3、Django框架三
ORM(Object Relational Mapping)
Django ORM概述
Django ORM数据库配置
Django ORM命令行
Django ORM外部连接配置
Django ORM模型字段类
Django ORM模型字段属性
Django ORM模型关系字段
Django ORM缺省主键
Model类
Meta元数据定义
创建测试模型类
管理器对象
数据新增
数据删除
修改数据
查询集
all
values
查询集切片
排序
Lookup表达式
Django ORM概述
Django ORM数据库配置
Django ORM命令行
Django ORM外部连接配置
Django ORM模型字段类
Django ORM模型字段属性
Django ORM模型关系字段
Django ORM缺省主键
Model类
Meta元数据定义
创建测试模型类
管理器对象
数据新增
数据删除
修改数据
查询集
all
values
查询集切片
排序
Lookup表达式
ORM(Object Relational Mapping)
PyMySQL在有些场景下,做一些数据库的处理是没问题的,因为它是直接使用SQL语句,只要我们掌握SQL语句编写规范即可,但是PyMySQL在实际稍微上规模一点的项目中,很少大规模的使用,因为它操作的对象就是表,直接使用人工编写的SQL语句与数据库进行交互,实际上还是非常复杂的,对SQL语句的编写要求也非常高;
所有随着技术的发展,慢慢将这种与数据库进行交互的方式,在驱动层面就加入了面向对象的元素,它将一个一个的表映射成一个一个对象,对这个对象的操作,驱动层就会转换成对应的SQL语句,这样,以后所有的操作都编变成了对象的操作,对这个对象的操作完成之后,我们再调用这个对象的一个方法,就可以直接将我们的改变操作应用到数据库;
因此,就提出了ORM(Object Relational Mapping)的概念,即对象关系映射,使用对象的方式来操作数据库,所谓对象就是我们经常写的一些class类,将这个class对象的属性名和属性值映射成数据库中的字段和值,如下;
class Student:
id = 某类型字段
name = 某类型字段
age = 某类型字段 实际上它内部是通过描述器实现的,大致就是如下的实现逻辑,PyMySQL是比较传统的方式,使用原生SQL语句来完成的,而ORM则是加入了面向对象元素,将表中的一列一列的数据,映射成为编程语言中的一个一个的对象,一个一个实体;
# 数据描述器
class Column:
def __get__(self, instance, owner):
pass
def __set__(self, instance, value):
pass
# ORM映射
class Student:
id = Column() # 描述器
name = Column() # 描述器
age = Column() # 描述器
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
# 一个对象,即一列数据
s1 = Student(id=1, name='cce', age=18)Django ORM概述
不同的语言不同的框架下,都有各自主流的一些ORM框架,比如说java里面有著名的Hibernate、MyBaits等,而在我们的Python实践里面有著名的SqlAchmery等,Django作为一个极具成型的Web框架,对ORM这块也提供了较高的支持,也就是说在Django框架里同样有一套属于Django自己的ORM框架,它和我们的SqlAchmery其实底层原理大致相同的;
Django的ORM框架和之前了解的SqlAchmery是一样的,可以将类和数据表进行对应起来,只需要通过类和对象就可以对数据表进行操作,和传统的ORM框架没什么两样;
Django ORM数据库配置
在Django项目创建之初,就会默认的在项目根目录下的settings.py全局配置文件当中,加入一项配置名为DATABASES的配置,该配置用来配置我们的Django项目所使用的数据库信息的,如使用数据库的类别、连接信息等,那么对于Django来讲,主要支持postgresql、mysql、sqlite3和oracle四款数据库,它们都有各自的数据库引擎,那么这几项数据库的引擎分别如下;
postgresql:django.db.backends.postgresql
mysql:django.db.backends.mysql
sqlite3:django.db.backends.sqlite3
oracle:django.db.backends.oracle Django项目在默认情况下,采用的是sqlite3数据库作为后端数据库,那么在正常的项目开发的过程中,其实我们都会替换为常见的类似postgresql或者mysql数据库,它们都是通过不同的数据库引擎来区分的,当然,对于Django来讲,它也支持多种数据源,具体就是通过数据库的配置名称来区分,如下;
