordering = ['id'] # 影响分组的,排序字段
def __repr__(self):
return "<Users: %s %s>" % (self.id, self.name)
# orm.py测试文件
print(Users.objects.values('gender').annotate(count=Count('gender')))
# <QuerySet [{'gender': 1, 'count': 1}, {'gender': 0, 'count': 1}, {'gender': 0, 'count': 1}, {'gender': 1, 'count': 1}]> 出现这样的问题,主要是因为当我们在元属性里面指定了ordering属性之后,在进行分组时,默认会使用ordering指定的字段名进行分组,所以尽量少使用ordering属性,或者在annotate方法之后,加入order_by方法,忽略ordering属性里面的所有字段;
# 加入order_by方法
print(Users.objects.values('gender').annotate(count=Count('gender')).order_by())
# <QuerySet [{'gender': 1, 'count': 2}, {'gender': 0, 'count': 2}]>去重
对于Django框架的ORM来讲,它也提供了去重的手段,主要采用结果集的distinct方法来实现,但是需要注意的是,如果我们需要指定去重字段,那么就需要在distinct方法前面新增一个values或者values_list方法来指定去重字段;
我们通过源码可以看到,distinct方法内部支持一个field_names参数来指定去重字段,但是我们需要知道的是这种方式只支持PostgreSQL数据库,其他类型的数据库均不支持;
# 模型类
class Users(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14)
class Meta():
db_table = "users"
def __str__(self):
return "<Users: %s>" % (self.name)
# 插入测试数据
Users.objects.create(name="cce")
Users.objects.create(name="csw")
Users.objects.create(name="cce")
# 未去重
print(Users.objects.all().values('name')) # <QuerySet [{'name': 'cce'}, {'name': 'csw'}, {'name': 'cce'}]>
# 已去重
print(Users.objects.all().values('name').distinct()) # <QuerySet [{'name': 'cce'}, {'name': 'csw'}]>关联结构
前面上述的都是单表操作,而对于Django的ORM框架来讲,多表查询只支持三种方式,即一对一、多对一和多对多三种方式,它不支持SqlAchemy那种两表连接查询,不定义外健两表是不支持多表连接查询的,所以一对一、多对一和多对多都是通过外健来实现的;
对于一对一来讲,其实很简单,比如一个身份证只能对应一个人,并且一个人也只能有一个身份证,这就是一对一的关系,在Django的ORM中创建就需要用到一对一的关系模型,而多对一来讲,比如一个家庭可以有多个人,但是这多个人都属于同一个家庭,这就是所谓的多对一关系,而多对多,也非常简单,比如一个学生可以报多门课程,而每门课程又可以有多个学生;
