TOC
Devops之容器理念
我们以往在去实现负责去安装部署应用程序的时,比如nginx,varnish,我们要去实现部署,实现应用,手动去部署非常麻烦,所以后来我们有了运维工具,像ansible,它实际上就是一个应用编排工具,它能够安装、配置、服务启动甚是还能让你对多种应用程序在实现有依赖关系时的依赖部署,按照playbook的方式执行,从而完成我们人需要手工执行的运维任务。所以它能够实现把我们运维手动执行的应用程序的任务转换为用另一个编排工具或者我们称为应用程序本身,能够实现的功能,把我们的日常的运维任务给注入到应用程序当中来实现,这就是ansible;
同样的,我们的Docker,那么以为我们手工管理的对象是直接部署在操作系统环境当中的应用程序,但是有了docker之后我们的应用程序就由容器来跑,各种应用程序都被封装在容器中执行,那么我们在使用ansible去编排应用程序时,它的对象已经发生变化了,这个时候我们已经不再是ansible或者puppet这样的编排工具的适用场景了,因为容器化所提供的接口与我们早期传统意义上应用程序的访问、控制和管理接口是有所不同的。所以Docker时代就它就呼唤面向容器化的编排工具的实现;
所以docker出现之后随之而来,编排工具就立即出现了,比如docker自身提供的docker-compose,但是docker-conpose只适用于单机编排,因此docker就不额外提供一个工具能够将多主机的Docker Host,假设我们有很多docker主机,我们期望在编排的时候不是只有一台,而是一定意义上或者一定程序上的调度效果,真正意义上面对集群的编排效果,于是Docker后来就提供了另外一个工具,就是docker swarm,它能够将多个docker host整合为同一平台之下的管理机制的一个集群工具,能够将多个Docker Host所提供的计算资源,给他们整合在一起,整合为一个资源池,随后docker-conpose在去编排时,只需要面向swarm整合出来的这些资源池进行编排就行了,而无论底层到底是什么样的docker主机。
当然docker swarm实际上也是一个应用程序,docker自身的一个应有程序,那么对于每一个主机,想要加入docker swarm的资源池,成为docker swarm的成员,它首先自己得是一个docker主机,如何加入docker swarm的成员呢,我们需要另外一个工具docker machine,它能够将一个主机迅速初始化满足加入docker swarm的先决条件,从而能够能够成为docker swarm的一分子的这么一个处理工具,这就是docker编排的三剑客(docker-compose、docker swarm、docker machine),这种编排工具不再是面向单机之上去编排应用程序,就像我们的ansible本来就可以面向多台主机执行应用程序编排的,那么容器也需要多机执行编排,而且更重要的是我们在运行容器时,这个容器在不同主机之上编排时可能运行同一个应用程序,同一个应用程序如何运行在不同主机不相互冲突,各种任务,也都需要容器编排工具来实现;
其实除了docker自身的这些编排工具之外还有第二类,mesos能够把一个IDC当中所提供的硬件资源统一调度和分配,但是它所提供的上层接口不是容器运行的接口,而只是一个资源分配的工具,非能够直接托管运行容器的,所以在此基础之上,它还需要提供一个面向容器编排的框架叫做marathon;
然后我们的Kubernetes就面世了,一度占据百分之八十的市场份额,这就是我们所说的容器编排;
