7、面向对象高级应用一
描述器协议
无描述器
非数据描述器
非数据描述器重点
数据描述器
获取属主类描述器标识符
案例
property实现的印证
staticmethod的实现
classmethod的实现
实现参数检查
tracemalloc
slots
Python的对象模型
无描述器
非数据描述器
非数据描述器重点
数据描述器
获取属主类描述器标识符
案例
property实现的印证
staticmethod的实现
classmethod的实现
实现参数检查
tracemalloc
slots
Python的对象模型
描述器协议
在Python中描述器也被称为描述符,"描述器是两个类之间的关系",描述器实际上是任何新式类(新式类是继承自 type 或者object的类),这种描述器类,有三个魔术方法__get__, __set__, __delete__。这三个魔术方法充当描述器协议的作用。
在Python中,同时实现了__get__和__set__的类被称为数据描述器(data descriptor)。只实现了 __get__方法的类是非数据描述器(non-data descriptor),非数据描述器常用于方法,当然其他用途也是可以的,如果一个类的类属性设置为描述器实例,那么这个类被称之为owner属主类,当该类的类属性被查找、设置、删除时,就会调用描述器相应的方法。
描述器功能很强大,且应用广泛,它可以控制我们访问属性、方法的行为,比如之前使用的property、super、staticmethod、classmethod甚至属性以及实例背后的实现机制大部分都是描述器的实现,这些都是比较底层的设计,描述器在Python自身中广泛使用。描述器简化了底层的C代码,并为Python的日常编程提供了一套灵活的新工具。
object.__get__(self,instance,owner)
object.__set__(self,instance,value)
object.__delete__(self,instance)
# 参数详解
# self:代指当前类的实例,即描述器的实例;
# instance:instance是owner的实例;
# owner:owner是属性的所属的类;
# 可以看到__get__或者__set__他们的形参,不仅有self还有instance,在面向对象里面,self实际就是当前实例的instance,那么这里又多出一个instance,由此可以看出,这是两个类之间的调用;无描述器
如下,当A和B类定义的时候,变量会先生成,而B类的x属性是A类的实例,所以当B类定义时,会创建A类实例时,所以也会打印出A init,然后执行到B.x.a1,接下来实例化B,从而打印b.x.a1,会查找到b实例的B类的类属性,它指向A实例,所以返回的就是A实例的属性a1的指;
class A:
def __init__(self):
self.a1='a1'
print("A init")
class B:
x=A()
def __init__(self):
print("B init")
print(B.x.a1)
b=B()
print(b.x.a1)
# A init
# a1
# B init
# a1非数据描述器
上面示例是没有加入描述器的结果,如果加入描述器结果就完全不同了,上面也说过,同时实现了__get__和__set__的类被称为数据描述器(data descriptor),只实现了__get__方法的类是非数据描述器(non-data descriptor)。
如下就是一个非数据描述器,当属主类调用描述器类时,可以看到,访问B.x的时候返回的是None,正常逻辑下返回的是A的实例对象,这是因为,描述器影响了属性的搜索顺序,当类加入描述器时,此应用场景下,对A类实例属性的访问会转为对A类的__get__方法的访问。
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print(self,instance,owner)
class B: # 属主类,即owner
x=A()
def __init__(self):
print("B init")
print(B.x) # 当访问属主类中的描述器属性时,会转为描述器类的__get__方法,所以访问B.x的返回结果为None
