TOC
Functools
Functools模块在之前用到过,比如partial、wraps、update_wrapper等,Functools里面其实还有一些其他的函数,比如reduce、和partial,Functools模块可以说主要是为函数式编程而设计,用于增强函数功能;
reduce
reduce顾名思义,就是消减的意思,主要用于做数据统计方向,详情见《高阶函数》;
partial
partial,即偏函数,主要就是把函数部分的参数固定下来,相当于为部分的参数添加了一个默认值,形成一个新的函数并返回,从partial生成的新函数是对原函数的封装,partial逻辑其实很简单,主要要知道newkeywords.update(fkeywords),它是可以覆盖原有值的;
# 以下,其实就是partial的内部实现逻辑
def partial(func, *args, **keywords):
def newfunc(*fargs, **fkeywords):
newkeywords = keywords.copy()
newkeywords.update(fkeywords) # 关键部分
return func(*(args + fargs), **newkeywords)
newfunc.func = func
newfunc.args = args
newfunc.keywords = keywords
return newfunc
from functools import partial
def add(x, y):
print("x的值为:%s,y的值为:%s" % (x, y))
return x + y
f1 = partial(add, 1) # 这个1就赋予给了x,实际上就将add函数包装成了def add(x=1,y)
print(f1(5))
f2 = partial(add, y=1) # 这个1就赋予给了y,实际上就将add函数包装成了def add(x,y=1)
print(f2(2))
# x的值为:1,y的值为:5
# 6
# x的值为:2,y的值为:1
# 3
f3 = partial(add, 1)
print(f3(2, 3)) # 此时就会报错,因为在上面的partial(add, 1)以及给x赋予了一个值为1,下面又给定了一个1,此时就会多处一个参数
# 当然,此时,如果我们使用关键字传参则能解决这个问题,因为它是直接update,可以覆盖原有值的
print(f3(x=2, y=3)) # ,此时x从1就变成了2
wraps
wraps其实只是一个包装函数,它的主要实现就是将update_wrapper包装成便函数形式,可以看到下述源码,首先update_wrapper是一个装饰器元数据修改函数,需要提供四个参数,而wraps呢,它内部就是将update_wrapper修改为偏函数形式,可以看到wraps函数,需要提供三个参数,其中只有wrapped没有默认值,需要用户显式给定,然后这三个参数都传给了具有四个参数的update_wrapper,那么接下来就剩一个参数没有了,即wrapper,那么现在就一共有两个参数没有给定了,即wrapper和wrapped说到,这一点,应该基本可以想到,偏函数,那么如果利用便函数就需要这样去使用wraps,如wraps(wrapper)(wrapped),其中wrapper为被包装函数,wrapped为包装函数,即装饰器内层函数;
看到这一点,就是偏函数,偏函数就是将一个多参函数对一部分参数赋予默认值,从而生成一个新的函数;
# 源码
from functools import partial
WRAPPER_ASSIGNMENTS = ('__module__', '__name__', '__qualname__', '__doc__',
'__annotations__')
WRAPPER_UPDATES = ('__dict__',)
def update_wrapper(wrapper,
wrapped,
assigned = WRAPPER_ASSIGNMENTS,
updated = WRAPPER_UPDATES):
for attr in assigned:
try:
value = getattr(wrapped, attr)
except AttributeError:
pass
else:
setattr(wrapper, attr, value)
for attr in updated:
getattr(wrapper, attr).update(getattr(wrapped, attr, {}))
wrapper.__wrapped__ = wrapped
return wrapper
def wraps(wrapped,
assigned = WRAPPER_ASSIGNMENTS,
updated = WRAPPER_UPDATES):
return partial(update_wrapper, wrapped=wrapped,
assigned=assigned, updated=updated)
---
# 实现
from functools import wraps
def timer(func):
@wraps(func) # 等价于 wrapper=update_wrapper(func)(wrapper)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
stop_time = time.time()
return result, stop_time - start_time
return wrapper
lru_cache
即缓存,采用最近最少的策略来进行缓存处理,它是一个装饰器函数,主要是作用是利用内存的空间暂时存储数据,因为磁盘IO、网络IO慢,所以在写程序的一个重要优化原则就是,一些高频使用的数据能放内存就放内存,有反复利用的特性,这就是缓存;
在functools中的lru_cache,采取最近最少的原则进行数据缓存,lru_cache有两个参数,maxsize和typed,其中maxsize的意思为,最多缓存多少个记录,当maxsize是二的幂时,LRU执行功能最好,typed表示是否启用类型,如果为None则无限大,如果为True表示不同类型的函数参数将单独缓存,默认为False,不检查类型,例如f(1)和f(1.0),此时一个是int一个是float,他们将分别进行单独缓存;
# 案例一
import time
from functools import lru_cache
@lru_cache()
def cce(x):
time.sleep(3)
return x
print(cce(1)) # lru_cache会记录函数的调用和输出信息
print(cce(1)) # 第二次调用将不回调用add,而是直接从缓存中获取,所以速度很快
# 案例二
import time
from functools import lru_cache
@lru_cache()
def cce(x, y):
time.sleep(3)
return x + y
print(cce(1, 2))
print(cce(x=1, y=2))
print(cce(y=2, x=1))
通过上述的案例二可以看到,cce(x=1, y=2)和cce(y=2, x=1)是会走缓存的,但cce(1, 2)和cce(x=1, y=2)是不会走缓存的,由此可以判断出,cache是和函数如参是有关系的,同时,我们还没有启用typed,如果启用typed根据参数类型的不同,走缓存的方式也会不同;
lru_cache内部使用了字典,然后将字典作为了缓存使用,那么缓存最重要的指标是命中,对于一个字典来讲,要命中其实就是找KEY,所以KEY是关键,lru_cache的KEY是根据源码内的一个_make_key来生成的,而相对于lru_cache判断key是否相等是根据内容比较的而非id值;
斐波那契数列加速
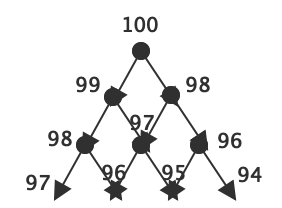
根据斐波那契数列的递归原则,使用lru_cache为其加速的效果是非常明显的,如下;
# 增加缓存的斐波那契数列
from functools import lru_cache
@lru_cache()
def fib(n):
return 1 if n < 3 else fib(n - 1) + fib(n - 2)
print(fib(100))
经过上述示例测试,可以看到,速度比原来快了几十个量级,因为lru_cache默认以字典形式存储128值,那么我们可以这样想,假设我们fib(100),那么首先第一个会进行fib(100)来计算结果,那么会被分解成fib(99)和fib(98),fib(98)会被分解为fib(96)和fib(97),当fib(98)这一轮以此计算完了之后,数据会进行缓存,那么因为fib(99)又会分解成fib(98)和fib(97),因为前面的fib(98)、fib(97)、fib(96)、fib(95)...都已经缓存了,所以此时就不再进行计算,而是直接从缓存里面获取数据,如下图,由于分支太多,就画到91,此时,我们便可以明白为什么速度会加快了,因为100下面的99的分支已经将99、98、97...1都计算完了,然后全部也缓存了,因此100下面的98分支下面的所有子分支直接从缓存就能取到结果,所以速度提升非常之大;