9、Service资源管理
Service资源
Endpoint
Service底层实现
Service及Proxy Mode
iptables
ipvs
Service类型
ClusterIP
NodePort
LoadBalancer
ExternalName
Service代理
手动修改代理方式为ipvs
示例一
Endpoint与Service结合
内部端点集合
外部端点集合
Endpoint
Service底层实现
Service及Proxy Mode
iptables
ipvs
Service类型
ClusterIP
NodePort
LoadBalancer
ExternalName
Service代理
手动修改代理方式为ipvs
示例一
Endpoint与Service结合
内部端点集合
外部端点集合
Service资源
Pod资源在Pod控制器的控制下,可能随时会重启或重构,其实严格意义上来讲Pod是不能被重建的,所谓的重建就是指在原来的基础之上建立一个,但Pod不是这样的,因为在Pod控制器下,一旦这个Pod终止了,我们会发现它和原来的Pod是没有关系的,所以从某种意义上来讲,这是不叫重建的,所以Pod资源存在生命周期,且不可重建,必要时,我们仅能够创建一个替代者,而不是在原来的基础上重构出来的,从某种意义上来讲这叫新建和替代的关系,所以严格意义上来说不是重建,只是一个替代者而已;
Pod控制器是可以实现规模伸缩的,此前使用的scale命令或者直接去修改deployment控制器的副本数量,就能够调整Pod副本数量的,一旦Pod数量增加或减少了,也会导致Pod在访问时的可用及不可用状态的变动,因此Pod相对于这种动态性在很大程度上会给客户端去访问Pod带来困扰,如果使用Pod的IP直接访问Pod,就可能会出现一会儿有,一会儿没有,所以在必要时我们需要增加一个中间层,这个中间层是固定的,只要你不删除和人为修改,这个中间层我们就称为Service,Service本身通过标签选择器,关联拥有相匹配的Pod对象,Service其实也不是直接关联Pod的,甚至说Service压根就不是关联Pod的,而是关联到端点Endpoint;
Endpoint
Endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址,一个Service由一组backend Pod组成。这些Pod通过endpoints暴露出来,结果被POST到一个名称为Service-hello的Endpoint 对象上。 当Pod终止后,它会自动从Endpoint中移除,新的能够匹配上Service Selector的Pod将自动地被添加到Endpoint中。检查该Endpoint,注意到IP地址与创建的Pod是相同的。现在能够从集群中任意节点上使用curl命令请求hello Service<CLUSTER-IP>:<PORT> 。 注意 Service IP 完全是虚拟的,它从来没有走过网络;
Kubernetes在创建Service时,根据Service的标签选择器(Label Selector)来查找Pod,据此创建与Service同名的EndPoints对象。当Pod的地址发生变化时,EndPoints也随之变化。Service接收到请求时,就能通过EndPoints找到请求转发的目标地址;
Service不仅可以代理Pod,还可以代理任意其他后端,比如运行在Kubernetes外部Mysql、Oracle等。这是通过定义两个同名的service和endPoints来实现的;
在实际的生产环境使用中,通过分布式存储来实现的磁盘在mysql这种IO密集性应用中,性能问题会显得非常突出。所以在实际应用中,一般不会把mysql这种应用直接放入kubernetes中管理,而是使用专用的服务器来独立部署。而像web这种无状态应用依然会运行在kubernetes当中,这个时候web服务器要连接kubernetes管理之外的数据库,有两种方式,第一是直接连接数据库所在物理服务器IP,另一种方式就是借助kubernetes的Endpoints直接将外部服务器映射为kubernetes内部的一个服务;
Endpoint引用了Pod,Endpoint就是IP+端口,是实现实际服务的端点集合,比如指定了一个某一个Pod的IP+端口,这就是一个Pod的Endpoint,因此Service引用的Endpoint,而Endpoint引用了Pod,因此这个时候客户端向Service请求时,Service能够将其代理并调度至后端不同的Endpoint从而把流量转发给这个Endpoint后端引用的IP地址和端口;
Endpoint后端也不一定是Pod,有的时候,我们的MySQL数据库服务器可能并没有运行在Pod中,而是直接运行在我们的Kubernetes集群之外的主机中,那么这个时候,我们也可以对于这个MySQL做一个端点,让Pod里面服务能直接通过Endpoint访问集群外部的MySQL服务器,这就是为什么集群中加一个中间层的原因,因为被引用的不一定是Pod,也有可能是集群之外其他地方的服务,这就是为什么Service后端是Endpoint的这个中间层,而不是直接的Pod的原因;