# A init
# <__main__.A object at 0x102e5ae80> None <class '__main__.B'>
# None 可以看到上述情况,返回为None,因为当一个类加入描述器之后,对该类的访问首先过经过__get__描述器方法,所以,描述器类的__get__方法在此种场景下应该返回一个A的实例,即self,这样,当访问B.x时,经过__get__方法,才会拿到一个A的instance,如下就是改进版;
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print(self,instance,owner)
return self
class B:
x=A()
def __init__(self):
print("B init")
print(B.x)
# A init
# <__main__.A object at 0x102c7ae80> None <class '__main__.B'>
# <__main__.A object at 0x102c7ae80> # 拿到了一个A的实例对象 可以看到上述代码的14行,A类的__get__方法返回的instance是None,而owner则是B类,由此可以推断出来,__get__的instance应该是B类的实例,换一句话说,只有通过B类的实例访问时,instance才会有值,事实也正是如此;
可以看到下述案例,当我们将A类的__get__方法的返回值设定为self时,在下面使用b.x调用__get__方法,打印出来的instance参数则是一个对象,已经不再是None;
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print(self,instance,owner)
return self
class B:
x=A()
def __init__(self):
print("B init")
b=B()
print(b.x)
# A init
# B init
# <__main__.A object at 0x102e7ae80> <__main__.B object at 0x104806f28> <class '__main__.B'>
# <__main__.A object at 0x102e7ae80>非数据描述器重点
需要注意的是,要使用描述器,还必须在owner属主类的类属性添加描述器实例,如果将其设定为属主类的实例属性,将不走描述器协议,必须将其设定为类属性,才会走描述器。
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print(self,instance,owner)
return self
class B:
def __init__(self):
self.x=A()
print("B init")
b=B()
print(b.x) # 一旦描述器存在于属主类的实例属性时,将不会走描述器,所以它就按照正常流程走,直接返回了一个A的实例,并没有走描述器类的__get__方法
# A init
# B init
# <__main__.A object at 0x102b63748>总结:当属主类的实例调用描述器类时,使用实例访问和使用类访问是有区别的,在描述器类的描述器的__get__魔术方法中,self为描述器类的实例,而owner则是属主类,那么instance则是属主类的实例,使用属主类的类访问,描述器将无法获知instance,如果用属主类的instance访问,则描述器可获取到owner和instance,并且,描述器一般需要返回self,也就是描述器类的实例
数据描述器
在Python中,如果一个类实现了__get__、__set__、__delete___三个方法中的任何一个方法,它就是描述器,支持了描述器协议,如果仅实现了__get__方法,就是非数据描述器(non-data descriptor),如果实现了__get__和__set__就是数据描述器(data descriptor)。
如果一个类的类属性设置为描述器实例,那么它被称之为owner属主,当该类的类属性被查找、设置、删除时,就会调用描述器相应的方法。
当我们在一个类里面实现了__get__、__set__或者__delete__方法,那么这就是一个数据描述器,如下就是一个数据描述器,为了测试数据描述器的效果,在B实例初始化方法中加入了self.x(与类属性描述器同名)属性,这里会有很大的不同,如下。
