4、MongoDB分片集群
MongoDB分片
分片集群组件
分片集群架构
分片概念
Sharding Key(Config Server索引)
基于范围切片
基于列表分片(离散值)
基于哈希的分片
分片逻辑
切片键
集群环境
基于范围分片的集群部署
基于哈希的分片配置
分片集群的操作
分片集群组件
分片集群架构
分片概念
Sharding Key(Config Server索引)
基于范围切片
基于列表分片(离散值)
基于哈希的分片
分片逻辑
切片键
集群环境
基于范围分片的集群部署
基于哈希的分片配置
分片集群的操作
MongoDB分片
因为随着公司业务的发展,很可能数据集会变得越来越大,总有那么一个时刻会出现各种问题,比如由于数据集数据量太大,所以在但节点上的CPU扛不住了,所有数据的处理CPU都是满负荷工作,或者内存也扛不住了不够用,或者磁盘IO网络IO扛不住了,都是有可能性的,所以之所以要分片,就是因为我们的数据量太大了,导致单机上CPU或内存或IO或其他的任何方面出现瓶颈,导致我们不得不对出现在单机模式上的MongoDB进行扩展;
那么扩展无非就是向上或者向下扩展了,向上扩展无非就是增加更大的内存,更好的磁盘等,这不是一种比较好的解决方案,所以那就向外扩展,那就只能把数据集切成片,放在多个节点上来实现了,比如我们有个1TB的数据,数据量太大了,所以我们就只好,找几个Shard节点,把数据切割成多分,在每个节点上各放一部分数据,这个我们就叫做分片机制;
所以分片机制,是单个数据集的数据量过大时,或者面临其中任何一个瓶颈,比如在副本集复制场景中,主节点面临写压力时等等,向这种场景,我们都有可能不得不想办法将对单个数据集的操作,扩展为对多个数据集的操作,那这样一来我们的数据把它分片以后,我们查询数据是不是就有影响了,写入也一样会有影响,因此随着这种规模的增长,副本集就应付不了这种场景就不得不分片,但分片会带来很多额外的问题;
MySQL也是支持分片的,而MySQL的分片是需要借助于额外的技术来实现,常用技术有Gizzard、HiveDB、MySQL-Proxy+Hsacle、Hibernate Shard、Pyshards等,所以我们要想学习MySQL分片的话,那还不得不去熟悉一个分片框架的使用,了解业务模型,而后你才能实现数据分片;
而MongoDB的分片就很简单了,因为MongoDB原生支持sharding集群,而且自动实现分片;

分片集群组件
MongoDB自己内部的分片框架有三个组件,如上图,Router可以理解为是一个mongodb的代理,用户请求都到Router, 因此所有的用户查询都向Router发起,但Router自己是不会存储数据,也不会查询数据的,它只是将用户的请求给它路由到合适的分片上执行,比如我们要查询年龄大于30的,大于30的用户的这个数据有可能是Shard 1上存在一部分也有可能在Shard 2上存在一部分,因此我们的这个Router自己必须知道Shard 1上面有哪些,Shard 2上有哪些,所以各个Shard存放数据的元数据,都存储在Config Server里面放着;
所以这就和我们的分布式系统很接近,分布式系统有前端节点,有后端节点,前端节点自己持有元数据,不存储数据,而数据都存在后端节点里面,但是MongoDB不一样,MongoDB必须有三类节点,第一个节点是路由,它必须要实现路由,之所以是这样那是因为MongoDB的客户端无需联系后端Shard节点,客户端只只需要联系到我们的前端Router节点即可,所以Router节点既要接收用户请求解析路由请求,还有路由用户请求,并且还要把请求结果反馈回来,所以我们就可以认为Router是一个前端的代理,所以在MongoDB的分片架构中的角色有三个;
mongos:Router,它就是一个前端代理服务器;
Config Server:元数据服务器,用于存储集群的元数据的,事实上对MongoDB来讲元数据放的是对应Shard的索引,因为只有索引才能进行映射,这个索引明确知道这个索引对应的数据都放在了哪个节点上,所以元数据服务器其实是放的是collection上的索引,但此处我们将其称为元数据;
Shard:数据节点,也称为mongod节点,负责将用户请求的数据负责处理,并响应给客户端;
分片集群架构
通过上面的概念,衍生出来一个问题,如果整个分片集群中有某一个分片节点故障了,那整个分片集群是无法工作的,可能会有数据但是数据是不一致的,所以在Shard故障的时候我们还得有相应的解决办法,因此为了保证整个分配集群能够正常的工作,所以通过上图可以看出,每个Shard其实就是一个复制集,那很显然,每个Share至少得有三个节点,那当然,我们的Config Server也得有三个节点,因为如果Config Server挂了,那整个集群也就全挂了,因为Router就没法工作了;
那么我们的Config Server多节点的场景下,如何保证Config Server主节点挂了其他备用的Config Server能够接管其任务成为主节点呢,这需要借助于外部的工具来实现,比如zookeeper这样的工具来实现;
