2、MySQL数据库开发二
ORM(Object Relational Mapping)
SqlAlchemy
Column常用参数
Column常用类型
创建映射关系(Mapping)
创建引擎(Engine)
创建表
创建会话(Session)
新增数据
数据修改
数据删除一
数据删除二
状态
状态总结
SqlAlchemy
Column常用参数
Column常用类型
创建映射关系(Mapping)
创建引擎(Engine)
创建表
创建会话(Session)
新增数据
数据修改
数据删除一
数据删除二
状态
状态总结
ORM(Object Relational Mapping)
PyMySQL在有些场景下,做一些数据库的处理是没问题的,因为它是直接使用SQL语句,只要我们掌握SQL语句编写规范即可,但是PyMySQL在实际稍微上规模一点的项目中,很少大规模的使用,因为它操作的对象就是表,直接使用人工编写的SQL语句与数据库进行交互,实际上还是非常复杂的,对SQL语句的编写要求也非常高;
所有随着技术的发展,慢慢将这种与数据库进行交互的方式,在驱动层面就加入了面向对象的元素,它将一个一个的表映射成一个一个对象,对这个对象的操作,驱动层就会转换成对应的SQL语句,这样,以后所有的操作都编变成了对象的操作,对这个对象的操作完成之后,我们再调用这个对象的一个方法,就可以直接将我们的改变操作应用到数据库;
因此,就提出了ORM(Object Relational Mapping)的概念,即对象关系映射,使用对象的方式来操作数据库,所谓对象就是我们经常写的一些class类,将这个class对象的属性名和属性值映射成数据库中的字段和值,如下;
class Student:
id = 某类型字段
name = 某类型字段
age = 某类型字段 实际上它内部是通过描述器实现的,大致就是如下的实现逻辑,PyMySQL是比较传统的方式,使用原生SQL语句来完成的,而ORM则是加入了面向对象元素,将表中的一列一列的数据,映射成为编程语言中的一个一个的对象,一个一个实体;
# 数据描述器
class Column:
def __get__(self, instance, owner):
pass
def __set__(self, instance, value):
pass
# ORM映射
class Student:
id = Column() # 描述器
name = Column() # 描述器
age = Column() # 描述器
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
# 一个对象,即一列数据
s1 = Student(id=1, name='cce', age=18)SqlAlchemy
SQLAlchemy是Python语言下著名的ORM库。通过ORM,开发者可以以面向对象的方式来操作数据库,不再需要编写复杂的SQL语句,同时它支持多种数据库类型,如PostgreSQL、MySQL、SQLite、Oracle以及Micorosoft SQL Server,但是除SQLite之外,其他的全部需要额外的驱动才可以链接到对应的数据库;
同时SQLAlchemy也可以将对象转换成对应的SQL语句,然后SQLAlchemy会链接到关系型数据库中应用或者查询,拿到结果之后SqlAlchemy又会将结果封装成一个一个的对象,由开发者尽情的使用,这就是SQLAlchemy的ORM流程,我们拿到的全是对象,既然是对象,我们就可以利用这个对象的方法进行CURD,这就是对象关系映射的基本逻辑;
Column常用参数
如下就是Column常用的参数,用来声明字段的各大功能,如索引、主键、自增等;
type_:表示该字段使用的字段类型;
index:布尔值,表示当前字段是否创建普通索引;
primary_key:布尔值,设置当前字段是否为唯一主键;
autoincrement:布尔值,设置当前字段是否自动增长;
default:设置当前字段的默认值;
nullable:指定当前字段是否允许为空,默认值为True,就是可以为空;
unique:指定当前字段是否唯一,创建唯一索引;
onupdate:在做数据更新时会调用这个参数指定的函数,在一次插入数据时不会调用,只会使用default的值,常用于的字段update_time;
name:指定ORM模型中某个属性映射到表中的字段名,如果不指定,那么会使用这个属性的属性名作为字段名;
comment:字段的注视信息;Column常用类型
如下就是Column字段类的常用属性,它们与MySQL的数据类型一一对应;
Intager:整形,映射到数据库中的int类型;
Float:浮点型,映射到数据库中的float类型,占32位字符;
Double:双精度浮点类型,映射到数据库中的double类型,占64位字符;