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print("get",self,instance,owner)
return self
def __set__(self, instance, value):
print("set",self,instance,value)
class B:
x=A()
def __init__(self):
self.x=1
print("B init")
b=B()
print(b.x)
# A init
# set <__main__.A object at 0x10267ae48> <__main__.B object at 0x10580f4e0> 1
# B init
# get <__main__.A object at 0x10267ae48> <__main__.B object at 0x10580f4e0> <class '__main__.B'>
# <__main__.A object at 0x10267ae48>通过断点分析,可以看到当属主类的类属性x为"数据描述器"时,属主类就不再是一个简单的类了,因为描述器类实现了__set__方法,所以属主类,就为一个数据描述器,上述案例,属主类类属性的x属性为一个数据描述器,然后又在B初始化函数加入了self.x的赋值语句,此时,数据描述器就会影响这么一个操作。
官方给的结论是,数据描述器的优先级高于实例的__dict__的,也就是不会将self.x写到实例的__dict__里面,会直接调用数据描述器的__set__()方法,所以下面我们打印b.__dict__时就得到了一个空字典{}。如果属主类类属性有一个名为x的描述器,当属主类设置一个同名实例属性x并对其赋值时,会调用类属性x这个描述对象的__set__()方法,也就是说如果属主类的一个实例属性,存在一个同名的类属性描述器的话,这个实例属性就不会写到实例__dict__里面去,他们之间的优先级是数据描述器 > instance.__dict__ > 非数据描述器,数据描述器优先级最高,所以,在当打印B的实例字典,会发现,实例字典为空,因为根本就没走实例字典,而是调用的数据描述器的__set__方法。
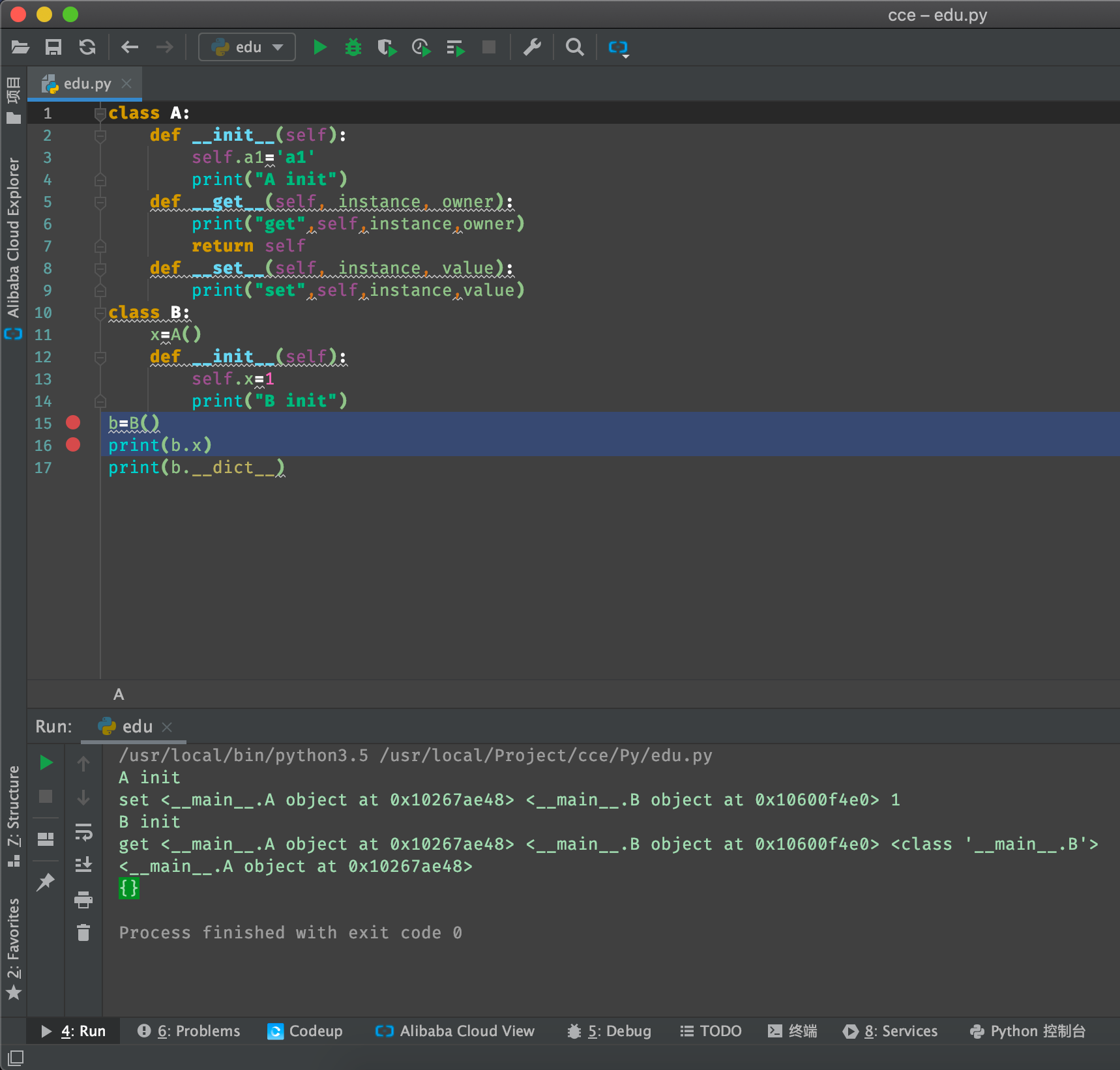
上述只是在__init__初始化函数中赋值了一个与类属性描述器同名的实例属性时会调用数据描述器的__set__方法,其实,我们在外部对属主类的实例进行赋值时(赋值的实例属性和类描述器属性同名),也是一样的,总而言之,如果一个属主类存在一个数据描述器的类属性,不论是在类外部,还是在类内部,创建一个与类描述器属性同名的实例属性,都会调用数据描述器的__set__方法。
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print("get",self,instance,owner)
return self
def __set__(self, instance, value):
print("set",self,instance,value)
class B:
x=A()
def __init__(self):
print("B init")
b=B()
b.x=1
# A init
# B init
# set <__main__.A object at 0x102d83dd8> <__main__.B object at 0x10580f4e0> 1 如果我们期望在属主类的实例b的实例字典里面存在x=1这一项,那么其实我们可以在数据描述器的__set__方法中来设置,因为在最上面就说过,描述器的instance形参,代表的就是属主类的实例,所以我们可以直接将这个属性加入到这个实例当中,但是需要注意的是,不能使用反射的方式来实现,不然会进行无限递归的情况。
无限递归的原因是因为,上面例子的逻辑,对一个属主类实例设置一个和数据描述器同名的实例属性会访问描述器的__set__方法,如果在__set__方法里面又使用instance.x="xx"或者使用setattr(instance,x,'xxx'),那么属主的实例又赋值了,又会调用数据属性的__set__方法,所以此时,我们尽量使用字典的方式将输入加入到属主的实例字典。