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'indexdb',
'USER': 'root',
'PASSWORD': 'root',
'HOST': 'localhost',
'port': '3306',
},
'db2': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'userdb',
'USER': 'root',
'PASSWORD': 'root',
'HOST': 'localhost',
'port': '3306',
},
} 那么如果我们期望在Django项目中使用MySQL数据库作为后端数据库,需修改settings.py的DATABASES配置项为Django内置的mysql连接引擎以及数据库相关配置,如下;
# settings.py
DATABASES = {
'default': { # 默认配置
'ENGINE': 'django.db.backends.mysql', # 使用mysql连接引擎
'NAME': 'cce',
'USER': 'cce',
'PASSWORD': 'caichangen',
'HOST': '47.104.197.46',
'PORT': '3306',
}
}Django ORM命令行
Django针对ORM的管理提供了几个命令,这几个命令主要是使开发者能在模型对象开发中更加的便捷,这些命令主要是使用Django项目下的manage.py文件来实现调用的,manage.py是每个Django项目中自动生成的一个用于管理项目的脚本文件,需要通过python命令执行,manage.py接受的是Django提供的内置命令,那么针对ORM这块的命令有如下几项;
语法结构:python manage.py options
options :
flush:清空数据库,恢复数据库到最初状态;
makemigrations:生成数据库同步脚本,即生成一个目前对数据库更改对文件;
migrate:同步数据库,将本地的同步脚本提交到数据库;
showmigrations:查看生成的数据库同步脚本;
sqlflush:彻底清空数据库;
sqlmigrate:查看数据库同步的sql语句,[X]代表已同步,[ ]代表待同步; 此外,作为Django框架来将,任何一个使用Django脚手架创建的项目都会注册一个admin的后台管理App,这个admin的App里面自带了一部分的model模型类,所以,如果我们希望能够正式的使用Django项目进行ORM开发,必须首先将这个admin的App里面的model类,同步到数据库当中;
# 查看当前未同步的model类
[cce@doorta /usr/local/Project/blog]# python3.5 manage.py showmigrations
admin
[ ] 0001_initial
[ ] 0002_logentry_remove_auto_add
[ ] 0003_logentry_add_action_flag_choices
auth
[ ] 0001_initial
[ ] 0002_alter_permission_name_max_length
[ ] 0003_alter_user_email_max_length
[ ] 0004_alter_user_username_opts
[ ] 0005_alter_user_last_login_null
[ ] 0006_require_contenttypes_0002
[ ] 0007_alter_validators_add_error_messages
[ ] 0008_alter_user_username_max_length
[ ] 0009_alter_user_last_name_max_length
[ ] 0010_alter_group_name_max_length
[ ] 0011_update_proxy_permissions
contenttypes
[ ] 0001_initial
[ ] 0002_remove_content_type_name
sessions
[ ] 0001_initial
user
(no migrations)
# 将其同步到数据库当中
[cce@doorta /usr/local/Project/blog]# python3.5 manage.py migrate
Django ORM外部连接配置
上述,已经将我们的Django ORM的基础配置完成了,但是此时,默认情况下,如果Django项目未启动,我们是无法对模型类,进行数据的CURD的,因为Django中的ORM必须借助Django内部的一些基础配置才能使用,也就是说,如果我们希望,在Django项目外部或者说,在不启动Django项目的情况下,进行ORM的CURD开发默认情况下是不行的;