这些所谓的关系模型,在Django的ORM框架中都是通过外键来实现的,那么在Django的ORM框架中,外键的建立主要是通过django.db.models模块下提供了ForeignKey类来定义,它将两个表建立外键关系,形成关联;
那么根据关系模型的种类多样,以及外键的相关配置,ForeignKey类也提供多个参数可供设置,他们主要是用来描述外键关系的建立,如下;
to:设置要关联的表;
to_field:关联到需要关联对象的字段名称,默认情况下,会使用关联对象的主键作为关联字段;
db_constraint:只有在db_constraint=True时才会在数据库上建立外键约束, 在该值为False时不建立约束,默认为True;
related_name:该参数值为一个字符串,它的主要作用是,在进行反向查询时所使用的名称,所谓反向就是,在一的一方向多的一方查找;
on_delete:及联操作,表示当主表中的关联字段(被外键关联的字段)的数据被删除时,子表对应的关联数据行执行的处理操作,主要有如下几种;
models.CASCADE:关联删除,表示主表中的数据被删除时,子表关联的数据会一起删除;
models.PROTECT:阻止删除,如果主表的某条记录被子表关联,那么主表这条记录不允许删除,这是MySQL中的默认策略;
models.SET_NULL:置空处理,表示主表中的数据被删除时,子表关联的字段,是"子表关联的字段,并非子表关联的整条记录",会设成null,所以子表必须设置blank=True;
models.SET_DEFAULT:删除关联数据,与之关联的值设置为默认值,前提字段需要设置默认值;
models.DO_NOTHING:如果主表的某条记录被子表关联,当主表中被关联的数据删除时,子表不做任何处理操作;- 重点:
这里需要注意的唯一一个重点就是,不论是多对一,多对多,外键都在多的一方;
多对一
上面说过,多对一,就是一方对应多方,比如日常生活中,一个职能部门存在多个人的,比如IT部门,这个部门下有多个IT工程师,那么这多个IT工程师都只属于这一个部门,这就是一种多对一的模型;
那么在Django的ORM层面去建立这样一个多对一的模型也非常的简单,直接使用ForeignKey外键来实现的两张关联表,就默认是一种多对一的模型;
但是需要注意的是,在关系映射模型下,ForeignKey所在的一方,我们称之为多的一方,如下就是一种多对一的模型表;
class Many(models.Model):
'多方'
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14, unique=True, verbose_name='员工姓名')
info = models.ForeignKey(to='One', to_field='id', on_delete=models.CASCADE, db_column='info')
class Meta():
db_table = "many" # 表名
def __str__(self):
return "<Many: %s %s>" % (self.name, self.info)
class One(models.Model):
'一方'
id = models.AutoField(primary_key=True)
department = models.CharField(null=False, max_length=14, verbose_name='部门名称')
class Meta():
db_table = "one" # 表名
