TOC
多继承(Mixin)
在上面讲的面向对象中的继承,是以单一继承为例,因为单一继承相对简单,但是Python又实现了继承中的另一个,即多继承,不是所有语言都实现了多继承,Python实现了,Python在3.x版本当中根父类都是Object,而Python2.x以下都不是这样的,在2.2之前类是没有共同祖先的,之后引入Object类,才有了祖先类。
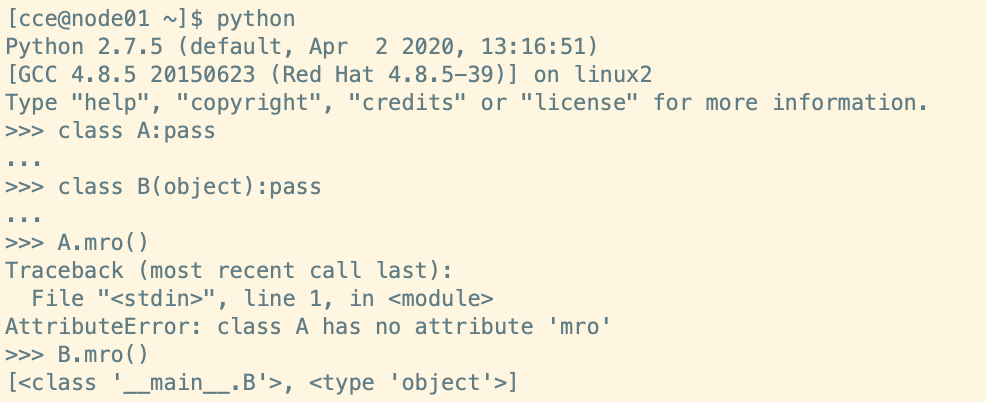
为了版本升级过度,达到新旧共存的目的,在Python2.7支持两种类,古典类(旧式类)和新式类,新式类共同的祖先就是Object,也可以直接使用super在子类中,调用父类,但是如果不知名父类为Object,那么默认为旧式类,而在Python发展到3.x时,已经全部都使用新式类了,如下就是2.7中新式类和旧式类的差别。
按照OCP的原则,即“多用继承,少修改”,多用继承的意思是,子类和父类不一样,如果说一样的话,那倒好办了,直接写个pass就完事儿了,但是现在的问题是,子类在某些方法,和父类就是不一样,那么这个时候,不要直接修改父类,以动物类举例,猫个狗的叫声不一样,这个时候如果我们直接修改了父类的方法,那么对于猫和狗的叫声都变了,所以这个时候,我们应该现继承,将动物类大家共同的东西先继承下来,而后对于那些特有的属性给他在子类中重写覆盖掉,这就是多用的意思。
就是如果发现子类有不同,不要破坏父类,我们应该继承下来一个子类,然后在子类中做覆盖,这就是OCP原则,“多用继承,少修改”,不要修改原来的类,如果有父类,先继承形成一个子类,在子类中覆盖重写,这就是OCP原则,所以继承就是复用代码,子类少写,在子类上实现对基类的增强,从而实现多态。
在继承的环境下,如果父类实现了__init__方法,子类也实现了__init__方法,那么在子类的__init__当中,应该调用父类的__init__方法,除非明确知道,不想调用,否则一般情况下,建议调用,这是一个好习惯。
一个类继承自多个类,就是多继承,在Python中实现多继承也很简单,在继承列表里面多写几个就好了,多继承情况下,子类就有了多个类的特征,多继承是有弊端的,很大的弊端。
虽然多继承更好的模拟了这个大千世界,但是这个时候带来了很多问题,可以看到前面的单一继承,非常简单,如果引入了多继承,也就引入复杂性,越复杂越不可控,带来了很多冲突,比如说,孩子继承自父母的特性,那么他到底像爸还是像妈呢,所以这个时候就带来了一些问题,带来了很多的不确定性和复杂性,所以很多高级语言就舍弃了多继承,C++是有多继承的,Java就舍弃了多继承。
多继承情况下,如果代码写得不够严谨,那就可能会带来二义性的问题,例如猫和狗都继承自动物类,现在如果现在又有一个类继承了猫和狗,如果猫和狗都有shout方法,那这个新的子类到底是使用猫的还是狗的,到底应该用谁的,带来了不确定性。
解决方案
上述讲到了一个二义性的问题,这也是所有语言在多继承的情况下,必须想办法解决的问题,继承会形成一棵树,如果多继承的如果还允许再继续乱继承的话,这个时候就不是一棵树了,而是一个网了,一旦继承变成了一个网的话,而不是一棵树,那么这个关系就乱套了,这个时候别说二义性了,能把关系捋清楚就不错了。
