1、文件操作
I/O操作
文本文件操作
文件指针
buffer缓冲区
buffer参数
encoding编码
其他参数
生成器操作文件
文件描述符
上下文管理
StringIO
BytesIO
内存文件对象上下文管理
file-like对象
文本文件操作
文件指针
buffer缓冲区
buffer参数
encoding编码
其他参数
生成器操作文件
文件描述符
上下文管理
StringIO
BytesIO
内存文件对象上下文管理
file-like对象
I/O操作
文件是放在磁盘上的,所以它是磁盘的I和O的操作,大多数情况下,我们不可能把数据永久的放在内存当中,它得存在磁盘当中,我们将这个过程称之为持久化操作;
所以说内存中的数据持久化到磁盘上这是非常重要的,但是如果在存储过程中,服务器意外断电,意外断电时磁盘正在读写过程中,磁盘是很容易损坏,这一损坏数据也就完了,所以说,磁盘的高可用是非常重要的,还有,不管是固态硬盘还是传统的机械硬盘,都有一个毛病,就是慢,比内存慢,所以我们又不得不持久化操作;
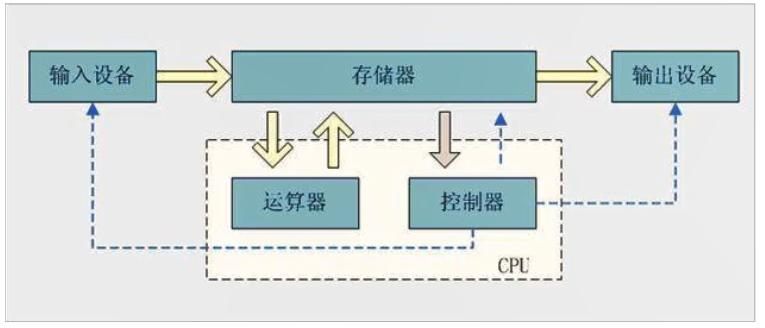
冯诺伊曼体系,CPU两个、IO两个那么就剩下一个存储器了,这个存储器特指内存,掉电丢失,内存仅仅比CPU慢,所以说内存的频率相对来说还是比较高的,内存的颗粒就适合于快速访问、告诉访问,但是内存的这种芯片颗粒,一般来说,保证了速度,就没法保证掉电之后数据依旧存在;
如果要掉电保存,那它的速度就上不去,这是内存的性质决定的,目前来讲,现在的科技的水平也就这样,所以对我们来讲,内存掉电易失,磁盘掉电数据除了损坏意外数据是不会丢失的,所以我们必须把大量的数据想办法搬到磁盘上去,我们也需要将大量的数据从磁盘加载到内存中去,一个是读取的过程一个是写入的过程;
那么说,这里面就需要通过CPU来控制,控制内存中的数据和磁盘中的数据,要么读入内存要么写入磁盘,但是为了解放CPU,在CPU加入了其他芯片,DMA芯片,用这些芯片来解放CPU,因为写磁盘太慢了,但是CPU还是要参与的,只不过不像以前,全程参与,这样CPU可以有更多时间来计算其他的待计算项;
IO设备有很多,还有一个设备,也就是网络,网络可以I也可以O,我们通过网络可以将数据发送出去,也可以将数据收回来,所以它也是IO设备,那么到底是磁盘IO大,还是网络IO大,这两种IO大会影响系统性能,导致系统的压力非常大,一般系统的瓶颈也就在此两项;
所以在编写程序时,我们都需要注意,但凡是访问IO,自己要清楚的知道,这是否会是系统或者整个程序的瓶颈所在,比如要不要过多的去访问IO,频繁不频繁,影响不影响性能;
文本文件操作
Python对于文件操作有很多方法,如打开文件、追加文件、写入文件、读取文件等等,在操作文件的时候,我们要格外注意打开模式,和编码,因为这直接影响到文件是否可写入,可编码,并且在写入文件时,对打开的模式也是有要求的,如果我们是以bytes的方式打开文件,那么我们在写入的时候,也必须使用bytes的形式写入,如果我们使用文本方式打开,那么我们就必须以字符串的形式写入;
Python在操作文件的时候,众多方法是可以混用的,比如r可以搭配w使用,也就是rw,可读可写,具体方法如下;
open:打开文件;
file:打开的文件路径,可以是绝对路径也可以是相对路径;
mode:打开文件的模式;
r:以只读方式打开,如果文件不存在会抛出异常;
w:以只写的方式打开,如果文件不存在,重新创建,如果文件存在内容将会被清空;
a:以尾部追加的形式打开,如果文件不存在则创建;
x:以只写的方式打开一个不存在的文件,文件如果实现存在则会报错;
t:以文本模式打开文件,也就是经过decode之后的字符串模式,配合r使用;
b:以bytes模式打开,也就是没有经过处理的数据,encode之后的数据,配合r使用;
+:为r、w、a、x提供缺失的读写功能,但是获取文件对象依旧按照r、w、a、x自己的特征,如果使用r+,文件不存在依旧跑出异常,并且+模式不能单独使用,它只是用来增强的;
encoding:以什么编码解析文件内容,如果文件内容包含非英文,那么编码一定要注意,否则会出现乱码;
read:读取文件,直接读取所有数据,也可以指定大小;
write:写入文件;
close:关闭打开的文件;
readline:返回一行,或者指定行,行界定符以换行符为准;