所以,当我们希望能够在Django项目外部创建一个测试的文件来测试,那么我们就需要在该测试文件中,加入Django项目中的一些基础环境设置,如下;
import django, os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "blog.settings")
django.setup()
# -------------------------下面开始模型的开发-------------------------Django ORM模型字段类
模型,即Model,模型主要作用就是用来设计数据库与模型类之间的对应关系的,它里面提供了很多映射类,这些映射累分别代表数据库当中各种类型的字段,也就是说,如果我们期望,将一个面向对象的类下面的属性映射成数据库中的某个字段类型,我们就将需要这个类里面的属性设置成这个指定类型的映射类;
在Django的ORM框架下,提供了非常非常多的ORM字段映射类,比如常见的int、varchar、date等等等,均有提供,甚至还扩展了很多映射类,如email、url、image等,只不过这些,我们基本用不到,那么常见的映射字段类,如下表;
|
字段类
|
说明
|
数据类型
|
必备参数
|
|
AutoField
|
自增的证书字段,如果不指定,Django会为模型类自动创建一个主键字段;
|
int(11)
|
primary_key = True,即将该作为主键存在
|
|
BooleanField
|
布尔值字段
|
tinyint(1)
|
blank=True,即字段不能为空
|
|
NullBooleanField
|
允许存在null值的布尔类型
|
varchar
|
|
|
CharField
|
字符串字段,长度小于255
|
varchar(50)
|
max_length = 50,即设置字段长度为50
|
|
TextField
|
长文本类型,一般超过4000个字符使用
|
longtext
|
|
|
IntegerField
|
整数类型
|
int
|
|
|
BigIntegerField
|
更大的8字节整数字段
|
int
|
|
|
DecimalField
|
十进制小数类型,保留几位小数
|
decimal
|
最大位数max_digits = 10,和小数位decimal_places = 2
|
|
FloatField
|
浮点型字段
|
float
|
最大位数max_digits = 10和小数位decimal_places = 2
|
|
DateField
|
日期类型
|
date
|
default=timezone.now,即修改字段保存当前时间
|
Django ORM模型字段属性
在Django的ORM模型字段类下,支持众多的参数,这些参数是所有模型字段类都可以共用的一些参数,如下;
|
值
|
说明
|
|
db_column
|
字段名称,如果未指定,则使用属性名称
|
|
primary_key
|
表示该字段是否为主键
|
|
unique
|
表示该字段是否是唯一键
|
|
default
|
缺省值,这个缺省值不是数据库级别的缺省值,而是新产生数据时Django在ORM层面添加的缺省值
|
|
null
|
表示字段是否可以为null,默认false
|
|
blank
|
表示字段是否可以为空
|
|
db_index
|
表示字段是否有索引
|
Django ORM模型关系字段
Django的ORM模型中,也提供了一些表示关系的字段,主要有三项,外键、一对一、多对多,这些都是我们日常 开发中用到非常频繁的一些表关系,比如在一对一关系中,Django ORM框架允许我们可以在一张表中,直接访问另一张表;
|
值
|
说明
|
|
ForeignKey
|
外键关系
|
|
ManyToManyField
|
多对多关系
|
|
OneToOneField
|
一对一关系
|
Django ORM缺省主键
Innodb要求一个表中,必须存在一个主键,那么如果在Django下没有显示定义主键,Django的ORM模型会自动在这个模型下面创建一个名为id类型为autoField的主键字段,如下;
id = models.AutoField(primary_key=True) 如果模型中,显式定义了主键,哪怕名称不为id,那么这个就不会自动添加,所以尽量使用自定义主键,哪怕该字段名就是id;
Model类
和SqlAchmery一样,我们需要在Django的ORM框架中,构建模型类,就需要一个基类,在SqlAchmery的基类为,declarative_base类的实例,而在Django的ORM模型中,基类为django.db.Models模块下的Model类,所有的模型类都需要继承这个基类,如下;
# models.py
from django.db import models