def __str__(self):
return "<One: %s>" % self.department创建测试数据
因为,我们使用了ForeignKey外键字段,也就是说,我们的Many表是需要关联到One表中的某一条记录的,那么为了更好的测试我们的关系映射模型操作,所以现在就创建一些基础数据,这些基础数据,我们只需要在ForeignKey关联的外键字段上面创建即可;
# 创建测试数据
One.objects.create(department="技术部")
One.objects.create(department="研发部")
One.objects.create(department="董事局")
Many.objects.create(name='caichangen',info=One.objects.filter(department='技术部').first())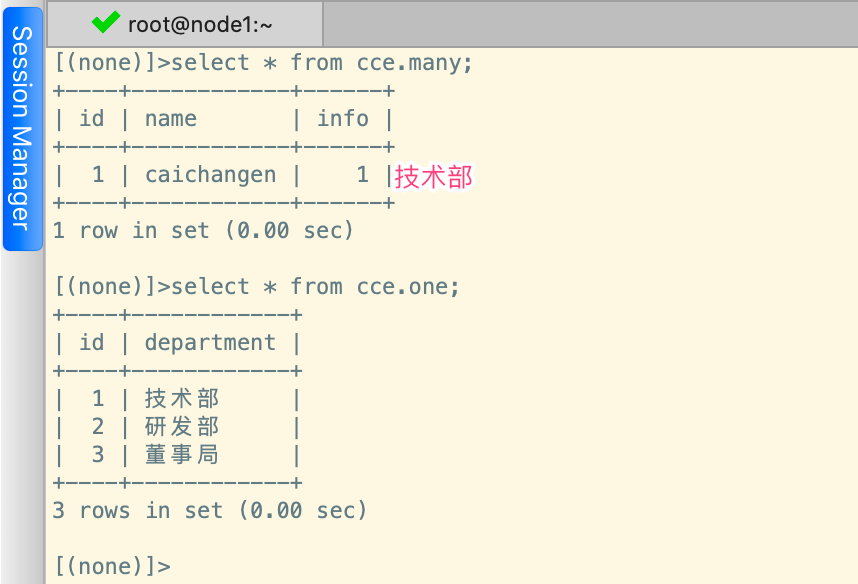
增加操作
正向操作就是在多的一方,向一的一方操作,换句话说,就是在有ForeignKey的一方,向没有ForeignKey的一方操作,那么正向增加操作,按照上述的模型来看,就是在Many表中增加数据,并和One表中的数据进行关联,如下;
# 新增员工
Many.objects.create(name='caifengjun', info=One.objects.filter(department='研发部').first())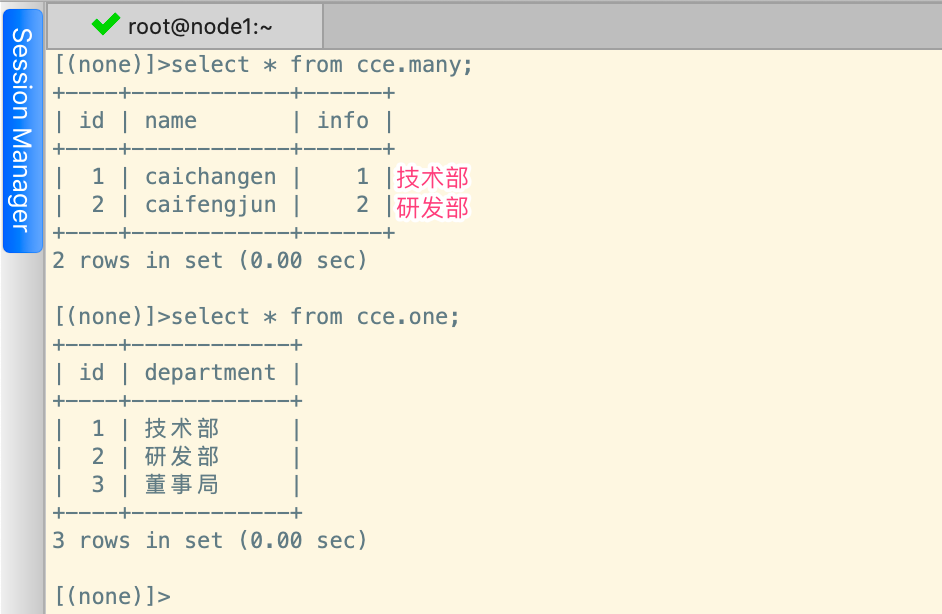
删除操作
正向删除操作就没什么好说的了,直接删除查询到的数据即可;
# 直接调用对象的delete方法进行删除
Many.objects.filter(name='caichangen').first().delete()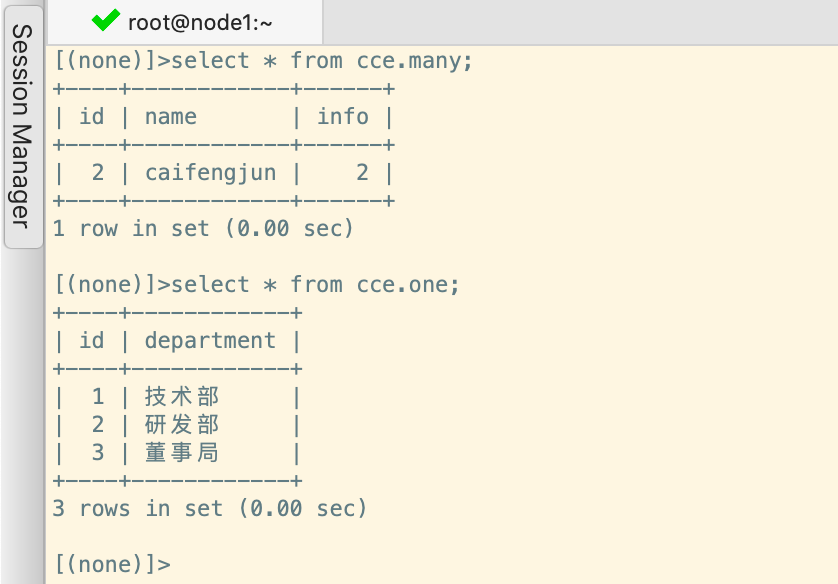
修改操作
正向修改操作和正向新增操作,其实大同小异,首先需要先将要修改为哪个部门查到,然后将这个部门赋予给指定到人员即可;
# 更新操作
Many.objects.filter(name='caifengjun').update(info=One.objects.filter(department='董事局').first())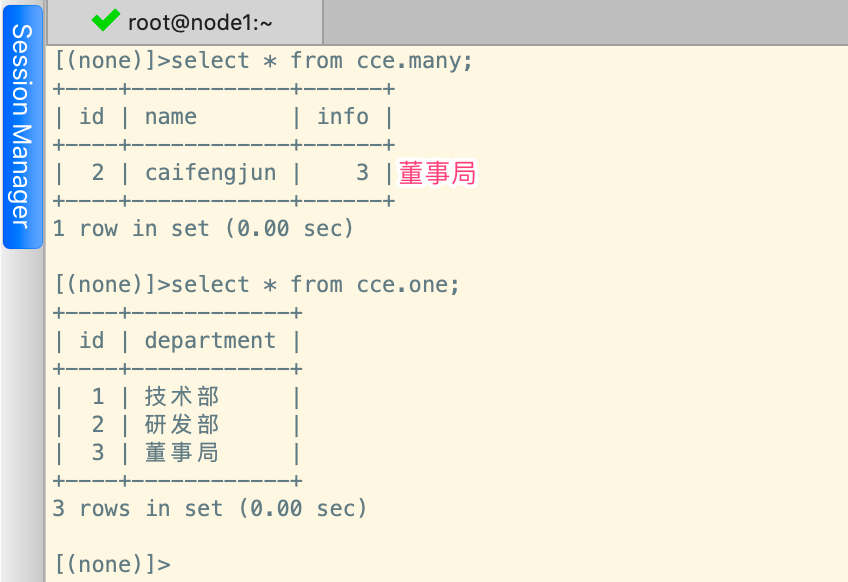
- 注意:
需要注意的是,update更新方法,是属于QuerySet对象的,而delete删除数据的方法是属于模型对象的;
正反查询
所谓正反查询的意思就是,是在多的一方向一的一方操作还是,在一的一方向多的一方操作,对于多对一,来讲,在多的一方向一的一方操作,称之为正向操作,反之,在一的一方向多的一方操作,称之为反向操作,如果我们的模型存在反向操作的情况,那么最好在多的一方的ForeignKey里面加入related_name属性,来指定反向操作时,所使用的属性名;
正向查询操作
正向查询也非常简单,正向查询对于多对一来讲,是从多的一方往一的一方查询,这就是正向查询,在多的一方里面ForeignKey字段所属的属性名的主要作用就是用来访问一的一方,那么结合上面的例子来讲,就是我们可以使用Many的对象的info属性来访问到,One的一方,如下所示;
# 正向查询,通过多的一方查询到一的一方
print(Many.objects.first().info) # <One: 董事局>反向查询操作
反向查询,和正向查询的查询入口相反,反向查询是从一的一方往多的一方查询,拿上述例子来将,我们可以通过部门来查询到这个部门内所有的员工;