说到容器编排,其实除了容器编排之外呢,我们在IT的工作领域当中,通常还涉及另外一些概念,比如Devops,MicroServices,Blockchain,这些概念层出不穷的,我们对应的开发模式也是不停的发生变化,比如早起,我们的瀑布式到后来的敏捷开发精益开发等,以及现在把我们的QA运维以及开发整合起来形成Devops所谓应用模式的开发,而应用程序的架构从早起的单体架构,把所有的功能全部放在一个软件中,后来人们发现单体应用程序之能跑在一个主机之上,就算我们横向扩展,而单体内部的复杂度很容器达到上限,于是我们把单体进行拆分划分为分层架构,在往后就是微服务,到现在为之,不仅仅是进行分层,而是把每一个应用都拆解成一个微小的服务只干一件事,很有我们的传统的单体应用程序到现在为止我们要拆解成数百个微服务,让他们彼此之间进行协作,那微服务彼此之间的调用关系就比较复杂了,如何确保调用者或者被调用始终都是存在的,因此现在很多的微服务基本上都是运行在微服务之上的,利用容器本身的特性,分发部署都非常方便,所以这些特性,使得微服务和对应的容器结合起来之后,迅速的,找到了一个好的微服务解决方案,包括devops也是如此,另外因为Devops的技术中的交互环境和部署环境导致部署起来极其困难,恰恰容器的出现完全弥补了这个问题,使得Devops非常容易实现;
Devops理念
Devops,也就是CI(持续集成)CD(持续交付)CD(持续部署),应用程序交付在运维人员之前,一般来讲需要一个开发团队,做架构设计、做开发、开发完成之后还要做构建然后测试,回滚,测试,验收,上线等等流程,在交付给运维之前开发完成之后这个过程,如果它能够自动实现,我们就把它称为持续集成的过程,整个环境的需要人工的环节只有一个就是开发代码。
集成完成之后就该交付给运维进行部署了,那么交付给运维是这样的,测试通过后自动打包到一个可以被运维拿到的一个共享的文件服务上,或者是一个仓库当中,让我们运维人员能够得到打包好的构建好的最终产品,把这一步也能自动实现,那这就叫做持续交付。
我们运维拿到最终产品之后就是做部署的,假设我们运维人员拿到之后也不需要做部署,一旦交付完成之后,我们有一款工具能够自动把这套代码拖出来,把它自动发布到对应的线上环境,那么这就叫持续部署,而这一切能自动循环实现,就称之为Devops;
以后这正个自动持续化的流水作业,恰恰是容器技术的实现,使得这些流程能以落地,原因在于,我们构建好的产品,要能够部署在对应的平台上,因为有的客户有的是windows环境有的是linux环境也有ubuntu环境,这种复杂的异构环境,这样的话我们的原始的方式会使得我们构建部署真正面向不同的平台,那代码是没法通用的,要实现交付部署是非常的困难的;
我们为了每一种目标环境,就不得不构建一种适用的目标版本来,但是有了容器之后,这就变得简单了,只要我们的目标平台能够适用容器,那么我们就可以直接将我们的应用程序打包成镜像直接启动起来,而后不管是什么平台,把镜像运行为容器即可,使得自动部署变得极为简单,因此正式容器技术的出现,使得devops在落地上,就完全实现了可能,这就是容器技术带来的好处;
容器技术
以后我们把服务都构建成容器的话,很显然他们不可能运行单个主机之上,那么如果运行在多个主机之上的时候,那哪些容器是内部通信,哪些容器需要面向对外通信,他们如果做编排谁被谁所依赖,这是一个非常非常麻烦的关系,我们要人工管理这就变得极为复杂了,如果我们在走向微服务化之后,假设我们有200个服务,对于应用程序来讲,出故障是必然的,指不定哪一天几个几十个的出故障,人工去监控,人工去修复是完全来不及的,而且它内部的复杂度,我们靠人的脑子去记录,那几乎是不可能的;
所以对于现今最好的解决方案也就是容器化编排工具来实现,而后devops这种技术落地的时候,我们需要它应用程序平台进行容器化,这就使得我们的容器编排被进一步需要和依赖,因此恰恰是容器的实现,使得devops得以迅速的流行,而恰恰是容器技术的实现使得我们的容器编排成为我们底层必备的工具,所以我们很多的devops环境有可能都是构建在容器编排环境之上的,也正式如此,编排工具自身并不提供devops环境,需要在掌握了容器编排工具之后把devops这种思想这种文化给它落地于容器编排平台之上,devops本身并不是一种技术,是一种文化,是一个追求,用容器化工具化去解决问题,让我们去突破dev和ops之间的屏障,使得大家可以协同起来工作;
Kubernetes