zookeeper是一个第三方的能实现选举机制并选取谁是最终主节点的这么一种机制,zookeeper通常用来分布式节点的协调,作为一个中心协调节点,并且zookeeper可以自行构建三个节点,自行组成高可用集群;
Router组件来讲,其实有一个就可以,因为它只是一个统一入口,即使挂了也不会影响我们的数据,但是Router一挂那么入口就挂了,所以为了项目的稳定,还需要将Router作为高可用,比如使用keepalived来构建高可用集群;
分片概念
Sharding的主要目的就是为了实现将数据进行分片,然后将这些分配分散到多个Shard上去的,将一个collection或者较大的数据集切割成片,就比如说将一个collection平均分成多个10M的片,每个节点上一份或者多份,因此为了能够保证整个Sharding集群当中的Shard副本尽可能的保证均衡(每个副本的大小相近),事实上这一个collection会切割成一个一个大小固定的块,它把这些快就开始逐个的分散到各个Shard节点上;
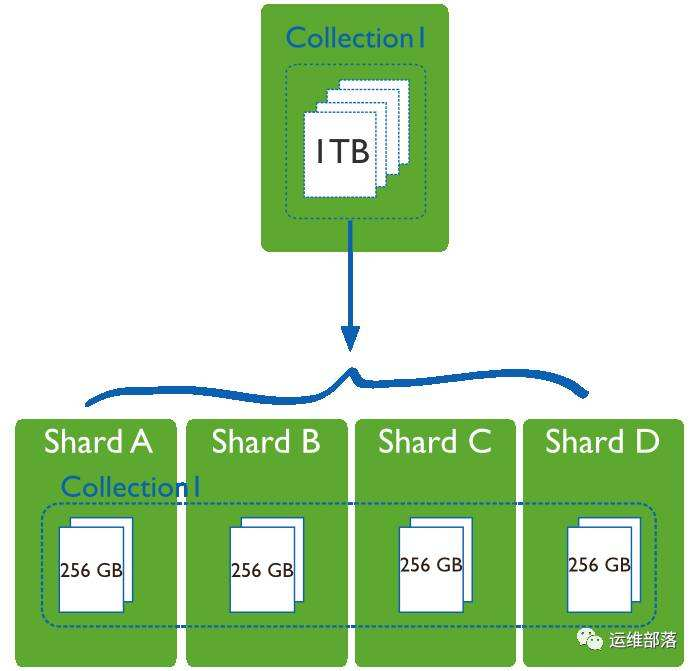
Sharding的主要目的就是为了将数据分散到多个shard上去的,这是Sharding的目的,将一个大的数据集(collection),切割成片,比如将一个1TB的collection切割成4个256G个片,比如一共四份,每个节点一份,可能运行一段时间之后,有可能Shard的分片就不均匀了,比如Shard A有3个分片,B有2个分片,C有1个分片,因为我们说过,我们的这个路由是根据Config Server进行路由的,而Config Server是根据你的索引的范围来实现的,比如0-20是在Shard A上,20-40是Shard B上...,所以就很可能出现有的Shard数据量过大,有的Shard数据量过小的问题;
所以Sharding集群就会采取数据均衡的策略,它会动态调整0-20、20-40的这个大小,动态调整之后比如ShardA是0-10,B是10-20,那么原有的0-20,20-40,那么也会进行调整,所以一次均衡就会带动全局的变动,所谓变动就是数据不断在的各个Shard挪来挪去,这就是MongoDB数据的均衡方式;
Sharding Key(Config Server索引)
Config Server上其实就是放的元数据,而元数据说白了就这个对应上图的Collection较大数据集的索引,那很显然,我们索引不能对一个数据集的所有字段做索引,我们构建索引时,也一般来讲只对其中的有限的一个或几个字段做索引,那么我们接下来真正做分片时,就是根据你的索引来分片,索引来判断,有几个Shard节点,而后索引会尝试着把索引节点中所指向的每一个数据开始做平均分割,平均完了以后,ShardA、B、D、D就各持有一份数据;
索引有类型的概念,而不同的类型的分法是不一样的,比如B Tree索引,对于B Tree索引其实就是一个排序索引,具有顺序的排序索引,所以既然是一个排序索引,那么它就是一个连续的范围的数据,所以我们在索引类型上基于索引本身做Sharding分片时,它的分片机制有如下几种;
基于范围切片
这个范围切片需要你用的索引一定支持顺序排序的索引,也就意味着他们是B Tree索引,那么这种索引我们通常就称之为Range索引,但是有些取值可能是一些离散的,比如说,我们是一个电商站点,我们将全国注册的用户按照省份存放,以省份来进行Range切片,那是不公平的,因为有可能省份人很多,有的可能人很少,这样划分是不均衡的,所以像这种参加中,我们同常不使用这种连续范围进行切割的,而是通过离散取值的方式进行切割;
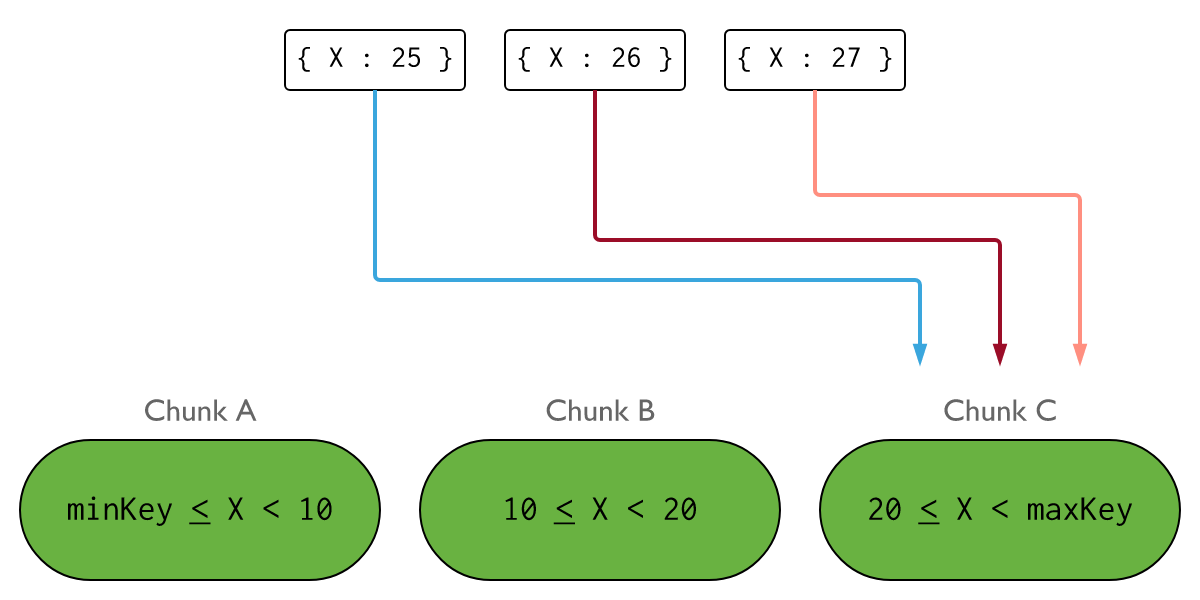
基于列表分片(离散值)
假如我们认为东三省的人比较少一点,那我们就将东三省放在一个分片上,而北京一个直辖市就和东三省的人口差不多,那就把北京放在一个分片上,它是指明哪个范围的几个组合在一块的这种方式叫做基于离散值的分片;
基于哈希的分片
基于哈希的分片,它就不是根据范围来分片了,没有根据原有取值顺序的方式,放在多个不同的shard上来实现存放的,基于哈希值的分片,比如说我们一共有四个分配,我们的取值范围按照年龄为例,我们不想按照年龄大小来存放了,假如我们有四个shard,我们可以除以4取模,取余的结果放在第一个分片上,为1的放在第二个分片上,以此类推,按照键对所有的分片取模之后,分散存放;
比如对于一个电商产品,新上的商品,一般它的ID数都比较大,因为每个商品应该都有一个id号,并且新上的商品一般访问量比较大,如果按照范围分片的话, 结果就是对这个访问量比较大的这个商品的访问全在这个分片上,热区集中了,包括你的数据卷插入和访问都集中了,所以在此处,分片的意义就不是那么明显了,我们分片的主要目的还是为了去分散写操作的,当然也会分散读操作,为了避免写热区,此时的哈希分片的方式就比较有用了,把id号做hash计算,然后根据节点取模,将数据落在分片上,这就有效的把热点数据给分散出去了;
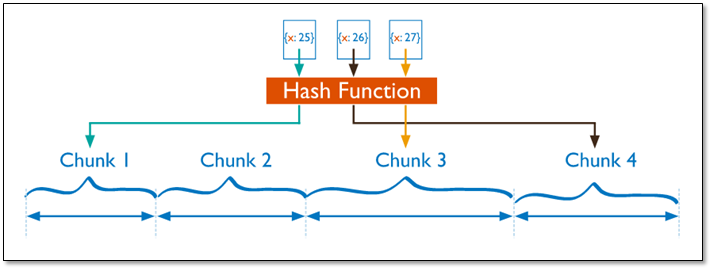
分片逻辑