那么在一的一方访问到多的一方主要有两种途径,第一种是在多的一方的ForeignKey字段类型提供了related_name参数,第二种,是在多的一方的ForeignKey字段类型没有提供related_name参数;
如果提供了related_name参数,那么就可以直接使用related_name参数值,来访问到多的一方,如果没有给定related_name参数,那么我们如果希望在,一的一方访问到多的一方,可以使用"多的一方映射类名_set"来访问,如下;
# 使用related_name参数值来访问
print(One.objects.filter(department='董事局').first().many.all()) # <QuerySet [<Many: caifengjun <One: 董事局>>]>
# 使用映射类名_set的访问来访问
print(One.objects.filter(department='董事局').first().many_set.all()) # <QuerySet [<Many: caifengjun <One: 董事局>>]>一对一
一对一其实非常简单,它是建立在我们的多对一的基础之上的,可以看到,我们多对一,ForeignKey所在的一方称之为多的一方,另一方则为一的一方,那么在这种情况之下,我们其实完全可以在ForeignKey所在的一方的外键字段属性里面新增一个,unique的属性,建立唯一所以,从而实现一对一结构;
class Users(models.Model):
'一方'
id = models.AutoField(primary_key=True)
username = models.CharField(null=False, max_length=14, unique=True, verbose_name='账号名')
info = models.ForeignKey(to='Info', to_field='id', on_delete=models.CASCADE, db_column='info', unique=True) # 一对一实现的关键要点,unique
class Meta():
db_table = "user" # 表名
def __str__(self):
return "<One: %s %s>" % (self.username, self.info)
class Info(models.Model):
'一方'
id = models.AutoField(primary_key=True)
id_card = models.CharField(null=False, max_length=14, verbose_name='身份证', unique=True) # 实现一对一结构
class Meta():
db_table = "info" # 表名
def __str__(self):
return "<One: %s>" % self.id_card- 注意:
对于一对一的CURD操作,和多对一一致,因此,不在此赘述;
一对一扩展
我们在使用上述的方式来创建一对一结构时,我们可以看到Django会给我们给出,如下提示,大概的意思是,在ForeignKey字段上设置unique=True属性,实现一对一,带来的结果和,使用OneToOneField来实现一对一的效果相同;
WARNINGS:
user.Users.info: (fields.W342) Setting unique=True on a ForeignKey has the same effect as using a OneToOneField.