class Users(models.Model):
id = models.IntegerField(primary_key=True)Meta元数据定义
对于ORM框架中的模型类的构建,如果需要定义一些元数据信息,比如,表名、排序字段等定义,对于SqlAchmery使用的是类属性来表示的,比如常见的__tablename__表示当前模型类映射的表名,而Django中的ORM使用的是类中类实现的,换而言之就是在模型类中再定义一个类,这个类的名称为Meta,下面定义这个模型类的一些元信息,如下;
class Users(models.Model):
id = models.IntegerField(primary_key=True)
class Meta():
db_table = "users" # 指定当前模型映射的表名
ordering = ['id'] # 指定该模型的默认排序字段 那么根据源码来看,可定义的元信息属性有很多,如下;
abstract:如果abstract=True,那么模型会被认为是一个抽象模型。抽象模型本身不实际生成数据库表,而是作为其它模型的父类,被继承使用。具体内容可以参考Django模型的继承;
app_label:如果定义了模型的app没有在INSTALLED_APPS中注册,则必须通过此元选项声明它属于哪个app;
base_manager_name:模型的_base_manager管理器的名字,默认是'objects'。模型管理器是Django为模型提供的API所在;
db_table:指定在数据库中,当前模型生成的数据表的表名;
db_tablespace:自定义数据库表空间的名字。默认值是项目的DEFAULT_TABLESPACE配置项指定的值;
default_manager_name:模型的_default_manager管理器的名字;
default_related_name:默认情况下,从一个模型反向关联设置有关系字段的源模型,我们使用<model_name>_set,也就是源模型的名字+下划线+set;
managed:该元数据默认值为True,表示Django将按照既定的规则,管理数据库表的生命周期,如果设置为False,将不会针对当前模型创建和删除数据库表,也就是说Django暂时不管这个模型了;
required_db_vendor:声明模型支持的数据库。Django默认支持sqlite、postgresql、 mysql、oracle;
indexes:接收一个应用在当前模型上的索引列表,如下;
class Customer(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
class Meta:
indexes = [
models.Index(fields=['last_name', 'first_name']),
models.Index(fields=['first_name'], name='first_name_idx'),
]
unique_together:联合唯一索引;
index_together:联合索引;
verbose_name:最常用的元数据之一!用于设置模型对象的直观、人类可读的名称,用于在各种打印、页面展示等场景。可以用中文;创建测试模型类
模型类的创建,以及模型类元信息定义已经大致有所了解,那么接下来,我们就定义一个基础的模型类,并将其提交到数据库中,进行基本的测试,如下;
# 定义模型类
[cce@doorta ~]# cat /usr/local/Project/blog/user/models.py
from django.db import models
class Users(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(null=False, max_length=14)
age = models.IntegerField(null=False)
gender = models.SmallIntegerField(null=False)
brith_date = models.DateField(null=False)
class Meta():
db_table = "users" # 表名
ordering = ['id'] # 排序字段
def __repr__(self):
return "<Users: %s %s>" % (self.id, self.name)
# 生成同步脚本
[cce@doorta ~]# python3.5 /usr/local/Project/blog/manage.py makemigrations
Migrations for 'user':
/usr/local/Project/blog/user/migrations/0001_initial.py
- Create model Users