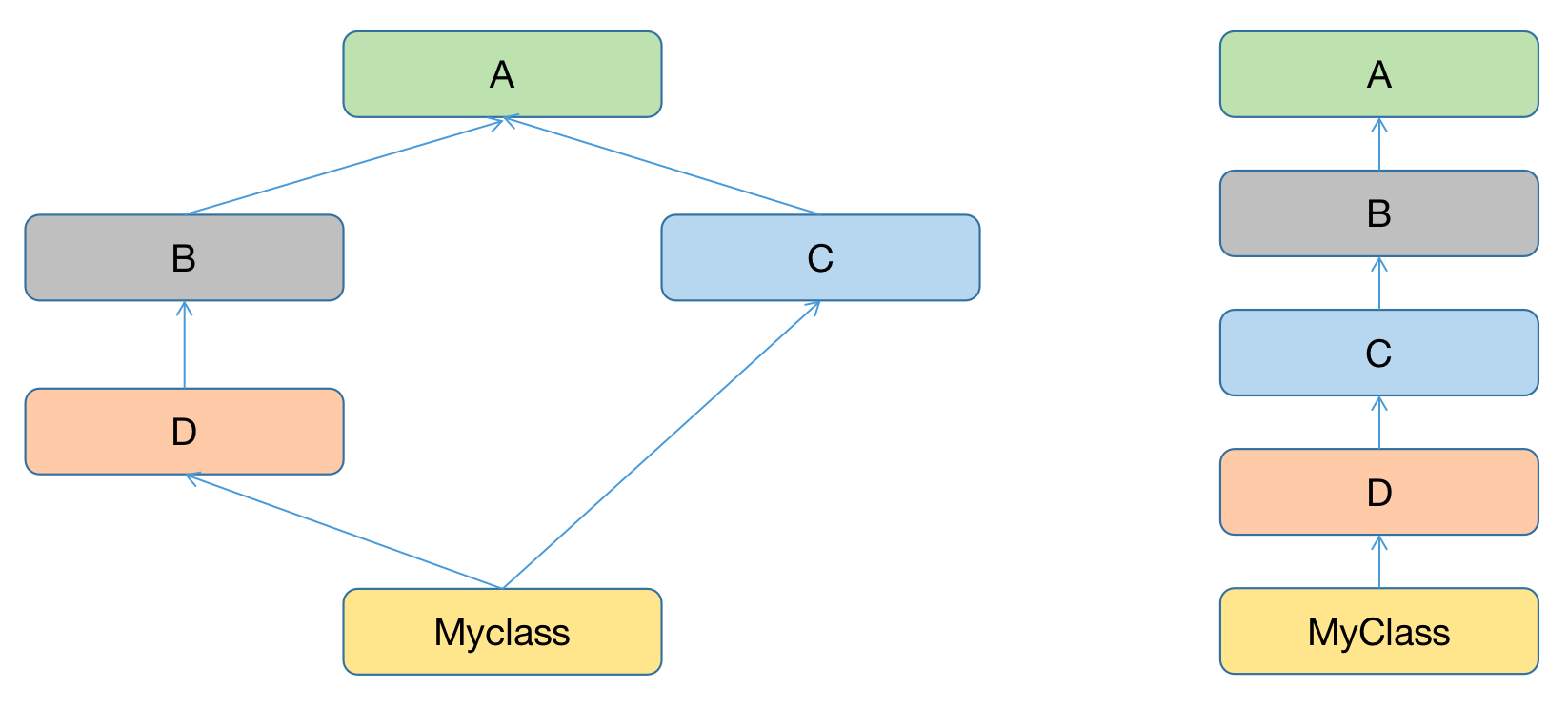
那么为了解决这个问题,不管树还是网,一般都是可以遍历的,遍历的方式就分深度优先还是广度优先,右图为单一继承,而左图则为多继承,还形成了一个菱形继承,这个菱形继承就很好了说明了继承有可能会产生二义性。
像右边就很简单,如果MyClass里面找不到就找D,D找不到就找C以此找到A,如果还找不到就抛出AttributeError,所以单一继承很容易知道它的继承路线,也能够很明确的知道,继承的方法到底是谁的,很明确,没有二义性的存在。
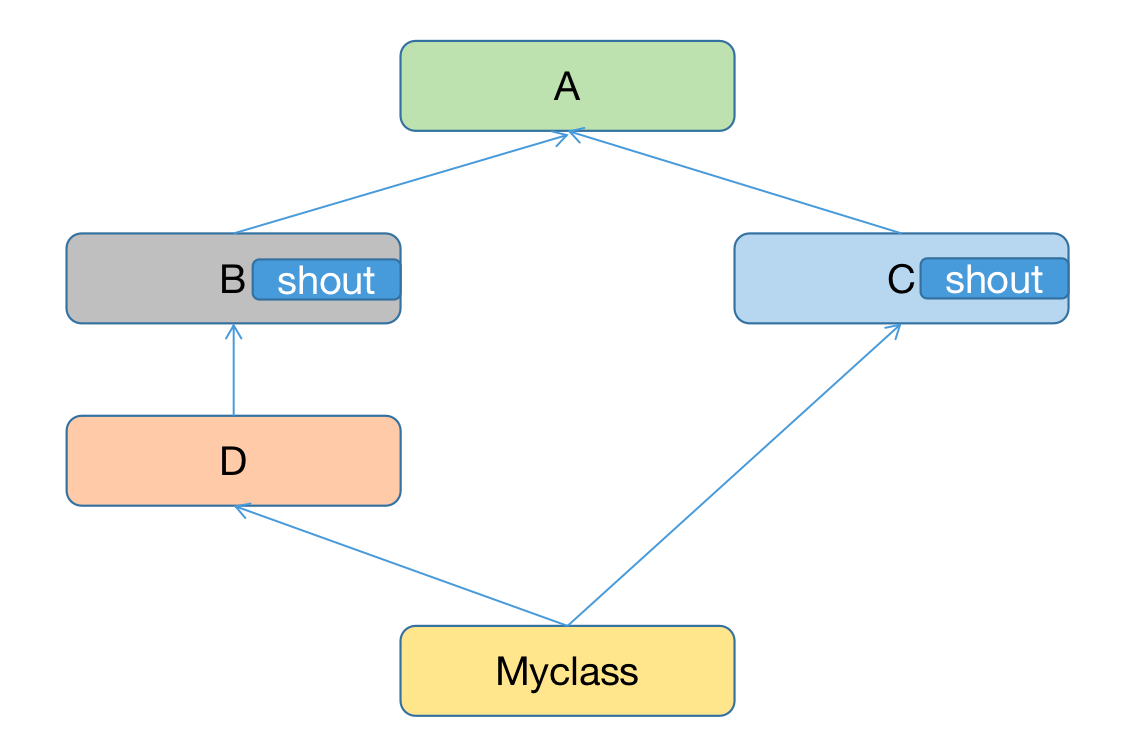
但是菱形结构,甚至更复杂的继承模型,就很可能出现,比如B实现了shout方法C也实现了shout方法,如果MyClass的实例想要调用父类的shout方法,那么到底是调用谁的呢,是B还是C,到底以谁为准,这就是二义性的问题,早起在Python2.x的时候继承的二义性其实是存在的,还有很多多继承带来的问题也都存在。
在Python3.x的版本下,就利用mro来解决了基类的搜索顺序,但是在不同的历史时期,诞生了三种搜索方法,但这三种搜索方法都是深度优先。

第一种,经典算法,基本上用不上了,这个是在2.2版本之前,按照上面的菱形继承,就是从左至右深度优先,所以这个算法得出的继承顺序就是,MyClass->D->B->A->C->A,如果按照这个经典算法的MRO的来找这个相同方法,我们能够很明确的知道,它是找到A的,很明显,不好,因此C明显离MyClass更近,而且这种情况可以看到A还有两次查找,所以这种算法存在很多问题。
第二种,新式类算法,它是经典算法的升级,如果出现重复的,那只将重复的保留最后一个,如果是这样的MyClass->D->B->A->C->A,A重复了,那么就会把前面的A删掉,保留最后一个,即MyClass->D->B->C->A,那上述重复的的问题就解决了,所以新式类的MRO就是这样的MyClass->D->B->A->C->A。
第三种,C3算法,当一个类被定义出来后,就会计算出一个MRO的一个列表,它就将这个类的方法解析顺序计算出来了,就是找类属性的顺序,Python3版本中唯一支持就是C3算法,即MyClass->D->B->C->A->Object,看似和第二种方法没区别,实际上区别特别大,因为第二种算法只是将重复的A删除了,仅做了这个一个修改,还有很多问题没解决,比如说二义性的问题也没有解决,C3算法很多问题都解决了,还解决了继承的单调性问题,尤其是遇到比菱形还复杂的继承关系模型,也是目前使用的算法,目前的MRO列表就是利用C3算法计算出来的,解决了方法的搜索顺序,如果存在的二义性问题,C3算法无法解决,就会,就会抛出异常。
多继承的缺陷
多继承引入了复杂性,往往这个复杂性如果控制不了,到后面就失控了,而且多继承带来了二义性,虽然允许多继承,但是多继承有的时候,是在执行的时候才会发现出现了问题,在团队协作开发的时候,如果引入多继承,那代码就很有可能出现不可控的情况,因为是多人协作开发,出现问题的几率极大,所以不管开发语言是否支持多继承,都应该避免使用多继承。