HINT: ForeignKey(unique=True) is usually better served by a OneToOneField. 换而言之,Django为了规范化操作,给我们提供了一个OneToOneField的字段,它的主要作用就是创建一对一结构,相比ForeignKey的方式来讲,使用OneToOneField来创建一对一结构,Django为我们提供了多的功能,所以,我们也可以直接使用OneToOneField字段来实现一对一结构;
class Users(models.Model):
'一方'
id = models.AutoField(primary_key=True)
username = models.CharField(null=False, max_length=14, unique=True, verbose_name='账号名')
info = models.OneToOneField(to='Info', to_field='id', on_delete=models.CASCADE, db_column='info') # 实现一对一结构
class Meta():
db_table = "user" # 表名
def __str__(self):
return "<One: %s %s>" % (self.username, self.info)
class Info(models.Model):
'一方'
id = models.AutoField(primary_key=True)
info = models.OneToOneField(to='Info', to_field='id', on_delete=models.CASCADE, db_column='info',
related_name="user") # 实现一对一结构
class Meta():
db_table = "info" # 表名
def __str__(self):
return "<One: %s>" % self.id_card增删改数据
对于一对一结构,它的增加、删除和修改数据都和多对一一样,在此就做个简单的示例,如下;
# 新增用户
Users(username='cce', info=Info.objects.create(id_card="420")).save() # 直接给定外键表对象
Users(username='csw', info_id=Info.objects.create(id_card="410").id).save() # 给定外键表对象的id
# 删除数据
Users.objects.first().delete()
# 修改数据
UserObj=Users.objects.first()
UserObj.username="caidaye"
UserObj.save()查询数据
对于多对一的查询,根据不同的模型字段类型,划分为两种方式,第一种方式为ForeignKey字段类型的查询方式,该方式和多对一一样,第二种方式为OneToOneField的方式,该方式对ForeignKey字段进行了优化;
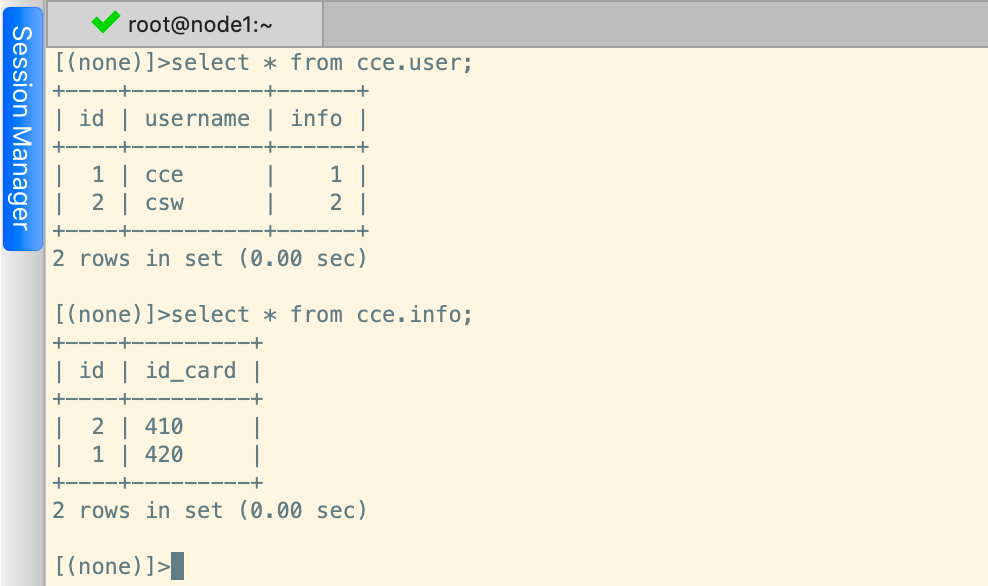
ForeignKey方式
ForeignKey的方式,其实我们直接使用上门的多对一的查询方式即可,他们几乎完全一摸一样,通过反查询将得到一个只有一个元素的列表,如下;
# 正向查询
UserObj = Users.objects.first()
print(UserObj.info.id_card) # 420
# 反向查询(没有给定related_name参数)
InfoObj = Info.objects.first()
print(InfoObj.users_set.first().username) # cce
# 反向查询(给定related_name参数)
InfoObj = Info.objects.first()
print(InfoObj.users.first().username) # cceOneToOneField方式
可以看到,对于ForeignKey的方式,在反向查询时,得到的其实是多个对象,需要使用查询集的first()方法,拿到其中一个对象,那么OneToOneField来讲,这一点做了优化,既然是一对一,不论是正向查询还是反向查询,应该都是一个对象,而不是多个对象,那么依旧沿用上门的模型示例,作出如下测试;
# 正向查询
UserObj = Users.objects.first()
print(UserObj.info.id_card) # 420
# 反向查询(没有给定related_name参数,直接使用小写表名)
InfoObj = Info.objects.first()
print(InfoObj.users.username) # cce
# 反向查询(给定related_name参数,直接使用related_name的参数值)
InfoObj = Info.objects.first()
print(InfoObj.user.username) # cce多对多
对于多对多来讲,在日常开发中也是经常能够碰到,比如一个用户,可以有多个角色,那么同时,一个角色下面一般也存在多个用户,这就是典型的多对多的关系;
对于多对多来讲,在Django的ORM框架下,模型类的实现方式主要有三种,第一种是使用ForeignKey来实现,第二种是使用Django的ORM框架提供的ManyToManyField字段类来实现半自动多对多结构,第三种是通过ManyToManyField字段类的方式来实现全自动的多对多结构;
