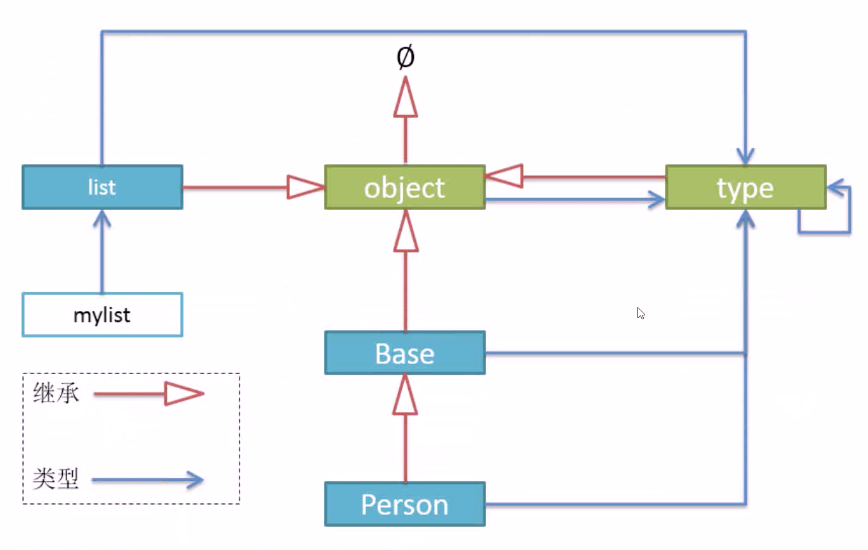
9977b08bed2ecff1447deadf7bff4e52_6141281.png 发表于: 2023年1月30日 2023年1月30日 实际链接 868 × 550 文章导航 发表于7、面向对象高级应用一 cce 142站点RSS订阅