Kubernetes其实出现的时间并不长,大概只有区区几年的时间,Kubernetes它的全程是舵手,它主要是由google的几位员工所创立的,大概2014年面世,所以到今天为止,也短短五年的时间,Kubernetes的开发深受Google内部的Borg系统的影响,Borg是Google内部的大规模容器集群容器管理系统,一直是内部使用,但是后来,容器技术被民间掌握以后Google发现,可能话语权要旁落的时候,他们就迅速,组织了几个人把Borg系统用go语音重写了一遍,借助了Borg的使用思路从头进行构建,所以说短短几年的时间Kubernetes的发展是非常迅速的,也正式Kubernetes是站在Borg的肩膀上的,于是出世开始,它就吸引了大量的技术人员的关注;
Kubernetes其实1.0版本,大概在2015年7月份发布,但是到今天为止Kubernetes的版本已经到了1.11版本,Kubernetes的代码托管在github之上,2017年是容器技术,是容器技术发展非常具有里程的一年,其中AWS、阿里云等这些著名的云计算公司都开始宣布原生支持Kubernetes,说白了就是允许用户创建几个VPS点击几个按钮帮你快速构建Kubernetes集群,让用户直接可以在上面部署Kubernetes应用,这就我们称之为云原生应用,也正式这些大型云厂商的支持,是的Kubernetes在业内已经受到了广泛的认可和支持,而且大概在2017年的十月份docker官方宣布,同时在他们的平台上支持Kubernetes和swarm两种工具,swarm本来是docker拿来视图竞争容器编排的标准的一款工具的后来也不得不把Kubernetes直接整合自己的产品才能获得客户的认可;
Kubernetes特性
自动装箱:基于资源极其依赖约束,能够自动完成容器的部署而且不影响其可用性;
自我修复:一旦一个容器挂了,它能够自动一秒启动一个新的容器,既然如此一个应用程序蹦了,就没有必要去修复它,直接kill容器,会重新启动一个新的容器,所以有了Kubernetes这种容器编排之后,我们更多的关注是群体而不是个体了;
水平扩展:自动实现水平扩展,一个容器不够再启动一个,无限扩展,只要你的物理平台的资源支撑是足够的;
服务发现/负载均衡:当我们需要在Kubernetes上运行一个程序的时候,程序和程序之间的关系,像微服务如果依赖一个服务那么Kubernetes能够通过服务发现的方式找到依赖的服务,更重要的是,每一种服务如果我们启动了多个应用程序,它能够自动实现负载均衡;
自动发布和回滚:当上线代码出现问题的时候,可以自动实现发布和回滚;
密钥和配置管理:容器化应用程序的最大的问题在于,我们所配置应用程序比较苦难,我们基于镜像启动一个容器之后,我们如果期望容器中的应用程序换一种配置文件,那么我们就可以使用配置管理来实现,类似我们的docker的环境脚本,实现云配置的集中化;
存储编排:把存储卷实现动态供给,也就意味着,某一个容器需要用到存储卷的时候,根据容器自身的需求创建能够满足它需要的存储卷,实现存储编排;
任务批量处理执行:批量执行各种容器任务;
Kubernetes架构
Kubernetes其实就是一个集群,组合多台主机组成一个大的资源池,并统一对外提供计算、存储等能来的集群,这个集群就是,我们找许多太主机,每一台主机之上都安装上Kubernetes的相关应用程序,这个程序之上进行通信,从而完成彼此间的协调,并通过这个应用程序协同工作,把多个主机当一个主机来使用;
集群有两种常用模型,第一种是P2P没有中心节点,每一个节点都能够接受用户请求,第二种是有中心节点的集群,比如像MySQL的主从复制,只有一个是主节点,其他都与他进行同步,这就是中心节点。在Kubernetes就是属于这种有中心节点架构的集群系统,从这个维度上来讲,它被叫做master/nodes集群,有一组节点用来扮演主节点当然也可以有备份节点,nodes我们把它称为worker提供工作的节点,架构特点如图
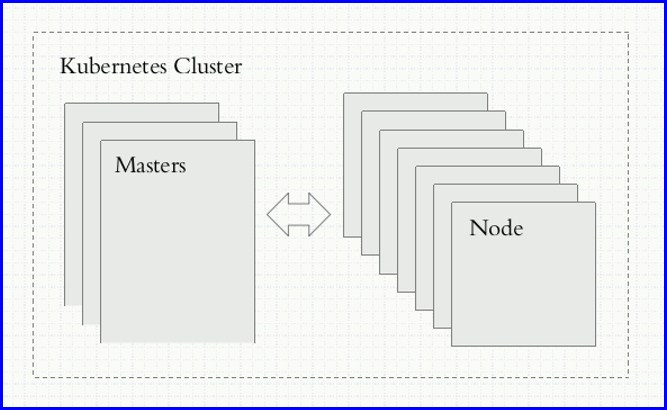