Service底层实现
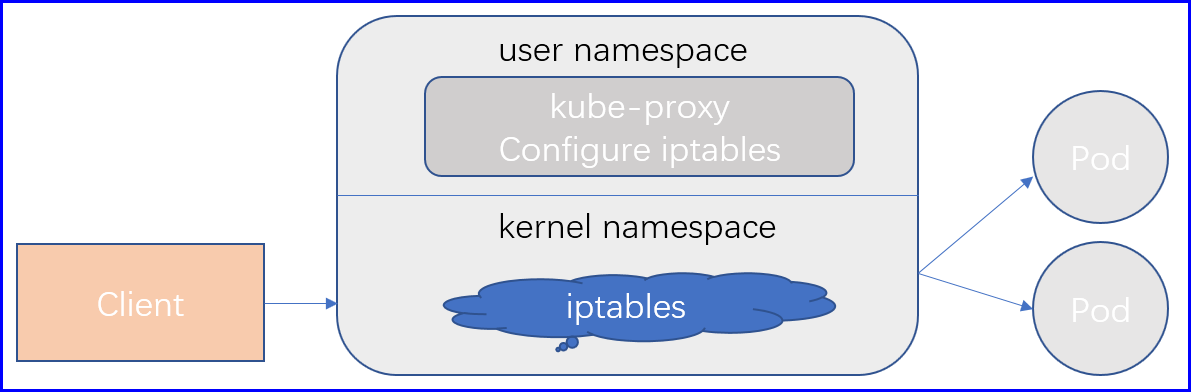
Service也是一个标准的kubernetes资源,对它的增删改查的管理操作,依然需要借助于ApiServer进行,但是其实每一个Service,对一个kubernetes实际上来讲,它应该是被转换为每一个节点上的Iptables或ipvs规则,每一个节点都有,因此,以某一个节点为例,这个节点上的Pod它是一个Client客户端,它试图访问某一个Service时,这个Service的IP地址一定在存在于这个Client节点所在的内核的netfilter框架的iptables或者ipvs规则上的,所以一旦这个Pod中的进程,对外发出的网络请求,如果目标的某一个Service,那这个目标地址一定会被当前节点上的iptables或者ipvs匹配到,而这个规则,可能是一个DNAT规则,也可能是一个简单的转发,或者代理规则,它未必是一个DNAT,一般而言不会使用DNAT逻辑,因为Pod到Pod是直接可达的,只有必要的时候才会给它做DNAT;
所以这个时候,我们的内核中的规则,会根据规则中的逻辑,假如它访问的服务的后端有多个Pod,那么这个时候,我们的Service会基于挑选算法或叫调度算法,从这个众多被访问的服务端Pod中挑选出一个Pod出来,并把挑选出来的Endpoint对应的地址,返回给客户端,或者说把流量直接转过去,因此就能使得Client与目标后端Pod直接进行通信了,Service后端有可能是当前集群中的一个Pod,也可能是当前集群之外的具体的服务器提供的服务,不管怎么样,Service会把流量代理带指定的节点上去的,如果就是当前节点上的其他Pod,只不过Service做的仅仅是一个转发而已,如果后端有多个Pod,DNAT虽然有调度功能,但是DNAT支持的调度算法是有限的,我们想实现更强大调度算法应该使用ipvs,因此这儿的规则也可以不是iptables规则,也可以是ipvs规则。
我们的Service随时有可能会被创建、修改、删除,那也就意味着我们每一个节点上的iptables或ipvs规则随时有可能会发生变化,那这个变动如何及时的反映到谋个节点上呢,那么整个集群中的每一个节点上都会运行一个守护进程,如果使用kubeadm去部署,它就是运行为一个Pod,就是我们的kube-proxy,它会在每一个节点上运行为一个Pod,它是一个DaemonSet控制器所控制的Pod,因此每个节点只能有一个,在kubernetes上如果是使用kubeadm部署集群的话,它甚至于会容忍主节点的污点,所以会在主节点上也运行一个;
kube-proxy其实就是ApiServer的客户端,运行在每一个节点上的一个守护进程,并告诉ApiServer监听所有Service资源的变动,一旦ApiServer上某一个Service资源发生变动,ApiServer会立即通知到每一个监视到这个Service的所有kube-proxy,而后kube-proxy转换为iptables或ipvs规则,所以支持Service实现的重要组件就是每一个节点上的kube-proxy进程,这个进程监听所有Service资源的变动,实时将其变动转换为节点上的规则;
Service及Proxy Mode
简单来讲,一个Service对象就是工作节点上的iptables或ipvs规则,用户将到底Service对象IP地址的流量转发至想用的Endpoint对象指向的IP地址和端口之上;
工作于每个工作节点的kube-proxy组件,通过API Server持续监控着各Service及其关联的Pod对象,并将其创建或变动实时反映至当前工作节点上的响应的iptables或ipvs规则,kube-proxy把请求代理至少相应端点的方式有三种:userspace(用户空间)、iptables、ipvs
iptables
对于每个Service对象,kube-proxy会创建iptables规则直接捕获到达ClusterIP和Port的流量,并将其重定向至当前的Service对象的后端Pod资源,对于每一个Endpoint对象,Service资源会为其创建iptables规则并关联至挑选的后端Pod资源对象,相对于用户控件模型来说,iptables无需讲流量在用户控件和内核空间来回切换,因此也就更为高效,kube-proxy只负责维护iptables规则链,当客户端访问到我们的Service的时候,当请求报文到达内核的iptables规则链上,一经匹配,立马转发给后端的Pod;
ipvs
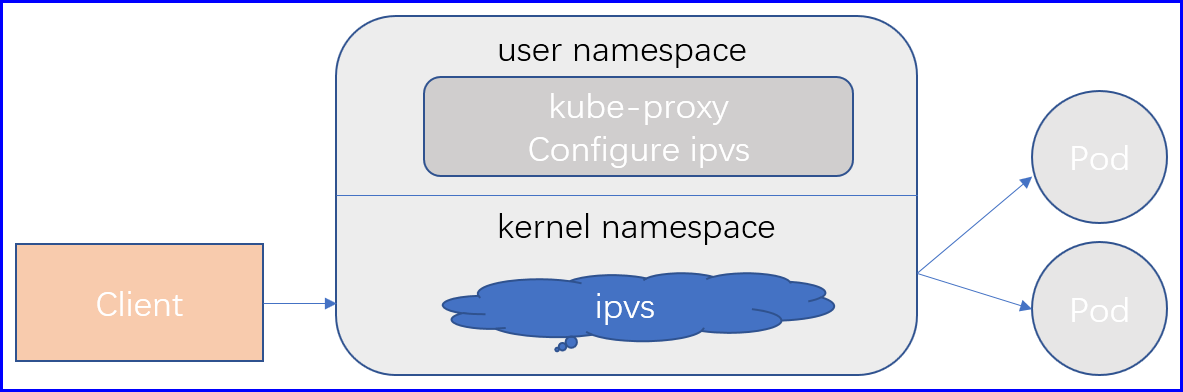