那么到底基于哪种模型切片,还是要根据业务模型来判定的,但大体上有个指导方针,就是分完片以后,写要离散,把写操作分到越来越多的Shard上去越好,而读要集中,写离散读集中,也就意味着在做读操作的时候,涉及到的读节点越少越好,因为读的时候如果节点很多的话,尤其是需要排序,比如我们需要找一找年龄30以上的所有用户,最后排个序,如果从两个Shard上查,那么假设我们使用的是hash切片的,那么结果就是第一个Shard上, 年龄从0-100的所有用户都有,第二个Shard上也是年龄从0-100的所有用户都有,第一个节点上排好序了,第二个节点也排好序了,但是整体结果来看还得重新排序;
所以我们某一次查询,而且需要进行排序的时候,如果是只在一个Shard上查询,那么这一个Shard上的结果就能直接作为最终结果使用了,所以做分片,写离散,读集中是比较好;
切片键
但是好在我们写的时候可能一次会批量插入很多数据,你如果插入一个数据那就只能写在一个Shard上,这是毋庸置疑的,但是如果一批插入很多数据,比如说我们最近搞活动了,有一大堆的新商品上线,这些新商品通过hash计算被分散到了很多节点上去,那写一离散,那很显然,对于我们的写IO就有效的降低了,那将来的读的时候呢,因为我们的用户浏览商品,一次只会浏览一个,所以对于读来讲,它涉及的数据集很小,除非有这种效果,要做数据分析了,我们需要查询一下过去一段时间内,我们的哪个商品卖的销量是最好的,那这就麻烦了,所以这要从Shard上去查的话,那这事就麻烦大了去了,因为我们需要从各个Shard上查出来,然后再各个Shard上排好序,然后将所有排序的结果拿出来还需要进行一次排序才能拿到最终的结果,所以一般而言不会在数据库本身上做这种大规模的数据分析的,一般都是通过搜索引擎来做的,我们通过搜索引擎把MongoDB的所有数据读出来,放到搜索引擎中去,再在搜索引擎中去做数据分析,由搜索引擎来完成操作,所以大批量的排序等操作,通常不在数据库层面进行,所以读本身就有了集中的态势,而写是离散的;
就像微博一样,微博其实就有一个很大的问题,根据用户切有问题,因为每个用户都有可能像别人发评论的,同样如果一个用户要想查看自己的所有微博,那它要向所有Shard上发起查询请求,可能它发的所有微博在Shard A、B、C、D上都有,那这个时候用户要显示自己的所有微博,就涉及到了每个Shard操作,因此我们的切片有时候可能需要组合索引来做,就是这么一个道理,先根据年龄基于范围切片,再根据用户名做列表切片,这样才能保证一个用户的所有内容都在一个节点上,因为它调度时考虑的因素不止一个,不光是年龄的本身也包括用户名,所以我们将来真正切片时,为了能够应付更多的查询场景有可能用的是组合索引,根据哪个索引做切片,那么这个索引就叫做切片键;
集群环境
由于机器不足,现使用4台机器来构建出一套分片集群,版本采用v4.2.6,集群Router我们暂时使用一台,这是我们的分片总入口,它是无状态的一个服务,我们也可以对其进行动态扩展 ,这个看业务而定,ConfigServer我们的配置服务,做成副本集的方式,这个貌似也是mongodb新版本的要求,必须是一个副本集,然后我们的Shard节点采用replset副本集的方式来构建,每一个Shard都是一个独立的副本集,再次我们创建两个Shard,具体架构、分布信息如下;
| 服务名 | 端口 | 主机名 | 网络地址 |
| mongos | 27017 | node01.cce.com | 172.16.1.1 |
| ConfigServer1 | 27027 | node02.cce.com | 172.16.1.2 |
| ConfigServer2 | 27028 | node02.cce.com | 172.16.1.2 |
| ConfigServer3 | 27029 | node03.cce.com | 172.16.1.2 |
| mongod_1_1 | 27017 | node03.cce.com | 172.16.1.3 |
| mongod_1_2 | 27018 | node03.cce.com | 172.16.1.3 |
| mongod_1_3 | 27019 | node03.cce.com | 172.16.1.3 |
| mongod_2_1 | 27017 | node04.cce.com | 172.16.1.4 |
| mongod_2_2 | 27018 | node04.cce.com | 172.16.1.4 |
| mongod_2_3 | 27019 | node04.cce.com | 172.16.1.4 |
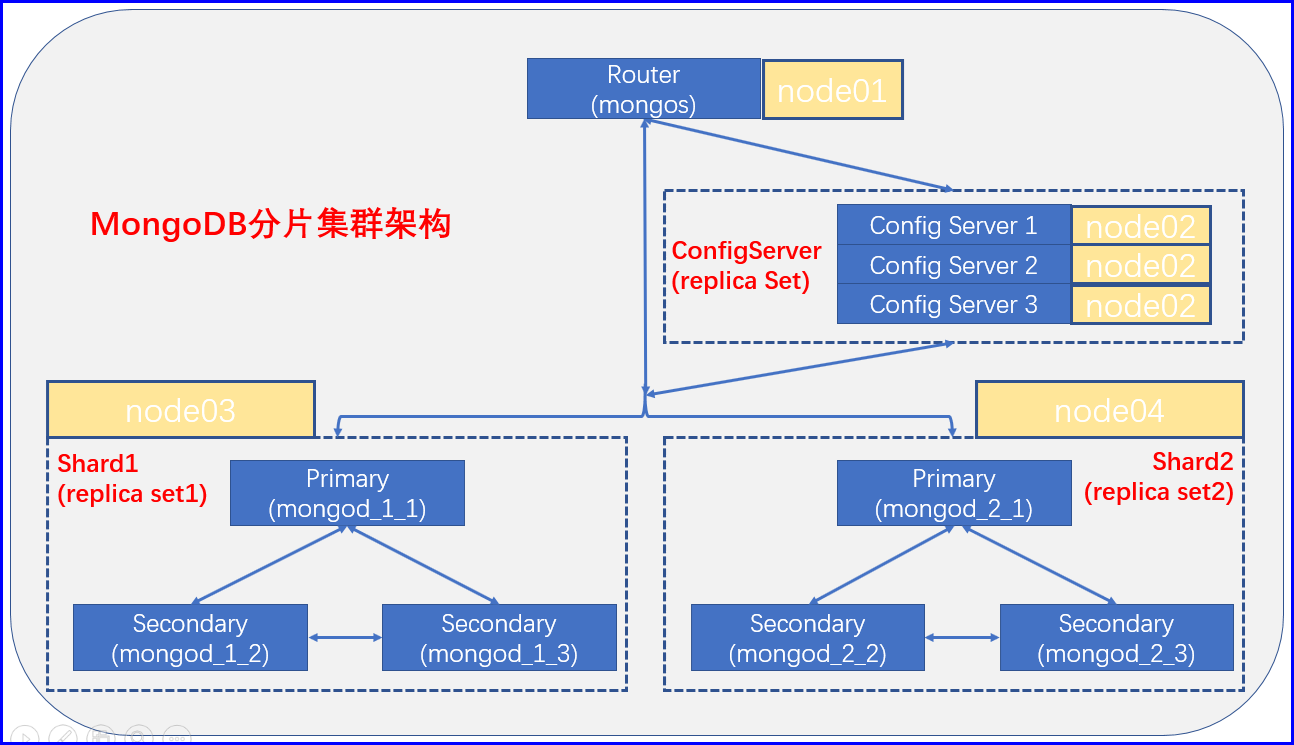
基于范围分片的集群部署
在配置MongoDB副本集的时候,我们需要先去配置Config Server节点,而后再是Mongos节点,而最终才是Shard节点;
# 分别在四台节点配置YUM源并创建数据目录
[root@node01 ~]# cat > /etc/yum.repos.d/mongodb.repo << EOF
[mongodb]
name=MongoDB Repository
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mongodb/yum/el7/