String:可变字符类型,映射到数据库中是varchar类型;
Boolean:布尔类型,映射到数据库中是tinyint类型;
DECLMAL:定点类型,是专门为乐解决精度丢失的问题;
Enum:枚举类型;
DateTime:存储时间,可以存储年月日时分秒毫秒等。映射到数据库中也是datetime类型;
Date:传递datetime.date();
Text:文本类型;
LONGTEXT:长文本类型;创建映射关系(Mapping)
上面说过ORM主要就是用来做对象关系映射的,那么我们想将一个对象映射成数据库中的一个表,首先我们就需要创建一个映射类,然后在这个映射类里面,创建多个类属性,这个类属性代表的就是字段,属性名就是字段名,属性值就是字段类型以及相关约束,同时这个映射类还必须继承自一个BaseModel的基类,那么继承这个BaseModel基类的映射类,都将被这个BaseModel所管理、维护;
这个BaseModel基类就是sqlalchemy.ext.declarative下的declarative_base,所有的映射类都必须继承自这个类,类似注册的意思,将映射类注册到这个基类里面,才能真正的被SqlAlchmy的Engine所管理;
那么在映射类的创建过程中,需要用到的数据类型,SqlAlchemy都提供了,比如MySQL中的VarChar对应SqlAlchemy里面的sqlalchemy.String,int对应sqlalchemy.Integer,当我们在映射类创建这个类属性时,需要指定这些类属性所属的类型以及长度;
同时,需要使用__tablename__指定映射表的表名,未提供__tablename__时,表名就会随机拼接,如下,这就是一张student映射类,它将在后期会直接映射成指定数据库的库里面的一张student表;
from sqlalchemy import Column,String,Integer
from sqlalchemy.ext.declarative import declarative_base
BaseModel=declarative_base() # 构建基类
class Student(BaseModel): # Student映射类,需要继承上面这个基类
__tablename__="student" # 指定表名
id = Column(name="id",type_=Integer,autoincrement=True,primary_key=True) # 整形,自增主键
name = Column(name="name",type_=String(64),nullable=False) # 字符串类型,对应Varchar,不可为空
age = Column(name="age",type_=String(64),nullable=False)创建引擎(Engine)
可以看到下图,我们想要让SqlAlchemy与数据库进行交互,就首先需要创建一个引擎Engine,由这个引擎负责将映射类或对象转换成不同数据库所支持的SQL语法,这里的不同数据库支持的语法称之为方言;
在创建引擎时,需要给定一个URI,这个URI就是数据库的链接信息、链接驱动等,同时,因为它并不像PyMySQL那样,直接实现了对数据库的API驱动,所以我们需要指定一个驱动去链接数据库,对于MySQL来讲支持多种驱动,如PyMySQL、MySQL-Python、MySQL Connection/Python、CyMySQL等;
Engine对象是使用SqlAlchemy的起点,根据sqlalchemy官方架构示意图,Engine包括数据库连接池(Pool)和方言(Dialect,方言指的是不同数据库SQL语句的语法差异),两者一起把对数据库的操作,以符合DBAPI规范的方式与数据库交互;
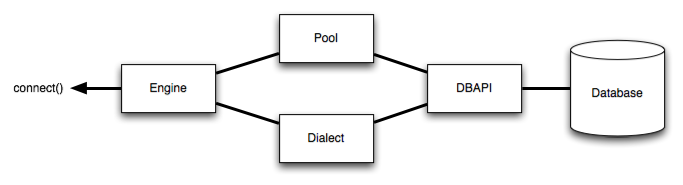
# 官网:https://docs.sqlalchemy.org/en/13/dialects/mysql.html
URL语法:dialect+driver://username:password@host:port/database[?<options>]
dialect:表示使用的方言,如果我们需要链接MySQL,那么dialect就是mysql;
driver:数据库驱动,用于连接数据库的,如pymysql;
# 示例
engine = sqlalchemy.create_engine("mysql+pymysql://cce:caichangen@47.104.197.46/cce?charset=utf8",encoding='utf-8', echo=True)
# echo:显示日志,启用它后,将看到生成的所有SQL;
# encoding:表示链接到方言的字符编码 这个Engine是惰性链接,第一个在使用create_engine()时,不会尝试链接到数据库,仅在要对数据库执行任务时才会真正的链接到数据库;
创建表
