6、并发编程六
多进程
多进程实现
进程间同步
进程间同步锁
Pool进程池
同步阻塞
结合多线程
异步非阻塞
回调函数
多进程多线程
CPU密集型(CPU bound)
I/O密集型(I/O bound)
多进程和多线程与CPU核心数的关系
两者选择
僵尸进程
孤儿进程
守护进程
concurrent
ThreadPoolExecutor
ProcessPoolExecutor
上下文管理
多进程实现
进程间同步
进程间同步锁
Pool进程池
同步阻塞
结合多线程
异步非阻塞
回调函数
多进程多线程
CPU密集型(CPU bound)
I/O密集型(I/O bound)
多进程和多线程与CPU核心数的关系
两者选择
僵尸进程
孤儿进程
守护进程
concurrent
ThreadPoolExecutor
ProcessPoolExecutor
上下文管理
多进程
Python中的多进程最大的好处就是能够充分利用多核CPU的资源,不像Python中的多线程,受制于GIL锁的限制,从而只能进行CPU分配,在Python的多进程中,适合于所有的场合,能用多线程的,那么基本上就能用多进程。
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来创建一个线程,启动线程,其实在多进程编程multiprocessing中,存在一个进程类Process,也可以使用那集中方法来使用;
在多线程中,内存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共享的数据;
在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图;
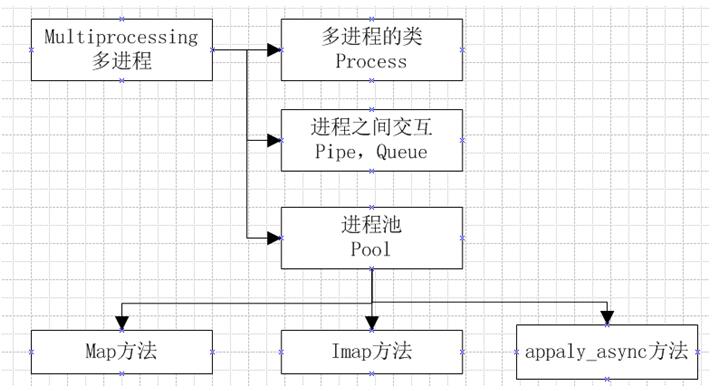
多进程实现
Python下多进程的实现主要就是multiprocessing中的Process类,Process和多线程的类Thread差不多的方法,两者的接口基本相同,对于Process类来讲,它也有很多的参数、方法和属性,具体如下;
# 常用参数
group : 通过源码来看,该源码无实际用途;
target : 表示该进程所调用的对象,即子进程要执行的任务;
args : 表示调用对象的位置参数,元组形式;
kwargs : 表示调用对象的字典,字典形式;
name : 为子进程的名称;
# 常用方法
start() : 启动子进程,并调用该子进程中的run()方法;
run() : 进程启动时运行的方法,它会在子进程中调用target指定的函数,同时,自定义类的类中一定要实现该方法;
terminate() : 强制终止子进程,不会进行任何清理操作,如果创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果该进程还保存了一个锁那么也将不会被释放,进而导致死锁;
is_alive() : 如果进程仍然运行,返回True;
join([timeout]) : 主线程等待子进程终止(强调:是主线程处于等的状态,而子进程是处于运行的状态),timeout是可选的超时时间;
# 常用属性
daemon : 默认值为False,如果设为True,代表子进程为后台运行的守护进程,当子进程的父进程终止时,子进程也随之终止,需要注意的是,开启守护进程的子进程内,不能创建自己的新进程,必须在子进程start()之前设置;
name : 进程的名称;
pid : 进程的pid;
exitcode : 进程在运行时为None、如果为–N,表示被信号N结束(了解即可);
authkey : 进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可); 如下代码,在多线程情况下,该代码需要耗时21秒,那么换到多进程的情况下,只需要6秒,得到的非常大的提升,这才是Python中的真并行,真正的做到了充分利用服务器的最大性能;
但需要再次强调的一点是,进程与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内,此外,因为Process类并没有提供一个获取进程PID的方式,所以我们可以通过os.getpid()来获取当前进程的PID号;
def calc():
sum=0
for i in range(90000000):
sum+=1
process_list=[]
start=datetime.datetime.now()
for _ in range(4):
process_obj=multiprocessing.Process(target=calc)
process_list.append(process_obj)
process_obj.start()
for process in process_list:
process.join()
print((datetime.datetime.now()-start).total_seconds())