gpgcheck=0
enabled=1
EOF
[root@node01 ~]# yum clean all
[root@node01 ~]# yum makecache
---
# 在node2节点的Config Server
[root@node02 ~]# yum install -y mongodb-org
# 为三台ConfigServer提供配置
[root@node02 ~]# cp /etc/mongod.conf /etc/mongod1.conf
[root@node02 ~]# cp /etc/mongod.conf /etc/mongod2.conf
[root@node02 ~]# cp /etc/mongod.conf /etc/mongod3.conf
# 为三台ConfigServer配置数据目录
[root@node02 ~]# mkdir -p /data/mongodb/configsvr{1..3}/{data,logs,run}
[root@node02 ~]# tree /data/
/data/
└── mongodb
├── configsvr1
│ ├── data
│ ├── logs
│ └── run
├── configsvr2
│ ├── data
│ ├── logs
│ └── run
└── configsvr3
├── data
├── logs
└── run
# 配置第一台ConfigServer
[root@node02 ~]# grep '^[^#]' /etc/mongod1.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb/configsvr1/logs/mongod.log
storage:
dbPath: /data/mongodb/configsvr1/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongodb/configsvr1/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27027
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: csvr
sharding:
clusterRole: configsvr
# 配置第二台ConfigServer提供配置数据目录
[root@node02 ~]# grep '^[^#]' /etc/mongod2.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb/configsvr2/logs/mongod.log
storage:
dbPath: /data/mongodb/configsvr2/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongodb/configsvr2/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27028
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: csvr
sharding:
clusterRole: configsvr
# 配置第三台ConfigServer提供配置数据目录
[root@node02 ~]# grep '^[^#]' /etc/mongod3.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb/configsvr3/logs/mongod.log
storage:
dbPath: /data/mongodb/configsvr3/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongodb/configsvr3/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27029
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: csvr
sharding:
clusterRole: configsvr
# 启动三台ConfigServer
[root@node02 ~]# mongod -f /etc/mongod1.conf
[root@node02 ~]# mongod -f /etc/mongod2.conf
[root@node02 ~]# mongod -f /etc/mongod3.conf
[root@node02 ~]# netstat -ntlp|grep '2702'
tcp 0 0 0.0.0.0:27027 0.0.0.0:* LISTEN 7046/mongod
tcp 0 0 0.0.0.0:27028 0.0.0.0:* LISTEN 7151/mongod