当用户需要在集群中运行容器的时候,首先向master发送创建请求,master当中有一个调度器,去分析各个node现有的可用资源状态,找一个最佳适配运行用户所请求的容器节点,另外还可以调度上去,由这个node本地docker或者其他的容器引擎负责把这个容器创建并运行起来,要启动容器就需要镜像,所以这个node首先需要检查本地是否有镜像,如果没有那么就去docker hub或者私有registry上pull然后再启动,因此我们的Kubernetes Cluster自身并有所需要的容器镜像,我们需要在镜像仓库进行下载,因为registry本身也可以运行为一个容器,所以我们的registry也可以交给我们的Kubernetes这就是所谓的Kubernetes的功能模型;
接受请求的是我们的Kubernetes Cluster,提供服务让客户端能够访问,我们就需要向外输出一个套接字向外提供服务,而且套接字向外提供服务通畅都是API,都是API接口,所以我们的客户端要么编程访问,要么有专门编好的客户端程序访问,Kubernetes也的确把master上的一个功能组件称为叫API Server,API Server只是负责接受请求,解析请求,处理请求的,如果用户请求是需要创建一个容器,那么这个容器不应该运行在master之上,而是node之上,那么哪个node可用,那么就需要我们的调度器来决定,所以master之上还有一个非常非常重要的组件叫做调度器,我们称之为Sheduler,它负责去观测每一个node之上总共可用的计算和存储资源,并根据用户所请求的资源了进行分析,我们Kubernetes我们不但能够设定资源上限还能设置资源下限,我们称为请求量,意思就是一旦请求那么必须确保对应的node上有能够支撑的资源量,所以调度器就需要进行评估,哪一个节点更合适,为此Kubernetes设计了一个两级调度的方式来做调度,第一步先做预选,哪些服务器是符合要求的,比如有10台服务器,选出来有3台符合,然后再对这三个进行优选,从这个三个中再选择一个最优的节点;
如果我们这个node上把这个容器启动起来了,万一容器中的应用程序,出现问题,Kubernetes也可以做容器内部的服务的可用性,一旦容器内部的应用挂了,这个服务器之所以能够成Kubernetes的成员那是因为这个服务器之上安装了一款软件Kubelet,这个应用程序可以确保这个容器可以确保始终处于可用状态,所以Kubernetes还设计到一大堆的控制器的应用程序,让你们去监控容器是否是健康的,一旦发现不健康,控制器就负责向master发送请求,让master再挑选一个node重新启动一份容器来做替补,因此这儿有个组件叫做控制器,这个控制器还需要在本地不停的loop进行周期性探测容器是否健康,以确保容器的健康;
一个控制器可以监控多个容器,那么我们的控制器挂了,那么容器的健康就无法保证了,那就是下一个组件了,叫做控制器管理器,控制器管理器负责健康每一个控制器是健康的,如果控制器不健康了,由控制器管理器来确保健康的,控制器管理器还可以做冗余,所以从这个角度来讲,master是整个集群的大脑,它有三个大组件,第一API Server负责接收和管理请求的,第二Sheduler调度容器创建的请求,第三控制器管理器Controller-Manager,确保创建的控制器是健康的;
在Kubernetes上最小的运行单元不是容器,叫做Pod,Kubernetes不直接调度容器的运行,它调度的是Pod,Pod可以理解为是容器的外壳,给容器做了一层抽象的封装,所以Pod变成了Kubernetes系统之上最小的调度的逻辑单元,它内部主要是用来放容器的,但是Pod有一个工作特点,Pod可以将多个容器联合起来,加入到同一个网络名称空间去,也就意味这个Kubernetes作为一个逻辑组件叫Pod,在Pod里面用来运行容器,一个Pod都包含多个容器,这个多个容器共享同一个底层的网络名称空间Net、UTS、IPC另外三个User、Mount、PID互相隔离的,所以这样一来可以发现一个Pod可以运