# 5.92691 上述的代码会创建四个进程,每个进程里面只有一个主线程,这四个主线程分别在多棵CPU之上并行计算,但是需要知道的是,他们并非一直都在一颗CPU之上,这四个CPU在不停的切换,也就是说当CPU时间片完成之后,又会切换到另一个CPU之上运行;
一般来讲,如果计算机之上有8核心的CPU,这四个进程会在这8个CPU之间不停的切换,每个CPU都会获得一段处理时间,这样是有好处也会坏处,好处是它更好的利用了闲置的CPU进行调度,但是它也有它的坏处,它从CPU1切换到CPU2的时候,有一部分的缓存数据就失效了,所以,这种在不同的CPU之间切换是有好处也有坏处的,这也是以后我们要解决的一个问题的,我们更加期望它在一个CPU上就不要来回切换了,即绑定CPU,这个我们称之为CPU亲缘性,比如进程1绑定在CPU1之上,进程2绑定在CPU2上,这样可以减少在不同的CPU之间切换造成的性能损失;
那么针对多进程,其实不推荐使用在IO密集型,IO密集型更加适用于多线程,虽然说遇到IO会阻塞,这样不管是多进程还是多线程在遇到IO时都不会调度,看似使用多进程行,但其实不好,因为进程代价太高,因为以前在同一个进程里面操作就是为了共享进程资源,现在跨进程共享就不太方便了,所以说,如果想在进程内共享资源,而这个任务又是IO密集型的,其实建议使用一个进程多个线程,这样是比较合适的,代价会更小;
上述代码是创建进程的一种常见方式,直接调用相关模块类即可,那么我们的多进程和多线程其实是一样的,也可以通过继承的方式去创建多进程,如下示例;
class Calc(multiprocessing.Process):
def __init__(self,sum):
super().__init__()
self.sum=sum
def run(self):
print(os.getpid())
for i in range(90000000):
self.sum+=1
print(self.sum)
p1=Calc(0)
p2=Calc(0)
p3=Calc(0)
p4=Calc(0)
p1.start()
p2.start()
p3.start()
p4.start()进程间同步
在Python中的多进程也是可以抢资源的,多进程抢资源它用到技术和多线程其实差不太多,multiprocessing这个模块下面都有,但是进程间的代价是要高于线程的,而且系统底层的实现是完全不同的,只不过Python屏蔽了这些差异,让用户简单使用多进程,但是底层的原理不一样,调用的系统调用是不一样的;
multiprocessing还提供了进程间共享内存、服务器进程来共享数据,甚至还提供了用于进程间通讯的Queue队列、Pipe管道等多种不同的通信方式,需要注意的是这个Queue不是Queue模块下的queue,那个queue是线程下面使用的,这是两个东西,但是他们的方法几乎都一样,因为Python都已经伪装好了,但需要注意,他们之间但逻辑完全不同;
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最⼤可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
Queue.qsize():返回当前队列包含的消息数量;
Queue.empty():如果队列为空,返回True,反之False;
Queue.full():如果队列满了,返回True,反之False;
Queue.get(block, timeout):获取队列中的⼀条消息,然后将其从列队中移除,block默认值为True。如果block使⽤默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为⽌,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出Queue.Empty异常;如果block值为False,消息列队如果为空,则会⽴刻抛出Queue.Empty异常;
Queue.get_nowait():相当Queue.get(False);
Queue.put(item, block, timeout):将item消息写⼊队列,block默认值为True,如果block使⽤默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写⼊,此时程序将被阻塞(停在写⼊状态),直到消息列队腾出空间为⽌,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出Queue.Full异常;如果block值为False,消息列队如果没有空间可写⼊,则会⽴刻抛出Queue.Full异常;
Queue.put_nowait(item):相当于Queue.put(item, False);def write_task(queue,count): # 队列生产者
for i in range(count):
if queue.full():
break
queue.put(i)
def read_task(queue): # 队列消费者
while True:
print(queue.get()) # 如果队列中没有数据,那么就阻塞
queue=multiprocessing.Queue()
pw=multiprocessing.Process(target=write_task,args=(queue,5))