tcp 0 0 0.0.0.0:27029 0.0.0.0:* LISTEN 7231/mongod
# 初始化ConfigServer副本集
[root@node02 ~]# mongo --port 27027
> rs.initiate()
csvr:PRIMARY> rs.add('node02.cce.com:27028')
csvr:PRIMARY> rs.add('node02.cce.com:27029')
# 查看ConfigServer副本集
---
# 在node01上安装mongos
[root@node01 ~]# yum install -y mongodb-org-mongos mongodb-org-shell
# 创建mongos的日志目录
[root@node01 ~]# mkdir /data/mongodb/logs
[root@node01 ~]# tree /data/
/data/
└── mongodb
└── logs
# 以命令行的方式启动mongos,启动mongos只需要指定config server所在地址即可,可以是逗号隔开的三个或者一个
# [root@node01 ~]# mongos --configdb csvr/172.16.1.2:27027,172.16.1.2:27028,172.16.1.2:27029 --fork
# 提供mongos的配置文件
[root@node01 ~]# cat > /etc/mongos.conf << EOF
systemLog:
destination: file
path: /data/mongodb/logs/mongos.log
logAppend: true
net:
bindIp: 0.0.0.0
port: 27017
sharding:
configDB: csvr/172.16.1.2:27027,172.16.1.2:27028,172.16.1.2:27029
processManagement:
fork: true
EOF
# 启动mongos
[root@node01 ~]# mongos -f /etc/mongos.conf
[root@node01 ~]# netstat -ntlp|grep '270'
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN 25803/mongos
---
# 在node03上创建一个shard副本集,首先创建数据目录
[root@node03 ~]# mkdir -pv /data/mongod{1..3}/{data,logs,run}
[root@node03 ~]# tree /data/
/data/
├── mongod1
│ ├── data
│ ├── logs
│ └── run
├── mongod2
│ ├── data
│ ├── logs
│ └── run
└── mongod3
├── data
├── logs
└── run
# 安装mongodb
[root@node03 ~]# yum install -y mongodb-org
# 提供三台mongod的配置文件
[root@node03 ~]# cp /etc/mongod.conf /etc/mongod1.conf
[root@node03 ~]# cp /etc/mongod.conf /etc/mongod2.conf
[root@node03 ~]# cp /etc/mongod.conf /etc/mongod3.conf
# 配置第一台副本集节点的mongod
[root@node03 ~]# grep '^[^#]' /etc/mongod1.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod1/logs/mongod.log
storage:
dbPath: /data/mongod1/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod1/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27017
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
# 配置第二台副本集节点的mongod
[root@node03 ~]# grep '^[^#]' /etc/mongod2.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod2/logs/mongod.log
storage:
dbPath: /data/mongod2/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod2/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27018
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