Mixin
Mixin是在Python的多继承中,一个非常有用的应用,这个应用就是利用多继承来实现的,这个多继承技术在现在很多语言都在使用的东西,Mixin这个用得非常广泛,Mixin英文的本意是“混进”,它是一种设计模式。

如果说我们要实现一个Document类,这个文档类主要的能力就是来记录一些内容,这个文档类,都有打印功能,不仅能存储数据还能将文档的类型打印输出的功能,而在这个文档类下面有Word类和PDF类,Word有Word的存储格式,PDF也有PDF的存储格式,但是他们存储的东西都是内容。
class Document(object):
def __init__(self,context):
self.context=context
def print(self):
print(self.context)
class Word(Document):pass
class Pdf(Document):pass
可以看到上述案例,Word和PDF的打印方法都一样,但是实际环境中Word有Word的打印方式,PDF有PDF的打印方式,这个时候,我们就需要按照如下的方式来实现。
class Document(object):
def __init__(self,context):
self.context=context
class Word(Document):
def print(self):
print(self.context,"in word")
class Pdf(Document):
def print(self):
print(self.context,"in pdf")
但是这样的话,父类的print方法丢了,当然,我们也可以在父类中加入print方法,然后由子类再去重新实现,达到覆盖的效果,父类做统一实现,叫做基本实现,如果觉得不好,子类就自己实现,所以就形成了如下的方式,这也是目前最常见的实现。
class Document(object):
def __init__(self,context):
self.context=context
def print(self):
print(self.context)
class Word(Document):
def print(self):
print(self.context,"in word")
class Pdf(Document):
def print(self):
print(self.context,"in pdf")
但是,还有一种实现方案,就是父类不实现,这种方式在其他语言中就限制非常多了,只不过在Python中无所谓,这种,我们提供了方法名,但是你想要调这个方法,是不可行的,这个方法就没实现,你调用,直接给你抛出异常。
父类只做方法的定义,就相当于只做了声明,当调用这个方法的时候,直接抛出异常,告诉调用者,父类没有实现,在Python当中,可能会看到有的类,在某些方法里面就直接了当地抛出NotImplementedError或者NotImplemented,这种类就是没有完全实现的一种类,这种类往往,不是为了让调用者去实例化的,它一般都是作为基类的,Python将这种方法称之为抽象方法。