所谓全自动和半自动它们的主要区别是,第三张表的存在形式,因为ManyToManyField字段类可以在不创建第三张表的情况下建立多对多结构,那么它也支持自定义第三张表的多对多结构,由此衍生出两种对多对结构的创建形式,一种为全自动,无序第三张表,多对多关系交给ORM框架去处理,另一种则是去半自动,半自动形式需要我们手动创建第三张表,然后和ManyToManyField字段类建立联系;
但是不管是哪种实现方式,对于多对多结构来讲,都需要一个第三张表来实现多对多关联,不管这个第三张表是存在还是不存在;
ForeignKey方式
使用ForeignKey方式来创建多对多非常简单,既然我们都知道ForeignKey所在的一方为多的一方,那么我们可以创建一个第三张表分别与其他两张表建立外键关系,也就是两个对多一合起来,将多的一方都放在一张表里面,这样,两个一的一方,就可以在第三张表中建立关联关系,从而实现多对多结构,如下;
class Users(models.Model):
id = models.AutoField(primary_key=True)
username = models.CharField(null=False, max_length=14, unique=True, verbose_name='账号名')
class Meta():
db_table = "user" # 表名
def __str__(self):
return "<Users: %s>" % (self.username)
class Roles(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14, verbose_name='身份证', unique=True)
class Meta():
db_table = "roles" # 表名
def __str__(self):
return "<Roles: %s>" % self.name
class UserRole(models.Model):
id = models.AutoField(primary_key=True)
user = models.ForeignKey(to='Users', to_field="id", db_column="user", on_delete=models.CASCADE, related_name="user_extension")
role = models.ForeignKey(to='Roles', to_field='id', db_column="role", on_delete=models.CASCADE, related_name="role_extension")
class Meta():
db_table = "user_role" # 表名
unique_together = [("user", "role")] # 创建联合唯一索引
def __str__(self):
return "<UserRole: %s %s>" % (self.user, self.role)增删改查
这种ForeignKey实现的方式创建的多对多关系表,做数据的增删该查,其实就和单表操作是一样的,相比使用ManyToManyField字段实现,它比较繁琐,ForeignKey这种方式,拿新增数据来说,我们需要一张表一张表的去插入,然后将这插入到多条数据使用第三张表进行关联;
# 新增数据
user = Users.objects.create(username="cce")
Roles.objects.create(name="管理员") # 用于修改
role = Roles.objects.create(name="操作员")
UserRole.objects.create(user=user, role=role)
# 删除数据
# Users.objects.first().delete() # 因为on_delete策略为CASCADE,所以,此处删除会直接删除关系表的数据
# 修改数据
role = Roles.objects.filter(name="管理员").first() # 获取一个准备修改成为的角色对象
user = Users.objects.filter(username="cce").first() # 获取要修改角色的用户
user_extension_obj = user.user_extension.first() # 通过用户拿到第三张表的关系对象
user_extension_obj.role = role # 将第三张表的关系对象中的角色修改为,上述的管理员对象
user_extension_obj.save() # 保存
# 通过用户查询角色
print(Users.objects.first().user_extension.first().role.name) # 管理员
# 通过角色查询用户
print(Roles.objects.first().role_extension.first().user.username) # cceManyToManyField
可以看到上述,通过ForeignKey来实现多对多,极为不便,需要编写大量的代码来实现一个简单的数据增删改查,因此,Django的ORM框架就提供了这个ManyToManyField字段,做了大量的优化工作,极大的方便了我们日常开发,该字段主要有如下参数;
to:设置要关联的表;
related_name:同ForeignKey字段,只不过此处主要是用于从表访问主表,这里所谓的从表就是第二张表,并非第三张表关系表;
related_query_name:同ForeignKey字段;