Kubernetes自1.9-alpha起引入ipvs代理模型,且自1.11版本成为默认设置,kube-proxy跟踪API server上Service和Endpoints对象的变动,根据此来调用netlink接口创建ipvs规则,并确保与API server中的变动保持同步;
它与iptables规则的不同之处仅在于其请求流量的调度功能由ipvs实现,余下的其他功能仍由iptables完成,ipvs支持众多调度算法,例如rr、lc、dh、sh、sed和nq等;
Service类型
Service其实是有多种类型的,在定义Service资源时,还有个字段叫type,它就是指定Service类型的,支持ClusterIP、ExternalName、NodePort、LoadBalancer,默认为ClusterIP;
ClusterIP
ClusterIP就是指,给一个Service分配一个当前集群上的位于Service可用网段内的动态地址,如果它是ClusterIP类型,就表示这个服务只可以被集群内机器所访问,脱离集群无法访问,那因此,如果这个Service期望暴露给集群外部的主机访问,那使用ClusterIP的不合适的;
[root@node1 ~]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: ccesvc
spec:
ports:
- port: 80 # Service端口
protocol: TCP
targetPort: 80 # 后端Pod端口
selector: # 利用标签选择器来关联后端Pod
app: cce
# 我们的Service也不是直接到后端的Pod对象的,而是通过我们的Endpoint,Endpoints表示一个Service对应的所有Pod副本的访问地址,而Endpoints Controller就是负责生成和维护所有Endpoints对象的控制器.它负责监听Service和对应的Pod副本的变化,如果检测到Service被删除,则删除和该Service同名的Endpoints对象。如果检测到新的Service被创建或者修改则根据该Service信息获得相关的Pod列表,然后创建或者更新Service对应的Endpoints对象;
# 创建一个Service会立马创建一个endpoint,kube-proxy会监控当前主机的Pod的变化,同时也会监控endpoint相关数据,一旦有后端的Pod的label符合endpoint的label就会将其加入endpoint作为后端服务端之一,如果一旦该Pod发生变化会立即剔除;
# Service关联的是Endpoint,而Endpoint通过IP地址+端口关联Pod;
# 查看当前的Pod
[root@node1 ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
cce-fcd4c8cff-bqvrt 1/1 Running 0 26m app=cce,pod-template-hash=fcd4c8cff
# 查看当前的endpoint
[root@node1 ~]# kubectl get endpoints
NAME ENDPOINTS AGE
ccesvc <none> 4m40s # 此时ccesvc后端没有Pod
kubernetes 172.16.1.2:6443 11d
# 修改Pod的label让endpoint能关联到
[root@node1 ~]# kubectl label pods cce-fcd4c8cff-bqvrt --overwrite app=ce
pod/cce-fcd4c8cff-bqvrt labeled
# 重新查看,Pod已经关联至Endpoint
[root@node1 ~]# kubectl get endpoints
NAME ENDPOINTS AGE
ccesvc 10.244.2.4:80 4m46s
kubernetes 172.16.1.2:6443 11d
NodePort
所谓NodePort是指,对于一个Service来说,它该有的ClusterIP还是有的,但除此之外,我们会在每一个节点上生成一个iptables或ipvs规则,它允许集群外部客户端去访问节点的IP地址和端口,这个节点端口是通过iptables规则进行操作的,比如说节点的80端口映射到clusterIP的80端口,然后由ClusterIP转发到Endpoint继而转发给Pod,所以外部主机通过访问节点的IP和端口就能直接访问到Pod里面的服务了,由于Service的iptables或者ipvs规则是配置的每一个节点上的,所以每一个节点的同一个端口都为NodePort提供服务;
[root@node1 ~]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: ccesvc
spec:
type: NodePort