pr=multiprocessing.Process(target=read_task,args=(queue,))
pw.start()
pr.start()
# 0
# 1
# 2
# 3
# 4进程间同步锁
前面我们实现了进程的并发,进程之间的数据是不共享的,但是我们可以通过其他的第三方手段或者Queue来实现数据的共享,但是这样也带来了一个问题,如果我们共享的是一个没有线程安全的东西时,因为进程的运行不是同时进行的, 它们没有先后顺序, 一旦开启也不受我们的限制, 当多个进程使用同一份数据资源时, 就会引发数据安全或者数据混乱问题,为了解决这种问题,我们就需要介入锁的手段;
锁是一个非常实用的技术,也在各个技术领域内大批量应用,不论是数据库、中间件、消息队列等等等,使用非常广泛,加锁的时机是非常重要的,凡事存在共享的资源可能会出现争抢的情况下,都可以上锁,从而保证只有一个使用者,可以完全独享这个资源的使用;
那么对于Python的多进程内,和多线程是一样的,他们都提供了各自锁的实现,两者的概念基本上也差不多,但是需要知道的是,两者的底层实现手段是截然不同的,一个是线程,一个是进程,只不过Python将他们之间的不同给我们优化了,Python在multiprocessing下提供了同步锁,在遇到资源竞争时,加入同步锁是能够在绝大成都上给程序提高更好的安全性的;
def worker(lock,queue):
while True:
lock.acquire()
if not queue.full():
time.sleep(0.001)
queue.put(os.getpid())
lock.release()
else:
lock.release()
break
Lock = multiprocessing.Lock()
process_list=[]
queue=multiprocessing.Queue(maxsize=5)
for _ in range(5):
process=multiprocessing.Process(target=worker,args=(Lock,queue))
process.start()
process_list.append(process)
for process in process_list:
process.join()
while not queue.empty():
print(queue.get())
# 26785
# 26786
# 26787
# 26785
# 26788Pool进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。多进程是实现并发的手段之一,需要注意的问题是,进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行);
例如当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个...,每次手动的去限制进程数量却又太过繁琐,此时利用进程池就可以发挥最大的功效;
我们可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数,对于远程过程调用的高级应用程序而言,应该使用进程池,Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程;
# 主要参数
numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值;
initializer:是每个工作进程启动时要执行的可调用对象,默认为None;
initargs:是要传给initializer的参数组;
# 主要方法
apply(func [, args [, kwargs]]) : 在一个池工作进程中执行func(*args,**kwargs),然后返回结果。需要强调的是,此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async();
apply_async(func, args=(), kwds={}, callback=None,error_callback=None) : 在一个池工作进程中执行func(*args,**kwargs),此方法的结果是AsyncResult类的实例,callback是可调用对象,当进程正确完成之后,会执行callback中的函数,该函数接受一个参数,callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。error_callback如果进程中出现错误,那么会调用error_callback这个函数,同样接受一个参数,该参数为字符串异常类型描述;
close() : 正常关闭进程池,调用close()方法后,不会有新的进程启动,它等待正在执行的任务完成之后,关闭进程池;
terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数;
jion() : 等待所有工作进程退出。此方法只能在close()或teminate()之后调用;
# AsyncResul对象方法
get() : 返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发;