# 配置第三台副本集节点的mongod
[root@node03 ~]# grep '^[^#]' /etc/mongod3.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod3/logs/mongod.log
storage:
dbPath: /data/mongod3/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod3/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27019
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard1
sharding:
clusterRole: shardsvr
# 启动三台mongod
[root@node03 ~]# mongod -f /etc/mongod1.conf
[root@node03 ~]# mongod -f /etc/mongod2.conf
[root@node03 ~]# mongod -f /etc/mongod3.conf
# 初始化副本集
[root@node03 ~]# mongo
> rs.initiate()
shard1:PRIMARY> rs.add('node03.cce.com:27018')
shard1:PRIMARY> rs.add('node03.cce.com:27019')
---
# 在node04上创建一个shard副本集,首先创建数据目录
[root@node04 ~]# mkdir -pv /data/mongod{1..3}/{data,logs,run}
[root@node04 ~]# tree /data/
/data/
├── mongod1
│ ├── data
│ ├── logs
│ └── run
├── mongod2
│ ├── data
│ ├── logs
│ └── run
└── mongod3
├── data
├── logs
└── run
# 安装mongodb
[root@node04 ~]# yum install -y mongodb-org
# 提供三台mongod的配置文件
[root@node04 ~]# cp /etc/mongod.conf /etc/mongod1.conf
[root@node04 ~]# cp /etc/mongod.conf /etc/mongod2.conf
[root@node04 ~]# cp /etc/mongod.conf /etc/mongod3.conf
# 配置第一台副本集节点的mongod
[root@node04 ~]# grep '^[^#]' /etc/mongod1.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod1/logs/mongod.log
storage:
dbPath: /data/mongod1/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod1/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27017
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
# 配置第二台副本集节点的mongod
[root@node04 ~]# grep '^[^#]' /etc/mongod2.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod2/logs/mongod.log
storage:
dbPath: /data/mongod2/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod2/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27018
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
# 配置第三台副本集节点的mongod
[root@node04 ~]# grep '^[^#]' /etc/mongod3.conf
systemLog:
destination: file
logAppend: true
path: /data/mongod3/logs/mongod.log
storage:
dbPath: /data/mongod3/data
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongod3/run/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
net:
port: 27019
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