如上,就是一个使用ORM对象与表的映射示例,这就是对象关系映射,字段和属性对应上了,它用表的概念来理解,就是字段名和字段类型,现在有了关系,并且也形成了一个关系类,我们就可以将这个关系类,映射成一张MySQL数据库中的一张表,也就是说,ORM会将上面是Student映射类转变成一段CREATE TABLE的SQL语句。当我们创建好映射类之后,就可以直接将对映射类交由SqlAlchemy去将这个类映射成数据库中真真实实的表;
上面也说过,所有的映射类都会受我们的BaseModel管控,他们都继承了BaseModel基类,BaseModel基类也就能知道哪些映射类继承了自己,所以这个时候我们就可以使用BaseModel基类的metadata下面的drop_all()和create_all()方法去删除和创建BaseModel基类所管理的映射表,当然,在创建的时候,我们还需要将我们的engine给传递进去;
engine = create_engine("mysql+pymysql://cce:caichangen@47.104.197.46/cce?charset=utf8",encoding='utf-8', echo=False) # echo显示日志
BaseModel=declarative_base() # 构建基类
class Student(BaseModel):
__tablename__="student" # 指定表名
id = Column(name="id",type_=Integer,autoincrement=True,primary_key=True) # 整形,自增主键
name = Column(name="name",type_=String(64),nullable=False) # 字符串类型,对应Varchar,不可为空
age = Column(name="age",type_=String(64),nullable=False)
BaseModel.metadata.drop_all(engine) # 删除BaseModel所管理的所有映射表
BaseModel.metadata.create_all(engine) # 创建BaseModel所管理的所有映射表
创建会话(Session)
现在表已经创建好了,接下来就是创建一个一个的实例了,而实例对于数据库来讲,就表中的一行一行数据,也就是说,ORM框架会将映射类的一个一个实例,转换成表中一行一行的数据,这个实例创建也非常简单,和我们面向对象中的实例创建是一摸一样的,对映射类生成一个实例即可,生成实例的时候将每个字段的值需要传递进去,当然,如果有主键自增的字段,我们可以进行忽略;
那么实例创建出来之后,想要把这个实例变成表中的数据,我们还需要创建一个Session,这个Session就是一个数据交互通道,使用sqlalchemy.orm下面的sessionmaker来创建这么一个数据交互的会话通道,那么因为SqlAlchemy支持多种数据库,所以具体使用什么数据库的方言,什么数据库的驱动已经链接数据库的相关信息我们还得告知Session,因此,在创建Session时,我们也需要将Engine给传递给Session;
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://cce:caichangen@47.104.197.46/cce?charset=utf8",encoding='utf-8', echo=False)
# 创建Session方式一
Session=sessionmaker(bind=engine) # 创建session会话通道,并将engine以参数的方式传入,返回一个Session类
Session() # 实例化,拿到一个session链接
# 创建Session方式二
Session=sessionmaker()
Session.configure(bind=engine) # 传递Engine
Session()- 注意:
需要注意的是,利用Session类创建出来的session实例不可跨线程使用,它存在线程安全问题,需要格外注意,在多线程常见下,尽量使用局部变量或者使用threading.local来实现;
新增数据
上面,我们已经将前期工作准备完毕,字段定义好了,表也实际的创建出来了,Session也建立了,那么接下来我们就需要对这个表新增数据了,新增数据那么在ORM这一侧,其实就是对映射类创建一个实例,那么在实例化时,对必要的一些类属性进行赋值,然后将这个实例对象提交给ORM,这样,我们的数据就创建成功了;