ready() : 如果调用完成,返回True;
successful() : 如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常;
wait([timeout]) : 等待结果变为可用;同步阻塞
对于进程池来讲,它提供了两种方式,同步阻塞和异步非阻塞,同步就是函数直到其要执行的功能全部完成时才返回,那么阻塞的意思就是,在同步的结果返回之前不会继续往下执行,如下同步阻塞示例;
def calc():
sum=0
for i in range(90000000):
sum+=1
return sum
for _ in range(4):
pool=multiprocessing.Pool(processes=4,)
result=pool.apply(calc,)
print(result)
pool.close()
# 90000000
# 90000000
# 90000000
# 90000000 可以看到如上代码,根据结果来看,他们是串行的,但是需要知道的它和多线程的串行不一样,多线程是个假并行,相当于串行,但是多线程还有切换的过程,而对于上述的多进程代码结果来看,他们是真串行,没有任何切换,一个进程彻底执行完成之后,才会去执行下一个;
对于这个apply的多进行是一种同步阻塞的运行模式,当第一个apply的多进程执行完成之后,才会apply第二个进程,这就是同步的效果,在第一个apply的进程未执行完成之前,下一个进行是不会进入计算流程的,而是在后台阻塞;
需要注意的是,在多线程Pool的框架下,是没有提供进程返回值的,即exitcode,当然我们也可以通过其他方式拿到,但是一般我们不需要,因为这个进程在这一次计算完成之后,进程不会直接终止,它会回到进程池里,等待下一次调用,达到复用的效果,循环使用,所以我们不太在意进程的返回值,因为进程根本不消亡,只有进程调用close或者terminate的时候,才会消亡 ;
所以我们这个时候更加关心的是,进程里面的这个函数的返回值,因为进程用完就消亡了,我们可以通过函数的返回值做一些任务的判断等操作;
结合多线程
因为使用apply方法会进入同步阻塞的效果,但是需要知道的是,它阻塞的是主进程中的主线程,而非子进程,那么既然是这么一个情况,我们就可以结合多线程的来解决这种阻塞主线程的问题,我们可以开启多个子线程,然后每个子线程里面开辟一个子进程,那么此时,就解决阻塞主线程的情况;
def calc():
sum=0
for i in range(9000000):
sum+=1
print(sum)
pool=multiprocessing.Pool(processes=4,)
def handler():
pool.apply(calc,)
pool.close()
pool.join()
for i in range(4):
threading.Thread(target=handler,).start()
# 9000000
# 9000000
# 9000000
# 9000000异步非阻塞
进程池还给我们提供了一种异步非阻塞的运行方式,就是将进程放在后台执行,并且代码继续往下执行,不会阻塞,但是需要注意的是,这种异步非阻塞的方式,apply_async这个函数结束是直接拿不到进程里面函数的返回值的,返回的是一个apply_async的对象,所以,我们无法通过apply_async的返回值拿到结果;
def calc():
sum=0
for i in range(90000000):
sum+=1
print(sum)
pool=multiprocessing.Pool(processes=4,)
for _ in range(4):
result=pool.apply_async(calc,)
print(result)
pool.close()
pool.join()回调函数
当然了,为了解决这个返回值的问题,apply_async给我们提供了一个一参的callback回调接口,通过回调,在适当的时机,它会帮助我们将这个结果给拿到,如下,通过一个简单的lambda函数来作为callback函数,输出结果值;
def calc():
sum=0
for i in range(90000000):
sum+=1
return sum
pool=multiprocessing.Pool(processes=4,)
for _ in range(4):
pool.apply_async(calc,callback=lambda func_result:print(func_result))
pool.close()
pool.join()
# 90000000
# 90000000
# 90000000
# 90000000多进程多线程
一个cpu同时执行多个线程的过程叫做并发;虽然叫做并发,但在底层CPU每次只能执行一个线程,具体方法是将cpu分成多个时间片段,然后让CPU以这些时间片段为最小单位轮流执行这些线程
多个cpu同时执行多个线程的过程叫做并行,并行才是真正的同时执行多个任务,如果主机只有一个CPU,那么就无法实现并行过程