class Document(object):
def __init__(self,context):
self.context=context
def print(self):
raise NotImplementedError("未实现异常")
class Word(Document):
def print(self):
print(self.context,"in word")
class Pdf(Document):
def print(self):
print(self.context,"in pdf")
抽象类方法
上述的抽象类方法的意思是,父类不实现,但是子类需要实现,在Python当中并不作强制要求,但是在其他语言当中,如果说子类继承了抽象基类,但并未实现基类的抽象方法,子类是无法实例化的,因为此子类还有未实现的方法,因为从父类继承的这个方法依然是抽象的,没有在子类中重新实现,Python没这种要求,抽象类,就是指的有抽象方法的类,抽象方法指的是未实现的方法。
所以正常的情况下,我们应该将父类的抽象方法,在子类中重新实现一遍,这样的设计,只是用来约束和规范所有子类的行为,写这个抽象方法是为了告诉使用者在子类中必须重新实现它,也就是说,对于继承这个基类的子类未来应该有的方法都约束死了,都写在基类,但是基类不实现,让继承者去实现,虽然在Python中很自由,可以不这样做,但是在其他语言中不做都不行,Python将这个思想保留了,至于做不做那就是使用者的事了。
现在又有一种情况,打印只是一种功能,一种能力,它不是所有Document的子子孙孙都需要的,Document只需要完成存储数据就行了,那么对于它未来的子类,谁需要谁自己实现print,有些方法不是所有子类都需要的,那么就形成了如下方式。
class Document(object):
def __init__(self,context):
self.context=context
# # 或者使用NotImplementedError
# def print(self):
# raise NotImplementedError("没有实现")
class Word(Document):
pass
class Pdf(Document):
def print(self):
print(self.context,"in pdf")
那么现在又有一种特殊场景,Word需要实现A、B、C三种功能,Pdf需要实现E、F、A三种功能,txt需要实现X、Y、B三种功能,在上面我们将print功能,认为是基类该有的东西,在这种复杂情况下,我们可以把他们分别拆解为功能模块的形式,然后再进行组合,其实这也就是补丁技术。
其实这也就是如何去装饰一个类的意思,将这个所谓的能力模块,单独抽出来,如果哪个需要,就给它注入进去,其实就是类似装饰器的功能,它的优点是简单,所以在他需要的时候,为它动态的去增加这种能力就行了。
class Document(object):