readlines:返回多行,如果未指定具体几行,返回全部行,以List形式呈现;
seek(offset[,whence]):文件指针操作,单位为字节,并非字符;
whence:
0:缺省值为0,表示从头开始,offset只能是正整数;
1:缺省值为1,表示从当前位置开始,offset只接受0,二进制模式下可正可负;
2:缺省值为2,表示从尾部开始,offset只接受0,二进制模式下可正可负;
tell:获取当前指针位置;
flush:将内存中的数据同步到磁盘;
buffering:缓冲区,-1为缺省值,如果是二进制模式,大小默认是4096或者8192;文件指针
文件指针,即读取的位置,在r模式下,文件指针起始位置是0,a模式起始位置在EOF,也就是尾部,如果是w,那么就会从0开始,x也是从0开始;
需要注意的是,seek指针操作是以字节为单位操作的,所以我们在操作字符的时候,需要特别注意,如果使用的是unicode编码,那么可能会出现问题,因为utf-8是使用的两个字节,比如我们取一个utf-8文本的中文,如果我们seek(1),然后read很可能会出错,因为每个中文占用4个字节,;
f=open("test","wb+")
f.write("蔡".encode("utf8"))
f.seek(1)
f.read().decode("utf8")
f.close()
# 抛出如下异常
# UnicodeDecodeError: 'utf-8' codec can't decode byte 0x94 in position 0: invalid start bytebuffer缓冲区
对于IO设备都有所谓的缓冲区,我们在写入文件的时候,会先写入缓冲区,在读出的时候也会先读到缓冲区,因为系统将数据写入磁盘的时候,是一批一批的写,而不是直接就全部写入磁盘,那么磁盘在做读取操作时,它也是一批一批读取的,一批一批读取出来之后,它会将这个数据放到一个缓冲区当中,至于读多少那就是程序员自己定了;
写入也是一样,也是先写入缓冲区,写入缓冲区之后并不会直接立即写到磁盘,在某些条件满足时,系统会自动进行写入操作,除非我们强制的将缓冲区中的数据flush到磁盘中,这个和磁盘的工作原理是有一定关系的,因为磁盘的IO能力实在是太慢了,所以并不能达到我们要将数据写入磁盘就立即能写入到磁盘中去,CPU也不可能一直等待着它完成写入操作,所以为了解放CPU增加了DMA芯片,CPU一旦要写数据到磁盘了,就会直接将这个任务交给DMA芯片,由这个DMA芯片来组织,然后驱动磁盘,将这个数据写入到磁盘中,所以它是一批一批写的,像这样的数据,它是会写入缓冲区的,当达到一个阈值的时候,才会写入磁盘,如果还未写入磁盘,停电了,那么数据也就丢失了;
我们对文件对读写操作,实际都是在缓冲区上操作的,与我们直接打交道的是缓冲区,并非磁盘,因为我们对文件操作,实际上调用的是操作系统给我们提供的这种文件系统的子系统能力,所以我们不可能直接操作磁盘的,因为操作磁盘需要驱动程序,驱动程序这么底层的东西,用户是无法触及的,所以这种高级操作是交给操作系统来负责的,所以操作系统就有了缓冲区的概念,读写IO是直接与缓冲区交互的;
缓冲区有缺省大小,Python3为默认8192k,一般来讲,操作系统默认的文件最小单位为4k,也就是说够不够4k也使用4k来表示,所以小文件一向是个问题,浪费空间在做文件操作时,也比较消耗效能,当我们在拷贝一个4G的单文件和一个4G的文件夹里面有成千上万个小文件时,会发现,大文件在拷贝的时候,会快得多得多,而小文件不仅慢,还极大的消耗系统资源,因为每复制一个小文件,都需要去操作系统的文件系统的元数据表里面去查询这个文件所在的地址,找到文件从那个扇区开始,和哪个扇区结束,就反复的定位,而且每次定位取一个字节就没了,所以小文件存储浪费空间,查找起来麻烦;
import io
print(io.DEFAULT_BUFFER_SIZE) # 8192buffer参数
这个buffer是我们存取数据之前,要中转的地方,我们的读取和写入都要经过这个缓冲区,那么这个缓冲区在操作文件时大多数情况我们必须得考虑它,如果是二进制模式, 默认都Buffer_Size是4096或者8192,如果是文本模式、行缓存、终端设备,如果不是则使用二进制模式的策略;