说的通俗一些,并行与并发只是和cpu的使用数量相关;并发技术目的是增加单个CPU的运行效率,而并行技术的目的是通过增加CPU的核心数量进而增加整体的计算效率;
- 注意一:
多进程就是启动多个解释器进程,进程间通信必须序列化、反序列化; - 注意二:
此外,如果每个进程中没有实现多线程,那么GIL就基本上没什么用了;
CPU密集型(CPU bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高;
I/O密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高;
多进程和多线程与CPU核心数的关系
一般情况下,多线程主要有两种,一种是用户态多线程;一种是内核态多线程,两者的主要区别是能否支持多核下并行运行,第一,同一进程下的用户态多线程,只能在同一个CPU内核上进行计算,第二,同一进程下的内核态多线程(java1.2之后用内核级线程),在操作系统内核的支持下可以在多核下并行运行;
由于 Python GIL(全局解释锁)的存在,使得 Python 同一个时刻只有一个线程在一个CPU内核上执行字节码,无法将多个线程映射到多个CPU内核上,即不能发挥多核CPU的优势;
换句话说,Python同一进程下的多个线程**只能并发执行,不能并行执行**,因此,Python多线程技术对于IO密集型任务的效率提升明显,但对于CPU密集型任务 Python多线程技术的效果较差;
两者选择
因为Python的解释器CPython中使用到了GIL,GIL这个锁是锁线程的,它限制一个进程里面的所有线程只能运行在一颗CPU之上,也就锁说如果在一个进程里面使用多线程时,这些线程是相互竞争这一个CPU的,那么带来的直接结果就是多核CPU不能发挥优势,它和我们串行的执行时间是相当的,它是一种假并行,那么对于IO密集型呢,因为IO密集型中间会有大量的IO请求,从而导致进程进入阻塞态,不管是进程还是线程,他们进入阻塞状态都会放弃CPU的使用权,所以这个时候使用多线程可能更加的好,因为多线程会在一颗CPU来回切换,它与IO密集型程序大量时间都在阻塞态更加的合适,达到充分使用CPU的
那么对于CPU密集型而言来讲,CPython的GIL锁就没什么用了,因为上面也说过GIL是锁线程的,GIL限定一个进程只能在同一时刻只能在一颗CPU上运行,那么针对多进程来讲,由于他们都是单一进程,同时只有一个主线程,所以这个时候,多进程的就可以运行在多个CPU之上同步执行,从而达到并行的结果,所以对于CPU密集型的,多线程的效果更好;
|
对比维度
|
多进程
|
多线程
|
总结
|
|
数据共享、同步
|
数据共享复杂,需要用IPC
数据是分开的,同步简单
|
因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂
|
各有优势
|
|
内存、CPU
|
占用内存多,切换复杂
CPU利用率低
|
占用内存少,切换简单
CPU利用率高
|
线程占优
|
|
创建销毁、切换;
|
创建销毁、切换复杂,速度慢
|
创建销毁、切换简单,速度很快
|
线程占优
|
|
编程、调试
|
编程简单,调试简单
|
编程复杂,调试复杂
|
进程占优
|
|
可靠性
|
进程间不会互相影响
|
一个线程挂掉将导致整个进程挂掉
|
进程占优
|
|
分布式
|
适应于多核、多机分布式
|
适应于多核分布式
|
进程占优
|
僵尸进程
一个进程真正的执行指令是在这个进程的主线程中,也就是说,在一个进程中的主线程去创建另一个进程,就相当于,有父子进程关系了,当前进程是父,创建出一个新的进程是子,那么在Linux当中需要使用fork对主进程分个叉,来创建子进程,那么当一个子进程由于某种原因终止时,或者其指令执行完成,此时这个进程会进入一种状态,即僵死状态 (zombie),这个时候就在等,等创建这个子进程的进程还要做一件事,就是父进程需要调用一个wait或者waitpid,去扫描一下子进程是否存在未清理的一些数据结构,如果存在就清理掉,然后消亡这个进程;
因为进程结束后,内核并不是立即把它从系统中清除 。相反,进程会保持在一种已终止的状态中,直到被它的父进程回收(reaped)。 当父进程回收已终止的子进程时,内核会将子进程的退出状态传递给父进程,然后抛弃已终止的进程,从此时开始,该进程就不存在了 ,一个终止了但还未被回收的进程称为僵死进程 (zombie);
孤儿进程
正常来讲,子进程任务结束时,父进程应该将其回收,但是如果父进程比子进程消亡得早,父进程就无法回收子进程,所以说,这个时候,子进程就变成了孤儿进程,没有父进程去回收它,孤儿进程就很危险了,因为没有进程给它调用wait或者waitpid,所以对于没有进程回收的这种孤儿进程,操作进程会让他成为init的子进程,就说init会成为这个进程的父进程,init负责对子进程进行回收;
守护进程
它是运行在后台的一种特殊进程,它独立于控制终端,并周期性执行某种任务或等待处理某些事件,守护进程的父进程是init进程,起初一个这个守护进程程序会启动一个进程,然后又会开辟一个子进程,最后会将这个子进程的父进程给杀掉,然后将这个子进程的父进程交给init进程,这样的话,它就成为了一个守护进程;
concurrent