def __init__(self,context):
self.context=context
def printtab(cls):
cls.print=lambda cls:print(cls.context)
return cls
# 或者使用函数的方式
# def printtab(cls):
# def inner(self): # 这里直接写self,因为这个类会注入到类里面去
# print(self.context,"---- in inner")
# cls.print=inner
# return cls
@printtab # Word=printtab(Word)
class Word(Document):
pass
class Pdf(Document):·····
def print(self):
print(self.context,"in pdf")
w=Word("ce")
w.print()
上面是通过装饰器来实现,但是Word是别人写好的类,里面可能还有很多很多的属性方法,这样做是直接修改了人家的源程序,所以并不是特别的友好,违反了开闭原则,那么此时,我们如果只是想在它这个类里面临时增加一些属性,完全可以利用OCP多用继承少修改的原则,在Word类里面再继承一个子类出来,在子类上加装饰器更好,不需要的时候这个新定义的类就可以删除了。
class Document(object):
def __init__(self,context):
self.context=context
class Word(Document):
pass
class Pdf(Document):
def print(self):
print(self.context,"in pdf")
def printtab(cls):
cls.print=lambda cls:print(cls.context)
return cls
@printtab # 使用装饰器的方式给类注入特定的功能
class PrinttabWord(Word):pass
p=PrinttabWord("ce") # ce
p.print()
多继承实现方式
Mixin的本意就是混,缺什么补什么,可以看到上面的实现方式千奇百怪,那么利用面向对象的思想去解决,就是多继承,需要注意一点,在继承列表里面,父类的顺序,也就是mro的查找顺序。
class Document(object):
def __init__(self,context):
self.context=context
class Word(Document):
pass
# -------
class PrintableMixin: # 编写Mixin功能类
def printtab(self):
print(self.context)
class PrintableWord(PrintableMixin,Word):pass # 将Mixin类写到继承列表的最前面
pw=PrintableWord('ce')
pw.printtab() # ce