replication:
replSetName: shard2
sharding:
clusterRole: shardsvr
# 启动三台mongod
[root@node04 ~]# mongod -f /etc/mongod1.conf
[root@node04 ~]# mongod -f /etc/mongod2.conf
[root@node04 ~]# mongod -f /etc/mongod3.conf
# 初始化副本集
[root@node04 ~]# mongo
> rs.initiate()
shard2:PRIMARY> rs.add("node04.cce.com:27018")
shard2:PRIMARY> rs.add("node04.cce.com:27019")
---# 进入mongos将node03和node04的副本集作为分片节点加入分片集群
[root@node01 ~]# mongo
mongos> sh.addShard("shard1/node03.cce.com:27017,node03.cce.com:27018,node03.cce.com:27019")
mongos> sh.addShard("shard2/node04.cce.com:27017,node04.cce.com:27018,node04.cce.com:27019")
# 列出我们有多少个shards
mongos> db.runCommand('listShards')
{
"shards" : [
{
"_id" : "shard1",
"host" : "shard1/node03.cce.com:27017,node03.cce.com:27018,node03.cce.com:27019",
"state" : 1
},
{
"_id" : "shard2",
"host" : "shard2/node04.cce.com:27017,node04.cce.com:27018,node04.cce.com:27019",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1590473411, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1590473411, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5ecc799016a6e3f07938468d")
}
shards: # Shard分片节点
{ "_id" : "shard1", "host" : "shard1/node03.cce.com:27017,node03.cce.com:27018,node03.cce.com:27019", "state" : 1 }
{ "_id" : "shard2", "host" : "shard2/node04.cce.com:27017,node04.cce.com:27018,node04.cce.com:27019", "state" : 1 }
...
databases: # 支持分片的数据库,primary表示主shard,一个库内并非所有的collection都需要分片的,那对于那些不分片的就放在了主shard上,而那些分片可能在各shard上都有数据,partitioned表示是否支撑shard
{ "_id" : "config", "primary" : "config", "partitioned" : true }
# 接下来就开始指定数据库分片了,首先创建一个database和数据库和collection
mongos> use cce;
mongos> sh.enableSharding('cce') # 启用cce库分片功能,让cce库支持分片
mongos> sh.shardCollection('cce.user',{age: 1}) # 指定在cce库的user collection上面创建索引,并且以age为索引的键,这样我们的cce.user就支持分片了
mongos> sh.status()
...
主shard 是否支持分片
{ "_id" : "cce", "primary" : "shard1", "partitioned" : true, "version" : { "uuid" : UUID("66464020-cc8f-464b-9483-112a4343fd7a"), "lastMod" : 1 } }
cce.user
shard key: { "age" : 1 } # 分片索引键,升序索引
unique: false # 是否唯一,那就表示一个年龄只有一个人
balancing: true
chunks: # 第一个分片放到哪里了,下面表示第一个分片放在了shard1
shard1 1
{ "age" : { "$minKey" : 1 } } -->> { "age" : { "$maxKey" : 1 } } on : shard1 Timestamp(1, 0)
...