ports:
- port: 80 # Service端口,NodePort不对丢球ClusterIP原有的特性
protocol: TCP
nodePort: 30080 # 只有type为NodePort的时候才能使用nodePort字段,这个字段一般不写,随机
targetPort: 80 # 后端Pod端口
selector:
app: cce
查看创建的Service
[root@node1 ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ccesvc NodePort 10.106.142.19 <none> 80:30080/TCP 2m38s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d
使用clusterip的方式访问,nodeport不会丢弃clusterip的特性
[root@node1 ~]# curl 10.106.142.19/hostname.html
cce-fcd4c8cff-95sch
使用nodeport的方式访问
[root@node1 ~]# curl 127.0.0.1:30080/hostname.html
cce-fcd4c8cff-95schLoadBalancer
LoadBalancer是kubernetes为NodePort类型引入自动管理的外部负载均衡器,它会向底层cloud provider的API发送请求,由其按需创建,用户也可以手动提供负载均衡器,但它不再属于LoadBalancer类型;
ExternalName
ExternalName即为外部名称,它将集群外部Service引入集群内供各Pod客户端使用,我们在创建一个Service时,不指定标签选择器,不选Pod,而是直接指明类型为ExternalName,并externalName定义一个域名,这个域名能够被我们的DNS服务器解析为外部的IP地址,而这个外部的IP地址就是外部提供服务的对应的端点,那这个时候,客户端对此服务的访问就都被转给外部的服务了。这种方式是使用名称的方式来引用的;
Service标签选择器关联Pod的主要作用在于,它能够自动的为关联到的所有Pod创建一个Endpoint资源,那对于ExternalName类型来说,没有标签选择器了,它就不会自动创建Pod,那因此我们可以手动创建一个endpoint,把它的IP地址和端口指向集群之外的主机的IP地址和端口,然后再把这个endpoint作为ExternalName这个Service的引用放,因此所有发送给这个Service的请求都会被转发到手动创建的这个endpoint上面来,从而就调度到了集群外部的主机了;
Service代理
Service能够正常的把客户请求的流量,代理并调度到后端的资源,但是Service与Pod之间并不存在必然的关系,因为Service和Pod之间间隔着一个空间层Endpoint,而Endpoint在我们使用Service时,它会自动帮我们的生成Endpoint,当然我们也可以手动去管理Endpoint,尤其是在后端资源不是Pod的情况下,Endpoint如果手动创建的话,我们可用尝试让Endpoint的名称和Service一样,使得Service能够关联至相关的Endpoint资源,从而在定义Endpoint时引入非标准的客户端Pod,因此我们就可以把集群外部的服务以手工维护Endpoint的形式,映射进集群内部来,也把它组织为Service;
同时Service也能够实现会话保持功能,常见的会话保持有三种方式,通常是会话粘性、会话集群、会话服务器,其中Service本身也能支持会话粘性的方式,它可以实现把来自同一客户端IP地址的请求,始终绑定到同一个后端Pod上,需要在我们定义Service的时候加上一个专用属性sessionAffinity,有两个选项,Node为使用调度算法进行调度,不做会话粘性,ClientIP表示使用ClientIP来做会话粘性,和nginx的iphash,lvs的sh算法;
每一个Service都是有ClusterIP的,ClusterIP也作为Service的访问入口,但是有些场景当中,我们也可以不为Service添加ClusterIP,这种Service叫做无头Service,那么存在ClusterIP的Service时,会在kubernetes的DNS当中将Service Name解析为ClusterIP,一旦没有ClusterIP,会直接将Service Name解析为后端的Pod的IP,而Pod的IP可能不止一个,因此会使用DNS的方式生成多个A记录,实现DNS轮询,这种就叫做无头Service;