新增数据有两个方法,session对象下面的add()或add_all()方法,一个为单条数据增加,一个批量增加,add()方法接受一个映射类的instance,而add_all()方法接受一个元素为映射类的instance的可迭代对象,它实际上内部调用的还是add(),利用循环的方式将可迭代对象里面的所有元素一一交由add()方法;
# 新增单条数据
session.add(Student(name="cce",age=26))
# 批量新增数据
session.add_all([Student(name="cfj",age=14),Student(name="csw",age=70)])
# 提交事务
session.commit()
# 回滚事务
# session.rollback()
# 关闭session通道
session.close()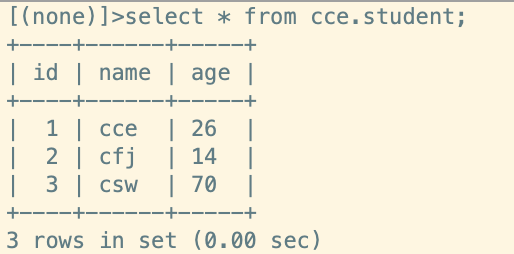
- 注意:
需要注意的是,如果我们多次提交同一个对象,只有第一次才会成功提交,SqlAlchemy会检测到,如果多次提交为同一个对象,就不会进行二次提交;
数据修改
新增是实例化得到一个映射类的实例,然后通过会话session将这个实例映射成表中的一条数据,那么对于修改,其实差不多,只不过修改数据,需要先将数据给查询出来,然后再提交,如果不先将原有的数据查询出来,那么就会变成一个Insert语句;
# 修改数据
data=session.query(Student).get(1) # 将需要修改的数据先拿到,get方法获取唯一主键,意为,在Student表中拿到主键为1的数据
data.age=25 # 修改数据
session.add(data) # 将数据修改
session.commit() # 提交事务
session.close()
# 如果不先查询,则会抛出异常
data=Student(id=1,name='cce',age=25) # 将需要修改的数据先拿到,get方法获取唯一主键,意为,在Student表中拿到主键为1的数据
session.add(data) # 将数据修改
session.commit() # 提交事务
session.close()
# 抛出异常:(1062, "Duplicate entry '1' for key 'PRIMARY'")数据删除一
对于删除来讲,其实和修改数据是一个流程,首先将需要删除的数据给查询出来,然后再将查询出来的对象进行删除;
# 删除数据
data=session.query(Student).get(1) # 将需要修改的数据先拿到
session.delete(data) # 删除数据
session.commit() # 提交事务
session.close()
# 如果不先查询,则会抛出异常
data=Student(id=2,name="cce",age=25)
session.delete(data) # 删除数据
session.commit() # 提交事务
session.close()
# 抛出异常:Instance '<Student at 0x106e9e780>' is not persisted数据删除二
上面使用get方法查询出来的数据,然后进行删除其实有点鸡肋,其实我们在数据查询出来之后,但是这种方式,要求不能是通过get方法查询出来的数据,因为通过get()返回的数据是实体本身,实体本身没有提供delete()方法,而filter方法返回的是一个惰性惰性,这个惰性惰性有这个delete()方法,可供我们直接删除这条数据;
session.query(Users).filter(Users.id==2).delete()
session.commit() # 记得提交状态
可以看到,不论是修改,还是删除,我们都必须先将数据给查询出来才能执行相关的操作,这主要是因为SqlAlchemy内部对每个实体维护了一个状态,对于SqlAlchemy来将,每一个实体(对象)都有一个状态属性,我们通过实例的实体对象的__dict__就可以看到,这个状态属性名为_sa_instance_state,其类型是sqlalchemy.orm.state.InstanceState,可以使用sqlalchemy.inspace()来获取这个对象的状态,如下;
# inspcet对象方法
key:返回一个三元祖,第一个元素为对象的唯一值,即主键,第二个元素为当前实例所属的映射类,第三个未知;
session_id:当前实例所属的session id,即使会话ID;
modified:返回当前实例是否修改过,但是还没正式应用到数据库;
# 五大状态
transient:表示当前实例,不在会话中且未保存到数据库中的实例,说白了,就是一个新的实例,还没加入到session,同时当前对象也不在数据库中;
pending:表示当前实例已经关联了session,但是还没正式提交到数据库中;