buffer称为缓冲区,是一个FIFO队列,缓冲区满了,或者某些指标达到阈值之后,数据就会自动flush到磁盘,在每满或者每达到特定的阈值之前,数据会先暂存在buffer空间里面,并且close方法前会调研flush方法,buffer类似于queue的东西,它只需要赞一批拿走,而cache类似于字典的东西,用于数据的查询缓存的;
0:关闭缓冲区,只能在二进制模式使用,表示立即写入磁盘,性能极底;
1:只在文本模式使用,表示用行缓冲,换而言之就是见到换行就flush;
大于1:用于指定buffer的大小; encoding编码
编码仅文本模式使用,二进制模式无需编码,默认是依赖于当前操作系统,一般是utf-8,但是windows是gbk,gbk对于中文是双字节,所以windows也一直延续使用gbk;
其他参数
errors:什么样的编码错误将被捕获,None和strict表示又编码错误将抛出ValueErrir异常,ignore表示忽略;
newline:指定换行符,可以为None、空串、\r、\n、\r\n,读时,None表示\n会被替换为系统缺省行分隔符os.linesep;
生成器操作文件
可以看到,我们open打开一个文件之后,得到的就是一个迭代器对象,所以我们此时就可以直接使用生成器的方式来实现文件的逐行读取;
def readfile():
yield from open("test","r")
for line in readfile():
print(line,end="")文件描述符
closefd,即文件描述符,文件描述符,当我们打开一个文件,我们就能获得一个文件描述符,对于Centos系统而言,默认这个文件描述符为1024,也就是说,我们一个进程最多能打开1024个文件,文件描述符是一种有限的资源,我们在每次操作文件的时候,应该记得去关闭它,以免白白浪费系统资源;
在我们每次使用open方法时,其实也可以直接指定文件描述符,open方法提供了一个参数,即closefd,该方法表示,是否在使用close时,自动关闭文件描述符,True表示关闭它,Flase会在文件关闭后保持这个描述符,但是在Python3中,是不允许修改的,只能为True,但是我们可以获取其文件描述符;
所以说,我们在close的时候,其实帮我们做了两件事,第一件是flush将buffer中的数据刷到磁盘,第二件则是关闭文件描述符,下面就演示一下文件描述符超界时会有什么问题;
# 查看当前Centos系统默认能打开的文件描述符数量
[root@node01 ~]# ulimit -n
1024
# 编写程序打开1500个文件
[root@node01 ~]# cat file.py
#!/usr/bin/env python
fileobj=[]
for i in range(1500):
obj = open("file"+str(i),"w+")
fileobj.append(obj)
# 可以看到,最大只能打开1022个文件,因为还有其他python进程使用了两个
[root@node01 ~]# ./file.py
Traceback (most recent call last):
File "./file.py", line 4, in <module>
IOError: [Errno 24] Too many open files: 'file1021'上下文管理
可以看到,我们的文件一旦忘记关闭,会造成大量的系统资源浪费,因此系统对其做了基本的限制,因为人是有惰性的,我们使用open方法,是很有可能忘记close的,一旦忘记了,只要文件对象的引用对象不清零的话,那么这个对象会一直都存在,直至程序结束;
那么为了防止这种方法,Python提出了上下文管理,上下文管理是Python提出的一个非常重要的技术,在很多类上都可以调用上下文管理,它可以保证程序先做什么事,最后也一定会做什么事,并且上下文管理不会开辟新的作用域,而是直接在当前作用域生效;
上下文管理,即with语句块,对一个支持上下文管理的对象,我们就可以使用with语法,就可以来执行上下文操作,如果一旦进入with语句块就会把这个文件对象做些特殊的处理,当离开这个with语句块的时候,又会做一些处理,那也就是说wit语句块会给我们做两件事,进入时和离开时;