Service即便能够代理,并调度客户端请求,但是它只是一个四层代理,无论是iptables还是ipvs,都是由kube-proxy来实现,所以要想实现ipvs的规则类型,需要手动修改kube-proxy的配置,因为kube-proxy决定了你的节点是映射至iptables还是ipvs规则的,在Kubernetes之上我们配置容器应用,靠的是一种资源,这种资源叫做ConfigMap,我们称为配置映射,我们可以在容器外部改一个配置映射中的配置映射的定义,这个定义能够被自动注入到,相关的Pod中的应用之上,被容器所加载和使用,而当前Kubernetes集群所使用的kube-proxy配置是位于kube-system这个名称空间中(kubectl get configmap -n kube-system),当中的kube-proxy其实就是kube-proxy容器中的应用程序所加载的配置信息,而且这是一种集中配置,我们一旦修改了这个配置文件,对所有的kube-proxy容器都是生效的,因此有一种集中配置或者说配置中心的说法;
手动修改代理方式为ipvs
启用ipvs模块
[root@node1 ~]# cat /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
ipvs_mods_dir="/usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs"
for mod in $(ls $ipvs_mods_dir | grep -o "^[^.]*"); do
/sbin/modinfo -F filename $mod &> /dev/null
if [ $? -eq 0 ]; then
/sbin/modprobe $mod
fi
done
修改configmap里面的代理方式mode: "ipvs",还可以在ipvs.scheduler字段定义调度算法,默认是rr;
[root@node1 ~]# kubectl edit configmap -n kube-system kube-proxy
安装ipvsadm控制器管理工具
[root@node1 ~]# yum install -y ipvsadm
因为创建集群时使用的iptables创建的kube-proxy,现手动删除原Pod,会自动重建
[root@node1 ~]# kubectl delete pods -n kube-system -l controller-revision-hash=68594d95c
此时我们的ipvsadm就可以看到数据了
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 172.16.1.2:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.1.3:53 Masq 1 0 0
-> 10.244.2.3:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.1.3:9153 Masq 1 0 0
-> 10.244.2.3:9153 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.1.3:53 Masq 1 0 0
-> 10.244.2.3:53 Masq 1 0 0 示例一
利用deployment控制器创建三个web服务pod,然后自定义Service,利用externalIPs向外部暴露kubernetes集群内部的Pod服务,这种Service属于ClusterIP;
[root@node1 ~]# cat pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
author: caichangen
name: ccepod
namespace: ccenamespace
spec:
replicas: 3
selector:
matchLabels:
podtype: deploy
template:
metadata:
name: ccepod
namespace: ccenamespace
labels:
podtype: deploy
spec:
restartPolicy: Always
containers:
- image: ikubernetes/myapp:v1
name: ccecontainers
[root@node1 ~]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: cceservice
namespace: ccenamespace
spec:
externalIPs: # externalIPs向外部暴露集群内部的服务的通讯地址,暴露给外部的IP
- 172.16.1.2
- 172.16.1.3
ports:
- protocol: TCP # 传输协议
port: 80 # 暴露给外部的端口
targetPort: 80 # 集群内部Pod的端口
selector:
podtype: deploy # 标签选择器,用于选择Pod
[root@node1 ~]# curl -o /dev/null -s -w %{http_code} http://172.16.1.2
200Endpoint与Service结合
其实在上面已经讲过,一个Service最终都是需要借助于Endpoint,来找到后端的Pod的,那么接下来就做一个基本的演示,主要是两个方向,第一,通过Endpoint结合Service向外部暴露Pod,虽然直接创建Service就能够实现,那么为了更接近底层,下面就分别来创建Service和Endpoint;
第二,通过Endpoint结合Service,将外部的服务,或者说安装在宿主机上面的服务,映射进Kubernetes集群,虽然我们可以直接通过宿主机的IP访问,但是为了统一化,容器化,标准化的目的,在此就将外部的服务直接整合进Kubernetes集群,作为Kubernetes集群的一个资源来使用;
注意:因为Service创建会直接创建相应的,同名的Endpoint,所以在此我们需要先创建Endpoint,然后再创建Service;
内部端点集合
内部端点集合,说白了,就是将所有Pod,融合到一个Endpoint,然后统一由一个Service来向外输出服务接口,为了详细介绍其步骤,下面就进行分段介绍,具体如下;
# 创建两个自主式Pod
[root@node01 ~]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
app: pod1
spec:
containers:
- name: pod1
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
labels:
app: pod2
spec:
containers:
- name: pod2
image: ikubernetes/myapp:v2
imagePullPolicy: IfNotPresent
restartPolicy: Always
[root@node01 ~]# kubectl apply -f pod.yaml
[root@node01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 24s 172.20.3.2 node03.cce.com <none> <none>
pod2 1/1 Running 0 24s 172.20.3.3 node03.cce.com <none> <none>
# 分别请求两个Pod,可以看到分别是v1和v2
[root@node02 ~]# curl 172.20.3.2
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@node02 ~]# curl 172.20.3.3
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
# 创建Endpoint,将这两个Pod集合到一个端点
[root@node01 ~]# cat endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: pod
subsets:
- addresses:
- ip: 172.20.3.2
- ip: 172.20.3.3
ports:
- port: 80
protocol: TCP
[root@node01 ~]# kubectl apply -f endpoints.yaml
[root@node01 ~]# kubectl get endpoints pod
NAME ENDPOINTS AGE
pod 172.20.3.2:80,172.20.3.3:80 34s
# 上面已经将所有的Pod集合在一个端点了,那么接下来就创建一个Servce,对外提供服务,Service需要与Endpoint同名
[root@node01 ~]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: pod
spec:
ports:
- port: 8080
protocol: TCP
targetPort: 80
[root@node01 ~]# kubectl apply -f service.yaml
# 看到下面,可以看出,当我们的Service创建之后,自动关联我们在上面创建的Endpoint
[root@node01 ~]# kubectl describe svc pod
Name: pod
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"pod","namespace":"default"},"spec":{"ports":[{"port":8080,"protoc...