行多个容器,对外他们更像一个虚拟机,所以Pod是用来模拟传统的虚拟机的,这算得上是Kubernetes在组织容器上一个非常精巧的方法,使得我们可以构建较为精细的容器间通信了,这就是Pod,而且同一个Pod内的容器还可以共享同一组存储卷资源,加入我们要定义一个存储卷让一个Pod的第一个容器可以访问,那么第二个容器可以共享挂载同一个存储卷,从这个意义上来讲存储卷不再属于容器,存储卷属于Pod,好像Pod虚拟机的磁盘,同一个虚拟机的多个名称空间可以访问同一个目录,那么各node主要运行的是Pod,但是一般来讲,一个Pod内只运行一个容器,除非容器间的程序有特别特别紧密的关系,需要放在同一Pod中,另外如果在同一个Pod内要放置多个容器,那么一般来讲有一个容器是主容器,其他容器是为了辅助主容器应用程序完成更多应用功能来实现的。
所以我们的调度器调度的也是Pod,我们的node运行的也是Pod,Pod是一个原子单元,也就意味这个一个Pod内不论是一个容器还是多个容器,一旦我们把某个Pod调度在某个node上来运行之后,这一个Pod上面所有的容器之内运行在同一个node之上;
node是Kubernetes集群的工作节点负责运行由Kubernetes集群中master指派的任务,而最根本的是它的最核心的任务是以Pod的形式去运行容器的,理论上讲,node可以是任何形式的计算设备,只要有传统意义上的CPU、内存啊等并且能够装上Kubernetes集群的代理程序它都可以作为整个Kubernetes集群的一个分子来进行工作,因此Kubernetes的实现效果就类似于如图
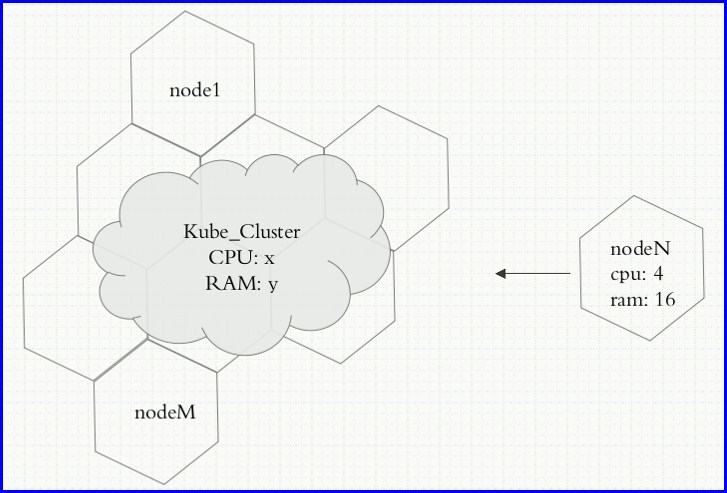
node1、node2、node3...nodeN都向Kubernetes Cluster资源进行资源共享由Kubernetes来进行管理,我们的master也就有了这么一个所谓的资源视图,当用户请求在master创建资源时,master可以在这个资源池进行资源调度和评估,这么一来用户就无需在关心,我们的应用到底运行在哪一个节点上了,所以它的调度和编排,脱离了终端用户的视线,用户无需再关注Pod运行在哪一个node之上,真正的实现了,把统一的资源池,来进行统一管理,但是这里都需要注意的问题是,这么多的Pod都运行在一个集群当中,我们将来想要分类,如果要删除某一类Pod,那如何是删除,我们想要我们的控制器只监控我们某一类Pod怎么去实现,这么多的Pod我们不可能通过Pod的名称来识别,名称也不是固定的唯一的名称,如果我们想要对Pod进行分组,它如何检测某一个是某一组呢,因此为了能够实现Pod识别我们需要在Pod之上附加一些原数据,类似我们的Dockerfile当中的label,我们在Kubernetes去标识Pod之上也是用标签来识别Pod,我们创建完Pod之后可以给Pod打上标签,让控制器或者用户能够通过这个标签的值来识别Pod;
标签是我们以后在Kubernetes集群中去管理大规模Pod的一个非常重要的一个途径和凭证,因此我们需要把某个或多个需要的Pod找出来,那么就可以直接使用我们的标签进行过滤了,而过滤的机制我们也需要一个组件来实现叫做seletor,我们一般把它叫做标签选择器,可以根据标签,来过滤符合资源的Pod,标签不止Pod可以用很多其他的资源都可以用,Kubernetes的API Server是一个restfull风格的API,通过http向外提供服务,因此restfull当中所有向外输出的都是对象,所有的对象都可以拥有标签,所有的标签都可以使用标签选择器进行筛选;
总结
Kubernetes是master/node框架
master的组件有:API Server、Scheduler、Controller-Manager
node组件有:kubelet、容器引擎(Docker)、kube-proxy
Pod组件有:Label、Label Selector
Kubernetes域名解析:服务名.命名空间.svc.cluster.local