语法格式:with {obj} as [关键字]
with open("test", "w") as file:
print(file.closed)
print(file.closed)
# False
# TrueStringIO
StringIO是io模块中的一个类,StringIO是在内存中开辟一个文本模式的buffer,然后我们就可以像文件一样的去操作它,也就是说,我们在文件中能使用的大多数方法都可以对它使用,就当它是一个文件一样操作就行了,其实我们称这种文件为类文件对象,类是类似的意思;
其实这样的东西,在实际开发中还是很有用的,比如fastdfs的配置文件,我们利用fastdfs做文件存储时,我们必须给定一个文件对象,告知服务器地址、端口等,不能以配置的形式开体现,那么这个时候,我们使用StringIO就非常合适了;
一样,StringIO创建出来的内存文件,调用close方法时,这个buffer也就会释放,内存中的文件也就丢失,所以这一点是我们需要注意的一点,具体使用方法如下;
因为,这是一个内存对象,并非一个持久化在磁盘上的文件对象,所以我们直接对其使用flush是没什么效果的,默认情况下,指针是在尾部的,所以我们要使用传统的read方法,首先需要seek到0才能拿到内容,其实StringIO也提供了一种方法,getvalue(),该方法可以一次性获取这个内存对象里面的所有数据;
from io import StringIO
sio = StringIO("cce") # 在生成StringIO内存文件对象时,可以提供一个初始值;
sio.write("11") # 这样写入会直接覆盖原有内容,以字节为单位覆盖
print(sio.getvalue()) # 使用getvalue可以一次性获取内存文件的所有内容
sio.seek(0) # 如果我们要使用传统的read、readline等,需要首先seek到头部
print(sio.readline())
sio.close()
# 11e
# 11eBytesIO
BytesIO其实和StringIO是一样的,只不过BytesIO只接受bytes,而StringIO可以直接接受string,所以我们在使用BytesIO的时候,首先需要进行一次encode,其他的所有操作基本和StringIO是一样的;
from io import BytesIO
bio = BytesIO("cce".encode("utf8")) # 在生成BytesIO内存文件对象时,可以提供一个初始值;
bio.write("11".encode("utf8")) # 这样写入会直接覆盖原有内容,以字节为单位覆盖
print(bio.getvalue()) # 使用getvalue可以一次性获取内存文件的所有内容
bio.seek(0) # 如果我们要使用传统的read、readline等,需要首先seek到头部
print(bio.readline())
bio.close()
# 11e
# 11e内存文件对象上下文管理
不论是StringIO还是BytesIO或者还是文件IO,因为他们都是IO对象,所以他们也都支持上下文管理,对于内存文件的上下文管理,其实和文件的上下文管理是一样的;
from io import StringIO
with StringIO() as sio:
sio.write("cce")
print(sio.getvalue()) # ccefile-like对象
file-like对象,即类文件对象,我们一样可以像文件对象一样去操作它,其实标准输入标准输出也是一种类文件对象,其实他们本身就是一种IO设备,我们对它的操作实际上就可以像文件对象操作一样,就直接对他进行读写就可以了,只不过在标准输入标准输出对象是没法使用read方法去读的;
import sys
sys.stderr.write("cce")
sys.stdout.write("cce")
# ccecce 其实socket对象也是一种类文件对象,类似文件,也都是I/O对象,socket对象,这些IO对象,都会占用文件描述符,所以文件对象这个概念非常的大,也就是说不仅仅操作文件,就是文件对象,我们只要操作I/O设备,都是将它当作文件对象看待的,也包括网络编程,都和文件对象息息相关,他们都是类似文件的对象;