需要知道的是,即使我们将这个属性加入到了属主类的实例字典,也没法使用,因为数据描述器的优先级最高,所以在使用b.x访问的时候,依旧还是访问的描述器的__get__方法,所以即使我们将这个属性加入到实例字典,也没法使用;
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print("get",self,instance,owner)
return self
def __set__(self, instance, value):
print("set",self,instance,value)
instance.__dict__['x']=value # 使用字典的方式,将属性加入属主的实例字典
class B:
x=A()
def __init__(self):
self.x=1
print("B init")
b=B()
print(b.x)
print(b.__dict__) # {'x': 1} 可以看到,对于数据描述器而言,不论是在属主类内部,还是外部,赋值一个与类描述器属性同名的实例属性都没什么太大意义,即使我们强行将这个属性加入到属主类实例的实例字典,我们也无法使用,因为数据描述器的优先级最高。
那么我们就可以做这么一个操作,因为不论是外部还是内部,只要对数据描述器进行"赋值"操作都会调用__set__方法,那么此时,我们可以在__set__方法内部进行一个处理,在数据描述器的情况下,显示的告诉用户,不允许修改数据描述器;
class A:
def __init__(self):
self.a1='a1'
print("A init")
def __get__(self, instance, owner):
print("get",self,instance,owner)
return self
def __set__(self, instance, value):
if instance: # 只要instance不为空,就说明是在修改描述器,只要是在修改,就显示告诉用户,不允许修改
raise AttributeError("can't set attribute")
class B:
x=A()
def __init__(self):
print("B init")
b=B()
b.x=1
# A init
# B init
# Traceback (most recent call last):
# File "/usr/local/Project/cce/Py/edu.py", line 22, in <module>
# b.x=1
# File "/usr/local/Project/cce/Py/edu.py", line 16, in __set__
# raise AttributeError("can't set attribute")
# AttributeError: can't set attribute总结:对于描述器来讲,如果是非数据描述器,实例属性的查找顺序,和之前一样,规则为,非数据描述器 < instance.__dict__,而数据描述器优先级很高,比instance更高,所以一旦有了数据描述器,实例的查找顺序将会变化,不按照原来的方式查找,规则为:数据描述器 > instance.__dict__ > 非数据描述器;
获取属主类描述器标识符
在Python3.6中新增了一个描述器方法,即__set_name__,这个方法在描述器创建时,它就会调用,__set__、__get__、__delete__都是后面的事,__set_name__属性可以在描述器中,获取到属主类描述器的标识符。一个描述器只为一个类属性服务,如果遇到一个属主类下面有多个描述器的类属性,此时,我们就可能很难知道目前是为哪一个类属性服务了,所以__set_name__就是为了解决这个问题,可以知道此次调用描述器的属性是谁
class A():
def __get__(self, instance, owner):
return self
def __set_name__(self, owner, name):
print("__set_name__",name)
self.name = name
class B():
x=A()
print(B.x)
print(B.x.name)