# 同步到数据库
[cce@doorta ~]# python3.5 /usr/local/Project/blog/manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions, user
Running migrations:
Applying user.0001_initial... OK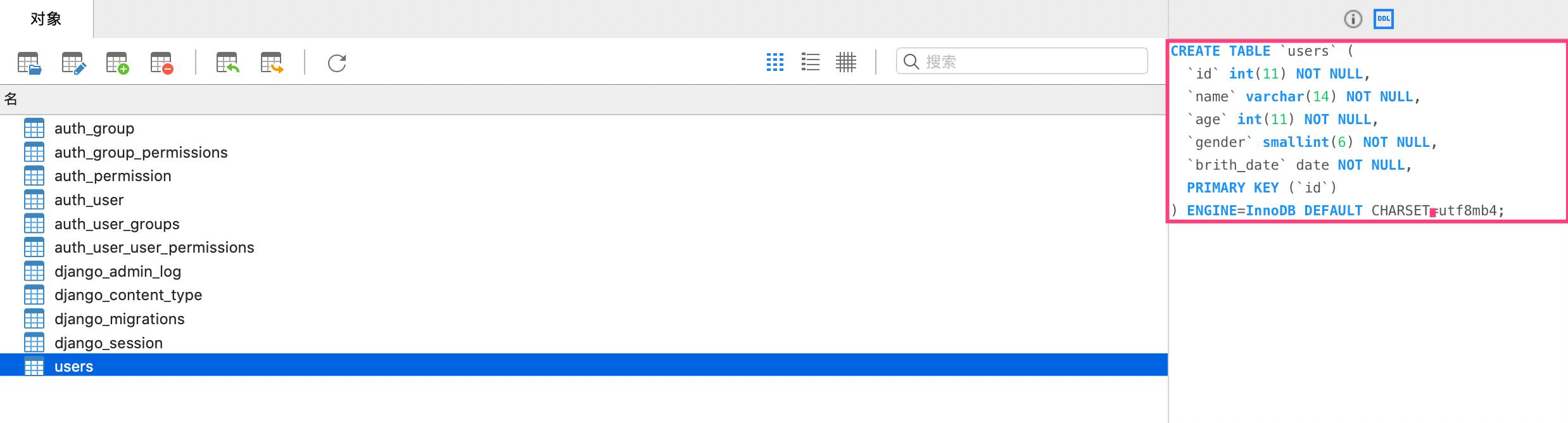

管理器对象
Django的ORM会在元类当中,即ModelBase当中,为每一个模型类注入一个objects对象,那么因为这个对象是由ORM框架的元类添加进来的,所以我们在进行模型开发时,该objects对象并不在模型类的__dict__属性列表当中,所以PyCharm也不会进行下标提醒;
该object对象属于django.db.models.manager.Manager类型,它是Django的ORM模型进行数据库查询的操作接口,主要用于与数据库进行交互,Django的ORM框架的每个模型类都至少有一个管理器,用户也可以自定义管理器,继承自django.db.models.manager.Manager即可实现表级别控制;
因为该管理器是ORM框架与数据库的交互接口,它的主要工作就是与数据库进行交互,所以以下的所有有关ORM框架的CURD都是基于这个管理器实现的,使用该管理器返回的查询类型的结果,都会被封装成一个查询集,这个查询集是一个QuerySet对象;
数据新增
此处的数据新增为基础表结构数据的新增,换而言之,就是单表的数据新增,那么对于单表的数据新增的方式也是多式多样的,主要有三种,第一种方式是,直接调用管理器的create方法,第二种方式是调用QuerySet查询集对象的save方法,第三种方式,是批量插入数据,如下;
# 方式一
Users.objects.create(name="cce", age=26, gender=0, brith_date="1996-04-26")
# 方式二
Users(name="cce", age=26, gender=0, brith_date="1996-04-26").save()
# 方式三
QuerySetList = []
for i in range(5):
QuerySetList.append(Users(name="cce", age=26 + i, gender=0, brith_date="1996-04-26"))
Users.objects.bulk_create(QuerySetList)
# 查询结果
print(Users.objects.values_list("id", "age")) # <QuerySet [(1, 26), (2, 26), (3, 26), (4, 27), (5, 28), (6, 29), (7, 30)]>数据删除
此处的数据删除一样是单表内的操作,对于单表内的数据删除,主要有两种方式,第一种方式是直接调用查询集的delete方法来删除所有符合条件的数据,第二种方法是直接调用对象的delete方法,删除单条数据;
# 方式一,删除单条数据
Users.objects.filter(age__gte=30).first().delete()
# 方式二,删除多条数据
Users.objects.filter(age__gt=26).delete()
# 查询结果
print(Users.objects.values("id", "age")) # <QuerySet [{'id': 1, 'age': 26}, {'id': 2, 'age': 26}, {'id': 3, 'age': 26}]>修改数据
修改数据对于单表来讲,和删除数据是一样的,主要有两种方式,第一种是调用查询集的update方法,第二种是直接使用对象赋值的方式,来修改对象的内容,然后调用其save方法,进行提交;
# 修改多条数据
Users.objects.filter(id__gte=2).update(age=38)
# 修改单条数据
user = Users.objects.filter(id=1).first()
user.age = 18
user.save()
# 查询结果
print(Users.objects.values("id", "age")) # <QuerySet [{'age': 18, 'id': 1}, {'age': 38, 'id': 2}, {'age': 38, 'id': 3}]>查询集
上面也说了,查询集就是object对象下面的all()、filter()等方法调用之后,会返回一个在django.db.models.query模块下的的QuerySet对象,这个对象中包括了我们需要的数据,每条数据都以一个一个的对象来呈现,实际上QuerySet是一个惰性对象,只有我们在需要获取里面数据的时候,才会真正的向数据库发起连接并进行数据检索,同时,QuerySet还是一个支持链式调用的对象,在一个QuerySet查询集对象下面调用查询集方法,得到的依旧是一个QuerySet查询集对象,那么该查询集主要提供了如下几种可调用的方法,主要用于在ORM层面从数据库里获取数据行;