# 为了模拟测试,设置chunk大小,默认单个chunk为64M,如果达不到不会进去分片,此处设置成1M
mongos> use config;
mongos> db.settings.insert({"_id":"chunksize","value":1});
# 创建十万条测试数据
mongos> for (i=1;i<=100000;i++) db.user.insert({name: 'cce'+i,age: (i%120),email: ('mail'+i)+'@163.com',address: 'https://blog.doorta.com'})
# 在replSet1上查看一共有多少条数据
[root@node03 ~]# mongo
shard1:PRIMARY> use cce
shard1:PRIMARY> db.user.count()
55818
# 在replSet2上查看一共有多少条数据
[root@node04 ~]# mongo
shard2:PRIMARY> use cce
shard2:PRIMARY> db.user.count()
44182
# 查看分片规则
mongos> sh.status()
databases:
{ "_id" : "cce", "primary" : "shard1", "partitioned" : true, "version" : { "uuid" : UUID("66464020-cc8f-464b-9483-112a4343fd7a"), "lastMod" : 1 } }
cce.user
shard key: { "age" : 1 }
unique: false
balancing: true
chunks: # 当分片差距太大的时候,会自动均衡
shard1 9
shard2 10
{ "age" : { "$minKey" : 1 } } -->> { "age" : 0 } on : shard1 Timestamp(10, 0)
{ "age" : 0 } -->> { "age" : 8 } on : shard1 Timestamp(11, 0)
{ "age" : 8 } -->> { "age" : 16 } on : shard2 Timestamp(9, 2)
{ "age" : 16 } -->> { "age" : 18 } on : shard2 Timestamp(9, 3)
{ "age" : 18 } -->> { "age" : 26 } on : shard2 Timestamp(8, 2)
{ "age" : 26 } -->> { "age" : 34 } on : shard2 Timestamp(8, 3)
{ "age" : 34 } -->> { "age" : 36 } on : shard2 Timestamp(8, 4)
{ "age" : 36 } -->> { "age" : 41 } on : shard2 Timestamp(10, 1)
{ "age" : 41 } -->> { "age" : 49 } on : shard2 Timestamp(11, 1)
{ "age" : 49 } -->> { "age" : 58 } on : shard2 Timestamp(7, 9)
{ "age" : 58 } -->> { "age" : 60 } on : shard2 Timestamp(7, 10)
{ "age" : 60 } -->> { "age" : 68 } on : shard1 Timestamp(7, 5)
{ "age" : 68 } -->> { "age" : 77 } on : shard1 Timestamp(7, 6)
{ "age" : 77 } -->> { "age" : 79 } on : shard1 Timestamp(7, 7)
{ "age" : 79 } -->> { "age" : 83 } on : shard1 Timestamp(8, 1)
{ "age" : 83 } -->> { "age" : 100 } on : shard1 Timestamp(7, 1)
{ "age" : 100 } -->> { "age" : 108 } on : shard1 Timestamp(7, 11)
{ "age" : 108 } -->> { "age" : 119 } on : shard1 Timestamp(7, 12)
{ "age" : 119 } -->> { "age" : { "$maxKey" : 1 } } on : shard2 Timestamp(8, 0)
# 查看均衡器是否正在运行,如果此时没有出现chunk不均衡的情况,那么你会看到均衡器是没有启动的,如果出现了不均衡,它默认会自动启用的;
mongos> sh.isBalancerRunning()基于哈希的分片配置
admin > sh.shardCollection( "数据库名.集合名", { 片键: "hashed" } )
admin> db.user.ensureIndex( { age: "hashed" } )
admin > sh.shardCollection( "cce.user", {age: "hashed" } )分片集群的操作
# 判断是否Shard集群
admin> db.runCommand({ isdbgrid : 1})
# 列出所有分片信息
admin> db.runCommand({ listshards : 1})
# 列出开启分片的数据库
admin> use config
config> db.databases.find( { "partitioned": true } )
config> db.databases.find() //列出所有数据库分片情况
# 查看分片的片键
config> db.collections.find()
# 查看分片的详细信息
admin> db.printShardingStatus()
# 或
admin> sh.status()
# 删除分片节点
> sh.getBalancerState()
mongos> db.runCommand( { removeShard: "shard2" } )
# 查看mongo集群是否开启了 balance 状态
mongos> sh.getBalancerState()
# mongodb在做自动分片平衡的时候,或引起数据库响应的缓慢,可以通过禁用自动平衡以及设置自动平衡进行的时间来解决这一问题。
> use config
> db.settings.update( { _id: "balancer" }, { $set : { stopped: true } } , true );
# 自定义自动平衡进行的时间段
> use config
> db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "21:00", stop : "9:00" } } }, true )