# __set_name__ x
# <__main__.A object at 0x1101cdd90>
# x案例
其实,在Python内部,不论是property,还是staticmethod、classmethod,他们底层的实现逻辑其实就是利用描述器来实现的,property为数据描述器,经过property修饰的方法,不允许修改,而staticmethod、classmethod他们都是非数据描述器,如下示例。
class A():
def __init__(self):
self.stmd=100
self.clmd=200
@staticmethod
def stmd(self):
pass
@classmethod
def clmd(cls):
pass
a=A()
print(a.stmd,A.stmd) # 100 <function A.stmd at 0x10580aa60>
print(a.clmd,A.clmd) # 200 <bound method A.clmd of <class '__main__.A'>>
# 类和实例相互不影响,即非数据描述器property实现的印证
property的实现在上面数据描述器的案例中,上述在__set__方法中设置属性不允许修改,修改就抛出AttributeError("can't set attribute")其实就是property,使用property去修饰一个方法时,如果在实例里面新增一个和property修饰的方法的方法名同名,就会抛出AttributeError("can't set attribute"),如下。
class A():
@property
def get(self):
pass
a=A()
a.get="cce"
# Traceback (most recent call last):
# File "/usr/local/Project/cce/Py/edu.py", line 12, in <module>
# a.get="cce"
# AttributeError: can't set attributestaticmethod的实现
staticmethod内部就是一个非数据描述器,所以它只需要一个__get__方法就可以了,如下示例。
class StaticMethod(object):
def __init__(self,func):
self.func=func
def __get__(self, instance, owner):
return self.func
class A:
@StaticMethod # 等价于 stmd=StaticMethod(stmd), 所以stmd是一个类属性描述器
def stmd(x,y):
print(x+y)
a=A()
a.stmd(4,5)
# 9 在装饰器环节就说过上述的@StaticMethod等价于stmd=StaticMethod(stmd),所以StaticMethod这个类的初始化方法,应该会接受一个参数,所以在StaticMethod的初始化方法__init__就需要接收一个参数,在此种情况下,该参数为一个函数。
然后执行到a.stmd(4,5)时,我们要分两步看,第一步是a.stmd,它是去在a的实例字典里面寻找stmd属性,第二步是(4,5)。
第一步,我们在外部使用属主类的实例来调用了a.stmd属性,因为类属性stmd是一个描述器,所以它会去寻找描述器的__get__方法,然而,__get__方法返回一个函数,这个函数实际上就是原来A类的stmd方法,所以使用a.stmd返回的是一个函数的内存地址,然后到了第二部,此时的a.stmd是一个函数的内存地址,这个函数还接收两个参数,所以当这个函数的内存地址加上(4,5)时,就直接以函数的方式执行了,所以得到了结果9。
- 总结:
实际上这就是staticmethod的原理,无非就是在描述器里面转了一圈;
classmethod的实现
classmethod和staticmethod类似,只不过它比staticmethod稍微复杂的一点点,它利用到了偏函数,如下示例。
from functools import partial
class ClassMethod(object):
def __init__(self,func):
self.func=func