print(PrintableWord.mro()) # [<class '__main__.PrintableWord'>, <class '__main__.PrintableMixin'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
多继承(Mixin)的查找顺序
在多继承情况下,属性继承的顺序,就是在定义子类时,填写的顺序,可以使用mro()或者__mro__的方式来获取继承顺序,一旦找到就立即停止,不会继续往下查找,所以Mixin类一般都在继承列表的第一个位置。
装饰器的实现方式是修改了原有的代码结构,而Mixin(多继承)的方式只是在子类的继承链上多了一个继承父类而已。
多继承总结
Mixin其实就将其他类混进来,同时也将这个其他类的属性和方法,这样来看,Mixin和装饰器的效果一样,但是Mixin是类,是类就可以继承,那么根据面向对象的多用继承少修改的原则,在不修改当前类做修改的情况下,对原有类进行增强,只是在mro继承路线里面做了改变。
Mixin本质上就是多继承的实现,它体现的是一种组合的设计模式,却什么补什么,但是不是动态注入的,只是在继承路线上多了一个类,这个类拦截了其他所有的类,因为将Mixin类写在了前面,就拦截了其他父类的方法继承,就算别人有同名方法,根据多继承的属性查找顺序也不会用它。
在面向对象的设计中,一些复杂的类,往往需要很多的功能,而这些功能有来自不同的类提供,这就需要很多的类组合在一起,但是在Python中实际上是通过多继承实现的,但是这个多继承无非就是在同一个类的继承列表上多写了几个类罢了。
总结一句话,就是Mixin类里面只写缺失的功能函数,将缺失的功能组合到Mixin类里面,然后将Mixin类放在需要的类的继承列表的第一个位置即可。
查看属性
Python内置方法有很多,无论是初学者还是精通python的程序员都不可能全部记住所有方法,这时候dir()函数就非常有用了。使用dir()函数可以查看对像内所有的属性及方法,在Python中任何东西都是对像,一种数据类型、一个模块等,他们都有自己的属性和方法。
如果dir([object])的object参数,包含__dir__方法,那么将会直接调用该方法拿到结果,如果object中不包含__dir__方法,该方法将最大限度的收集属性信息。同时dir([object])对不同类型的object对象具有不同的行为,主要有以下几种。
模块:如果object是模块对象,返回的列表将包含模块的属性名和变量名;
类对象:如果object是类型或者类对象,那么返回的列表将包含类的属性名及它祖先类的属性名;
实例对象:如果object是实例对象,当这个实例有__dir__方法时,返回__dir__方法的返回值,如果没有__dir__方法时,则尽可能收集实例的属性名、类的属性和祖先类的属性名;
空:如果不给定object,如dir(),返回结果也尽不相同。
在模块中,如果使用dir不给定object时,返回模块的属性和变量名;
在函数中,如果使用dir不给定object时,返回当前函数内作用域的变量名;
在方法中,如果使用dir不给定object时,返回当前方法内作用域的变量名;