在Python3.2之后,又提供了一个新的多进程库,即concurrent,它提供了异步并行任务的编程接口,它主要有两个执行器,即ThreadPoolExecutor和ProcessPoolExecutor异步线程池和异步进程池的Executor;
ThreadPoolExecutor(max_workers=1):池中至多创建max_workers个线程的池来同时异步执行,返回Executor实例;
ProcessPoolExecutor(max_workers=1):池中至多创建max_workers个进程的池来同时异步执行,返回Executor实例;
wait(fs, timeout=None, return_when=ALL_COMPLETED):接受一个元素为future对象的可迭代对象,它判断这个可迭代对象里面的future对象里面的线程是否已经执行完成,有三种选择,即return_when参数,具体看源码;
as_completed(fs, timeout=None):接受一个元素为future对象的可迭代对象,一个一个地等待,future对象里面的线程完成,它返回一个生成器,在没有一个线程或者进程执行完成前,处于阻塞状态,完成一个返回一个;ThreadPoolExecutor
线程池类似迅雷下载,当同时下载1000个任务甚至更多的时候,就算开通vip同时下载的数量也只有8个。如果同时创建1000个线程,首先对计算器的开销也很大,而且每次只运行8个线程,需要不停的创建和销毁,这样会显得很麻烦;
而使用线程池ThreadPoolExecutor就可以解决上面的问题,其实只需要8个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行,这就是所谓的线程池;ThreadPoolExecutor原理;
submit(fn,*args,**kwargs):提交线程需要执行的函数及其参数,返回Future类的实例;
shutdown(wait=True):清理进程池,wait为True表示池清理干净才退出;
# Future方法
done():如果调用被成功取消或者执行完成,则返回True,需要注意的是,任务异常终止也算finished;
cancelled():如果调用被成功的取消,则返回True;
running():如果正在运行且不可取消,则返回True;
cancel():尝试取消调用,只能取消pending状态的进程或者线程,取消成功返回True,否则返回False;
result(timeout=None):取返回结果,timeout为None时会一直等待返回,timeout如果设置等待时,时间到还未拿到返回结果抛出concurrent.futures.TimeoutError异常,需要注意的是,虽然result能返回执行结果,但是它是会阻塞的;
exception(timeout=None):取返回结果,timeout为None时会一直等待返回,timeout如果设置等待时,时间到还未拿到返回结果抛出concurrent.futures.TimeoutError异常,同时,如果内部异常,exception也可以拿到异常信息; 如下就是ThreadPoolExecutor创建的一个线程案例,可以看到,三个线程都是并行执行的,并且,如果我们将任务数量加大,每次最大只可以开辟三个线程,多余的线程只能等待;
def worker(n):
print("enter thread")
time.sleep(n)
print(threading.enumerate())
print("finished")
executor=ThreadPoolExecutor(max_workers=3)
for _ in range(10):
future=executor.submit(worker,2)
time.sleep(1)
print(threading.enumerate())
# enter thread
# enter thread
# enter thread
# [<_MainThread(MainThread, started 140734813474240)>,
# <Thread(Thread-1, started daemon 123145343614976)>,
# <Thread(Thread-2, started daemon 123145348870144)>,
# <Thread(Thread-3, started daemon 123145354125312)>] 那么如果我们如果开辟了多个线程,我们又需要在这多个线程执行完毕之后,去做一些事,我们可以借助内建函数all来实现,如下;
def worker(n):
time.sleep(n)
executor=ThreadPoolExecutor(max_workers=3)
future_list=[]
for _ in range(3):
future=(executor.submit(worker,2))
future_list.append(future)
while True:
states=[state.done() for state in future_list]
print(states)
if all(states):
print("done...")