# 查询集方法
all():查询全部记录,返回一个QuerySet查询集对象;
filter():查询符合条件的多条记录,返回一个QuerySet查询集对象;
exclude():查询符合条件之外的所有记录,返回一个QuerySet查询集对象;
order_by():排序,返回一个QuerySet查询集对象;
values():它依旧返回的是一个查询集对象,只不过这个对象内部都是字典类型的键值对儿,而不再是一个一个的对象;
values_list():它与values方法非常相似,values返回一个字段序列,而它返回一个元组序列;
# 返回单个对象
get():查询符合条件的一条记录,返回一条记录,该条记录会转换成映射类的对象;
count():返回当前查询的总条数,返回一条记录,该条记录会转换成映射类的对象;
first():返回第一个对象,返回一条记录,该条记录会转换成映射类的对象;
last():返回最后一个对象,返回一条记录,该条记录会转换成映射类的对象;
exist():判断查询集中是否有数据,如果有则返回True;all
如果我们期望拿到一个模型类对应的数据库表里面的所有数据,我们可以直接使用查询集的all()方法,然后返回一个查询结果集,如下;
import django, os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "blog.settings")
django.setup()
from user.models import Users
# 查询Users模型映射的数据库表中所有的数据行和字段
print(Users.objects.all()) # <QuerySet [<Users: 1 cce>, <Users: 2 cfj>, <Users: 3 yml>]> 上面我们说了,QuerySet是一个惰性对象,默认情况下,只要我们不获取该对象内的内容,就不会真正的向数据库发起请求,所以虽然上述我们看到确实拿到了数据,那是因为我们使用print()函数驱动了它,如果我们只是调用了这个方法,它并不会连接到数据库,当我们驱动这个all()方法返回的惰性对象时,它就会连接到数据库进行查询,根据上面的结果也可以看出来,从数据库中返回的每一条记录,最后都被映射成了一个一个的实例,这就是我们上述所谓的映射关系,模型类和表对应,类属性和字段对应,类的实例则和表中的一行行数据对应;
values
values方法有点特殊,上面说过,我们使用Manager管理器对象(就是映射类的object对象)去数据库中检索数据的时候,返回的是一个这样的<QuerySet [<Users: 1 cce>, <Users: 2 cfj>]>,在QuerySet查询集内包含多个以字典包裹的查询结果对象,但是如果我们调用了这个查询集对象的values方法,那么它返回的就不再是查询集内包含多个以字典包裹的查询结果对象,而是查询集内包含的一个一个的字典,该字典的key为字段名,value为字段值,如下;
from user.models import Users
print(Users.objects.values()) # <QuerySet [{'age': 26, 'id': 1, 'gender': 1, 'brith_date': datetime.date(1996, 4, 26), 'name': 'cce'}, {'age': 14, 'id': 2, 'gender': 0, 'brith_date': datetime.date(2008, 5, 1), 'name': 'cfj'}, {'age': 24, 'id': 3, 'gender': 0, 'brith_date': datetime.date(1999, 7, 28), 'name': 'yml'}, {'age': 48, 'id': 4, 'gender': 1, 'brith_date': datetime.date(1974, 9, 4), 'name': 'csw'}]>查询集切片
需要知道的是,查询集,这个集就代表不止一条数据,而是多条数据,如下,我们也可以通过QuerySete的源码看出来,它返回的实际上就是一个字典,如下;
class QuerySet:
def __repr__(self):
data = list(self[:REPR_OUTPUT_SIZE + 1]) # 以字典形式进行数据封装
print(type(data))
if len(data) > REPR_OUTPUT_SIZE:
data[-1] = "...(remaining elements truncated)..."