def __get__(self, instance, owner):
return partial(self.func,owner) # 或者使用 wraps(self.func)(owner)或者自定义偏函数
class A:
@ClassMethod # 等价于 stmd=ClassMethod(stmd), 所以foo是一个类属性描述器
def foo(cls,x,y):
print(cls,x,y)
A.foo(1,2)
# <class '__main__.A'> 1 2 可以看出来classmethod和staticmethod是很类似的,不同的地方仅仅在于classmethod装饰的方法,需要三个参数第一个参数为cls(调用者的属主),但是我们在调用classmethod修饰的函数时,只传递两个参数,所以,此时就要用到偏函数,固定第一个参数为owner,然后将固定参数后的函数返回,从而就实现了classmethod。
- 总结:
可以看到,在Python的面向对象中类方法装饰器和静态方法装饰器,其实他们的底层实现就是描述器;
实现参数检查
参数检查是一个数据描述器,因为非数据描述器会将实例属性进行覆盖,所以不适用,将需要检查的参数加入描述器,并进行将其规定的类型作为实参传进去,那么我们在实例化的时候,因为实例化中的属性名与描述器同名,所以此时就会走描述器协议,进入描述器的__set__方法,此时,我们就可以利用__set__方法,来做检测,如果__set__的value类型和规定的类型一致,那么就将其加入属主实例字典中。
同时,因为属主类现在已经是一个描述器类,它的属性查找顺序将不再按照正常的流程走,正常的流程下,是instance.__dict__->parentclass.__dict__->objct.__dict__,当一个实例属性存在一个同名的类属性描述器,将直接走描述器的__get__方法,所以,在描述器的__get__方法,也需要为其设置,获取属性的逻辑;
如下代码是Python3.8实现的,在Python3.6之前没有描述器__set_name__方法;
class TypeCheck(object):
def __init__(self,typ):
self.typ=typ
def __get__(self, instance, owner):
if instance:
return instance.__dict__.get(self.name) # 在使用实例访问时,将对应的属性值抛出
return self
def __set__(self, instance, value):
if instance and isinstance(value,self.typ):
instance.__dict__[self.name]=value
else:
raise TypeError # 如果传入的类型不符合要求,就抛出异常
def __set_name__(self, owner, name):
self.name=name
class A(object):
name = TypeCheck(str)
age = TypeCheck(int)
def __init__(self,name,age):
self.name=name
self.age=age
a=A("cce",18)
print(a.__dict__)
print(a.age)
# {'name': 'cce', 'age': 18}
# 18tracemalloc
对于一个Python的程序来讲,我们可以通过tracemalloc模块来估算程序的内存,它就是将当前程序在内存中拍一个照,得到当下程序所使用的内存快照对象,然后tracemalloc会去对这个快照当前使用的内存信息进行统计。
这个快照对象,存在很多信息,所以我们具体要统计什么信息,需要给定统计的类型,类型有三个,filename、lineno、traceback,其中filename是统计整个文件的内存,lineno则是分开统计,分别告知当前文件的每一行所占用的内存大小。
import tracemalloc
tracemalloc.start() # 开始跟踪内存分配
x = [x for x in range(1000000)]
y = (x for x in range(1000000))
snapshot = tracemalloc.take_snapshot() # 对当前内存拍摄快照