break
time.sleep(1)
# [False, False, False]
# [False, False, False]
# [True, True, True]
# done... 那么对于以上的需求,需要等待所有线程执行完成,其实concurrent还给我们提供了一个更加简便的一个类库,即concurrent.futures.wait,它接受一个元素为future对象的可迭代对象,和一个等待条件,默认等待条件为ALL_COMPLETED,ALL_COMPLETED就是说等待所有的线程执行完成,也可以是FIRST_COMPLETED第一个任务完成,和FIRST_EXCEPTION出现了第一个异常;
concurrent.futures.wait返回为一个对象,这个对象里面有两个集合,第一个集合为done,表示已经done的线程future对象,第二个集合为not_done表示还未done的线程future对象,具体的查看源码;
def worker(n):
time.sleep(n)
executor=ThreadPoolExecutor(max_workers=3)
future_list=[]
for _ in range(3):
future=(executor.submit(worker,2))
future_list.append(future)
done,not_done=wait(future_list,return_when=ALL_COMPLETED)
print(done) # {<Future at 0x106455b00 state=finished returned NoneType>, <Future at 0x1060eb3c8 state=finished returned NoneType>, <Future at 0x1060ade80 state=finished returned NoneType>}
print(not_done) # set() 可以看到上面的wait,它只有三种选择,要么所有线程全部完成,要么第一个完成,要么出现一个异常,那么对于concurrent库,还给我们提供了一种方法,即as_completed,它接受一个元素为future对象的可迭代对象,这个可迭代对象里面的future对象没有done之前会一直处于阻塞状态;
as_completed返回一个生成器,在任务没有完成之前,会阻塞,如果有某个任务完成,会yeild这个任务,就能继续执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束,从结果可以看出,先完成的任务会先通知主线程,那么对于wait来讲,as_completed是来一个获取一个,而wait是等待所有线程执行完成;
def worker(n):
time.sleep(n*3)
executor=ThreadPoolExecutor(max_workers=3)
future_list=[]
for i in range(3):
future=(executor.submit(worker,i))
future_list.append(future)
for completed in as_completed(future_list):
print(completed.done())
# True
# True
# TrueProcessPoolExecutor
对于ProcessPoolExecutor来讲,它和ThreadPoolExecutor是一摸一样的,Python给我们包装得在使用层面没有任何差异,只不过一个是开辟线程池,一个是开辟进程池,所以都说Python简单,Python的简单是在于它将语法给我们封装简单的,甚至于进程池和线程池这么复杂的东西,都给我们包装成了统一的调用接口,所以这就是Python好用的地方;
但是我们需要知道的是,进程池和线程池是完完全全不一样的哦,只不过Python提供了这种语法的友好性,背后原理并不简单;
上下文管理
在上面的代码,我们都没有提到垃圾清理,池子用完了之后,我们必须清理掉,不然就容易会造成大量内存的泄露,我们可以直接调用shutdown方法来清理线程池或者进程池;
那么对于ThreadPoolExecutor和ProcessPoolExecutor来讲,我们可以通过他们的基类看到,基类提供了上下文管理,所以我们可以直接调用其上下文管理接口,在这个上下文管理的__exit__方法我们可以明确的看到,它调用了指定进程或者线程的shutdown方法,所以我们可以直接调用其上下文管理接口,来清理线程池或者进程池,如下;
def worker(n):
time.sleep(n*3)
with ProcessPoolExecutor(max_workers=3) as executor:
future_list=[]
for i in range(3):
future=(executor.submit(worker,i))
future_list.append(future)
for completed in as_completed(future_list):
print(completed.done())
print(threading.enumerate())
# True
# True
# True
# [<_MainThread(MainThread, started 140734964358592)>] # 最后仅剩下一个主进程的主线程