symmetrical:仅用于多对多自关联时,指定内部是否创建反向操作的字段,默认为True;
through:在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系,我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名;
through_fields:设置关联表中的字段,第一个为主表的关联字段,第二个为子表的关联字段,因为在我们自定义第三张表可能会添加一些其他的字段,所以这个时候,我们可能就需要用到这个参数来指定关联字段;
db_table:默认创建第三张表时,数据库中表的字段名称;ManyToManyField全自动
所谓全自动就是,直接将第三张表交给Django的ORM框架来处理,作为程序员,我们不关注第三张表到底是什么样,直接托管给Django的ORM框架来处理;
Django的ORM会自动将我们的第三张表创建出来,但是我们需要知道的是,我们无法对第三张表进行任何单独的管理,比如添加字段,修改字段等,如下示例;
class Users(models.Model):
id = models.AutoField(primary_key=True)
username = models.CharField(null=False, max_length=14, unique=True, verbose_name='账号名')
user_role = models.ManyToManyField("Roles", db_table="user_role", related_name="user")
class Meta():
db_table = "users" # 表名
def __str__(self):
return "<Users: %s>" % (self.username)
class Roles(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14, verbose_name='身份证', unique=True)
class Meta():
db_table = "roles" # 表名
def __str__(self):
return "<Roles: %s>" % self.name
ManyToManyField半自动
ManyToManyField提供了一个自定义第三张表的接口,所以我们也可以直接利用这个接口去手动创建第三张表,这样也更加的灵活,我们可以在第三张表新增一些其他附带信息,比如关联创建时间、修改时间,等等操作,如下示例;
class Users(models.Model):
id = models.AutoField(primary_key=True)
username = models.CharField(null=False, max_length=14, unique=True, verbose_name='账号名')
user_role = models.ManyToManyField(to="Roles", through="UserRole")
class Meta():
db_table = "users" # 表名
def __str__(self):
return "<Users: %s>" % (self.username)
class Roles(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14, verbose_name='身份证', unique=True)
class Meta():
db_table = "roles" # 表名
def __str__(self):
return "<Roles: %s>" % self.name
class UserRole(models.Model):
id = models.AutoField(primary_key=True)
user = models.ForeignKey(to='Users', to_field="id", db_column="user", on_delete=models.CASCADE,
related_name="user_extension")
role = models.ForeignKey(to='Roles', to_field='id', db_column="role", on_delete=models.CASCADE,
related_name="role_extension")
class Meta():
db_table = "user_role" # 表名
def __str__(self):
return "<UserRole: %s %s>" % (self.user, self.role)
增删改查
对于ManyToManyField字段类实现的多对多结构下的增删改查来讲,它比ForeignKey实现的多对多结构使用起来方便得太多太多,ManyToManyField将这些增删改查的操作全部封装了,对于增、删、改都提供了相应的方法接口,至于查询操作大概和我们的一对多相似;
使用ManyToManyField字段类实现的多对多结构查询得到的对象,都会新增如下几个方法,需要注意的是,如下这些方法在多对多场景下都有自己独特的用途,和我们之前使用的objects对象中的方法并不一样;
create():该方法的主要用途是,在第一张表中去创建第二张表的数据,当我们拿到第一张表的记录对象时,我们可以使用其关联字段的create()方法,实现跨表数据添加,并且,在创建完成跨表数据添加之后,会将这两张表中的两条数据在第三张表中建立多对多关联关系;