stats = snapshot.statistics("lineno") # 快照对象的统计信息,得到的是一个list
for item in stats:
print(item)
# /usr/local/Project/cce/Py/edu.py:11: size=35.0 MiB, count=999744, average=37 B
# /usr/local/Project/cce/Py/edu.py:12: size=136 B, count=2, average=68 B
# 由此,可以看出,元祖更加省内存slots
__slots__在之前的lru_cache的源码中的_HashedSeq类中有使用,它主要是用来解决字典占用内存较大的问题,对于面向对象而言,实例数据属性都是存储在字典当中的,使用字典的原因也主要是因为提升效率的,因为字典的查找速度极快,所以就用了空间来换时间,那么得到的问题就是如果一个类,创建了数以百万计的实例的时候,内存空间占用会非常之大,虽然类字典只有一个,但是实例的属性字典是可以有千千万万个的,所以这个时候,比较好的解决方法就是不使用这个__dict__字典的形式来存储数据属性。
正因为如此,Python就提出了__slots__的技术,一旦将一个类的类属性加入__slots__时,那么这个类的"实例"将没有__dict__属性,它阻止了实例属性字典的创建,它将属性字典给换掉了,不以字典的方式进行存储,但是需要注意的是,它只会阻止实例的属性字典,而类的属性字典它是无法控制的,所以,__slots__主要是来控制实例的属性字典的。
那么,有了__slots__之后,当我们需要对内存斤斤计较的时候,使用__slots__这个内存的占用就得到了很好的解决,__slots__定义在类级别,作为一个类属性存在,并且它接收一个可迭代对象,比如list、tuple,这个可迭代对象里面存储的就是当前类的实例可以创建的实例属性名称,不在这个对象里面的属性名称,实例将无法创建以该属性名称命名的实例属性。
需要注意一点,__slots__只对当前的类有影响,对于子类是没有影响的,它没有继承的特性。
class A(object):
__slots__ = ['x','y'] # 该类的实例可以创建的实例属性名称列表
def __init__(self):
self.x=1
self.y=2
self.z=3 # z不在__slots__的列表里面,所以当前类在初始化创建实例时,它无法为实例创建z这个实例属性
print(A()) # 同时,A的实例也没有__dict__的属性,实例字典从此消失
# Traceback (most recent call last):
# File "/usr/local/Project/cce/Py/edu.py", line 14, in <module>
# print(A( ))
# File "/usr/local/Project/cce/Py/edu.py", line 13, in __init__
# self.z=3
# AttributeError: 'A' object has no attribute 'z'- 总结:
我们可以理解__slots__是用元组来记录的,它主要是解决大量的实例子字典占用内存的问题,但是,它在内存寻址的时候,没有字典那么快,因为字典是通过hashvalue得到的key然后得到的value,所以说,__slots__一般都是用在内存紧张或者大量的实例创建,并且实例的属性过于简单的场景下;
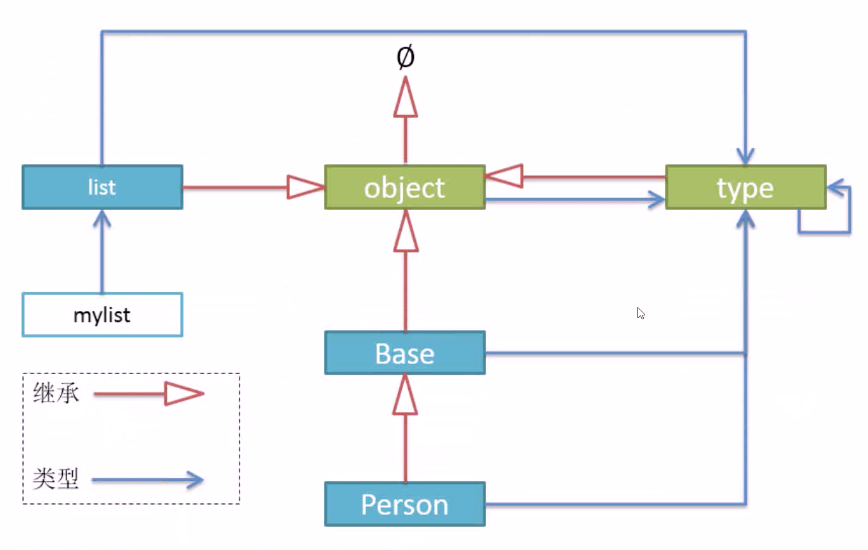
Python的对象模型
如下图,蓝色的单箭头为类型路线,对于一个Base类求type是Type,对于Type求type也是Type,对于一个Object类求Type则为type,所有新式类的缺省类都是type。
红色的单箭头为继承的路线。自定义类继承object,list也继承自object,type类也继承自object,所以对于继承来说,是从object作为基类派生出众多的新式类,而object继承自0(空集),即object就是最顶端,它没有祖先,它就是继承的根基类。
这就是整个Python的继承体系和类型体系,其中最特殊的就是type和object之间形成的环了,object属于type类,type继承自object类。