Selector: <none>
Type: ClusterIP
IP: 10.10.17.77
Port: <unset> 8080/TCP
TargetPort: 80/TCP
Endpoints: 172.20.3.2:80,172.20.3.3:80
Session Affinity: None
Events: <none>
# 测试请求Service的地址
[root@node02 ~]# curl 10.10.17.77:8080
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@node02 ~]# curl 10.10.17.77:8080
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
# 可以发现是v1和v2,到此为止,我们的内部服务已经成功通过Endpoint结合Service进行了服务暴露外部端点集合
Kubernetes出世还不久,总的来说,还不是特别的稳定,依旧会出现各种各样的问题,所以在很多时候,我们的比较重要的服务,比如我们的MySQL服务,对于一般没有较强的二次开发能力的企业,是不会将MySQL服务放在Kubernetes之上的,所以在这个时候,我们一般都会是将其部署在Kubernetes集群之外;
所以在此处,就涉及到外部流量接入Kubernetes集群内部的问题,虽然我们的Pod是可以直接访问到我们的Node IP的,但是不如和我们追求Kubernetes化、标准化的需求,所以在此了,就利用Endpoint和Service将外部流量引入Kubernetes集群内部;
此案例就直接使用Mariadb来做测试,随便找一台宿主机,然后将其接入Kubernetes集群;
# 在集群之外的主机安装Mariadb用于测试
[root@node04 ~]# yum install -y mariadb-server
[root@node04 ~]# systemctl start mariadb
# 授权任何主机都可以连接
[root@node04 ~]# mysql -e "grant all on *.* to 'root'@'%';"
# 创建Endpoint,将node04上面Maradb加入该Endpoint
[root@node01 ~]# cat endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: mysqlconn
subsets:
- addresses:
- ip: 172.16.1.4
ports:
- port: 3306
[root@node01 ~]# kubectl apply -f endpoints.yaml
# 创建Service,将上面的Endpoint提供一个固定的访问端点
[root@node01 ~]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysqlconn
spec:
clusterIP: 10.10.0.10
ports:
- port: 30000
protocol: TCP
targetPort: 3306
[root@node01 ~]# kubectl apply -f service.yaml
# 查看创建出来的Service,可以看到我们的ServiceIP,并且我们的连接端口为30000
[root@node01 ~]# kubectl describe svc mysqlconn
Name: mysqlconn
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"mysqlconn","namespace":"default"},"spec":{"clusterIP":"10.10.0.10...
Selector: <none>
Type: ClusterIP
IP: 10.10.0.10
Port: <unset> 30000/TCP
TargetPort: 3306/TCP
Endpoints: 172.16.1.4:3306
Session Affinity: None
Events: <none>
# 创建一个测试的自主式Pod,用于测试连接
[root@node01 ~]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: mclient
labels:
app: mclient
spec:
nodeSelector:
kubernetes.io/hostname: node02.cce.com
containers:
- name: mclient
image: widdpim/mysql-client:latest
imagePullPolicy: IfNotPresent
command:
- /bin/sleep
- '10000000000'
restartPolicy: Always
[root@node01 ~]# kubectl apply -f pod.yaml
# 进入Pod,测试通过ServiceIP连接外部的Mariadb
[root@node01 ~]# kubectl exec -it mclient -- bash
[root@mclient /]# mysql -h 10.10.0.10 -P 30000
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 4
Server version: 5.5.60-MariaDB MariaDB Server
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
# 测试连接成功