return '<%s %r>' % (self.__class__.__name__, data) 所以,我们的查询集,也支持切片操作,但是,我们需要知道的是,查询集的切片并不能完全复制列表的切片,因为对于查询集的切片,它并不支持负数切片,同时,有一点非常重要,切片操作并不是把所有的数据从数据库中提取出来再做操作,而是在数据库层面使用LIMINT和OFFSET来完成,也就是说,QuerySet对切片操作进行了一次封装,一旦发现该查询语句存在切片操作,就会在正式向数据库发起请求之前,将这个切片操作转化为LIMINT和OFFSET操作,所以,我们也完全可以将它作为分页的底层实现逻辑,如下;
from user.models import Users
print(Users.objects.all()[0:2])
print(Users.objects.all()[2:4])
# <QuerySet [<Users: 1 cce>, <Users: 2 cfj>]> # 实际SQL为:SELECT `users`.`id`, `users`.`name`, `users`.`age`, `users`.`gender`, `users`.`brith_date` FROM `users` ORDER BY `users`.`id` ASC LIMIT 2
# <QuerySet [<Users: 3 yml>, <Users: 4 csw>]> # 实际SQL为:SELECT `users`.`id`, `users`.`name`, `users`.`age`, `users`.`gender`, `users`.`brith_date` FROM `users` ORDER BY `users`.`id` ASC LIMIT 2 OFFSET 2排序
排序就非常简单了,主要使用查询集的order_by方法实现,在该方法内传入一个排序字段即可,默认为升序,如果我们期望得到降序的效果,需要使用到"-"符号,语法结构如下;
升序:查询集.order_by("排序字段")
降序:查询集.order_by("-排序字段") # 在排序字段前,加入"-"符号;Lookup表达式
此前,在使用查询集的filter方法查询数据时,只使用了一个"="的运算符,来进行数据过滤,因为在ORM框架中,并不支持使用类似">"、"<"、"!="这种类型的运算符来进行过滤操作,那么这个时候就需要借助Lookup表达式来实现,Lookup表达式主要是用来解决,这种过滤操作符的,比如常见的大于、小于、等于、不等于等等等,它的语法也很奇怪,属性名和运算符之间使用双下划线来表示,比较的值,放在等号后面,如下;
语法结构:属性名__运算符=值 那么对于Lookup表达式可用的运算符也非常的多,基本能够应付我们日常的数据库开发,主要有如下几种;
|
名称
|
举例
|
说明
|
|
exact
|
filter(id=1) 和 filter (id__exact=1)
|
等于,可省略,因为filter支持”=”运算符
|
|
contains
|
filter(title__contains=”天”)
|
包含,等价于like “%天%”
|
|
startswith
|
filter(title__startswith=”天”)
|
以什么字符开头
|
|
endswith
|
filter(title__endswith=”天”)
|
以什么字符结尾
|
|
isnull
|
filter(title__isnull=False)
|
是否为null
|
|
isnotnull
|
filter(title__isnotnull=False)
|
是否不是null
|
|
iexact
icontains
istartswith
iendswith
|
|
i的意思是忽略大小写
|
|
in
|
filter(id__in=[1,2,3,4])
|
是否在指定范围数据内
|
|
gt
|
filter(id__gt=1)
|
大于
|
|
gte
|
filter(id__gte=1)
|
大于等于
|
|
lt
|
filter(id__lt=2)
|
小于
|
|
lte
|
filter(id__lte=2)
|
小于等于
|
|
year、month、day、week_day、hour、minute、second
|
filter(pub_date__year=2022)
|
对日期类型数据进行处理
|