set():接收一个可迭代对象,它主要是更新当前(第一张表的对象)对象的多对多关联关系,直接覆盖当前对象的多对多关系;
remove():接收一个第二张表的对象,表示将指定对象(第二张表),从当前对象(第一张表)的多对多关系移除,但如果ForeignKey的null=False那么就清除不了;
clear():清空当前对象的多对多关系,但如果ForeignKey的null=False那么就清除不了; 上述可能说得有点迷糊,那么下面我们就来具体看看,对于多对多场景下的,数据增删改查。下述的正向表示ManyToManyField所在的一方,而另一方则是反向;
# 正向新增数据(自动建立多对多关系)
user = Users.objects.create(username="cce")
user.user_role.create(name="操作员")
# 反向新增数据(自动建立多对多关系)
role = Roles.objects.create(name="管理员")
role.user.create(username="csw")
# 添加多对多关系
user = Users.objects.filter(username="cce").first()
role = Roles.objects.filter(name="管理员").first()
user.user_role.add(role)
# 移除多对多关系
user = Users.objects.filter(username="cce").first()
role = Roles.objects.filter(name="管理员").first()
user.user_role.remove(role)
# 清空多对多关系
user = Users.objects.filter(username="cce").first()
role = Roles.objects.filter(name="管理员").first()
user.user_role.clear()
# 更新多对多关系
user = Users.objects.filter(username="cce").first()
user.user_role.set(Roles.objects.all())
# 正向查询多对多关系
print(Users.objects.filter(username="csw").first().user_role.all()) # <QuerySet [<Roles: <Roles: 管理员>>]>
# 反向查询多对多关系
print(Roles.objects.filter(name="管理员").first().user.all()) # <QuerySet [<Users: <Users: csw>>]>跨表引用
在Django的ORM框架中,只要我们使用了ForeignKey实现了外键字段,我们可以都直接跨表引用其他字段,可以在当前表中,直接引用与之关联的外键表中对象的数据,听起来有点绕,说白了,就是我们在查询当前表时,使用filter给定的查询条件,可以是另外一张表的;
这种跨表查询,使用双下划线,连接两个表的字段,如,当前表外键字段__外键表字段,如下;
# 跨表查询
print(Users.objects.filter(user_role__in=Roles.objects.filter(name="操作员"))) # 使用当前表外键字段__外键表字段实现跨表查询
# <QuerySet [<Users: <Users: cce>>]>扩展
在目前Web开发中,一般都是采用前后端分离的架构实现整个网站的设计,那么在这种场景下,作为前端来讲,主要负责数据的渲染,作为后端来讲,只需要负责数据的CURD即可,那么在这种场景下,前后端实现数据交互的手段,一般都是以JSON的形式进行交互;
那么因为我们的ORM框架查询数据出来之后,会映射成对应模型类的对象,这就很麻烦了,一个对象转化成JSON,虽然不复杂,但是比较繁琐,会产生大量的重复代码,所以在这种场景下,可以直接编写一个工具类,能够统一的将所有模型类的对象数据,实现JSON化,如下;
import json
def to_dict(instance, exclude=[]):
data = {}
for field in instance._meta.fields:
if field.name not in exclude:
data[field.name] = getattr(instance, field.name)
return json.dumps(data)事物
在软件开发的过程中,很多时候,我们可能会在一次处理都过程中,修改多张表,那么这就问题来了,如果出现这么一个情况,我们在修改第一个表的时候,很正常,由于模型类对象的save方法,不仅将数据持久化了,还将事务也提交了,所以我们第二个表在执行数据新增的时候,出现了问题,比如常见的问题,主键重复,提交的数据类型与字段不一致,所以第二张表的操作失败了;
但是我们但第一张表是成功但,那么这就出现了数据不一致的情况,那么为了解决这种情况,我们就需要加入事务的处理机制,要么全部成功,要么全部失败,从而保证数据的一致性;
那么Django的ORM框架中,在django.db.transaction下面提供了一个atomic()的方法实现事务处理的,同时,它还支持上下文,我们将我们的需要对ORM操作的语法,放在这个atomic()方法的内部即可,让atomic()方法来管理我们的事务提交,语法如下;
with transaction.atomic():
# ORM代码段