persistent:表示当前实例已经关联了session,同时也已经应用到了数据库的表中,可以是删除,可以是修改;
deleted:表示当前实例已经存在于数据库中,当前的实例是查询出来的,我们利用SqlAlchemy进行了删除,但是只是flush(开启了事务),但是还没有commit(未提交事务);
detached:表示,这个数据已成功在数据库中删除,当前的实例在数据库中已经不存在,换句话说就是当前实例与数据库分离; 为了查询当前实例属于这上述这五大状态中的哪一个状态,以及在什么流程处于什么状态,下面就自定编写了一个测试函数,将当前实例的当前的状态给找出来,如下;
from sqlalchemy import inspect
def GetState(instance):
state=inspect(instance)
attr_names=["transient","pending","persistent","deleted","detached"]
for attr_name in attr_names:
if getattr(state,attr_name):
print(attr_name) 可以看到,我们是实体是有多种变化方式的,他们之间也是变化多端的,如果我们创建了一个新的实体,但是还为关联session时,此时的状态为transient,当我们将这个数据关联session之后(session.add)此时我们的状态又会转变为pending,那么最后我们将这个数据给commit之后,这个实体的状态又会变成persistent,这就是一个新实例创建所经历的状态转换流程;
提交一个实体,需要经历两个流程,即flush、commit,flush代表开启事务,commit代表提交事务;
那么如果我们想要删除一段数据,首先会在数据库查询出来,然后SqlAlchemy会将这条数据转为一个实体,我们再对这个实体删除时,如果只是提交了事务(flush),此时的状态是deleted,那么当我们commit之后状态又会变换为detached,如下示例;
# 当对象未关联session,也未应用到数据库,此时实例的对象就为transient
student=Student(name="cce",age=12)
GetState(student) # transient
# 当对象已关联了session,但是未应用到数据库,此时实例的对象就为pending
student=Student(name="cce",age=12)
session.add(student)
GetState(student) # pending
# 当对象已关联了session,且已应用到数据库,此时实例的对象就为persistent
student=Student(name="cce",age=12)
session.add(student)
session.commit()
GetState(student) # persistent
# 当对象已关联了session,且已在数据中开启了这么一个事务,但是事务未提交,此时实例的对象就为deleted
student=session.query(Student).get(2)
session.delete(student)
session.flush()
GetState(student) # deleted
# 当对象已关联了session,且已在数据中开启了这么一个事务,并且事务已提交,此时实例的对象就为detached
student=session.query(Student).get(2)
session.delete(student)
session.commit()
GetState(student) # detached状态总结
那么这就能解释为什么上面的删除一条数据先得查询出这个数据,而不是创建一个一摸一样的实体去删除,因为删除一个实体,那么当前实体的状态必须是persistent,因为persistent代表当前实体在数据库中真实的存在,只有真实存在的数据才能够删除,这就是为什么删除一条数据,先得查询出这个数据,只有查询的出来的数据,他的状态才是persistent;
那么一个新的实体从它变成数据库中的一条数据会经过三个状态,transient -> pending -> persistent,那么删除一条数据也会经过个状态persistent -> deleted -> detached;
那么对于一个已存在于数据库的数据进行修改,它是状态一直都是persistent,因为这个实体,确实一直存在于数据库,直至commit完成删除之后,才会变成detached,表示当前实例,在数据库中不存在,即当前实例和数据库分离了;
student=session.query(Student).get(3)
GetState(student)
session.delete(student)
GetState(student)
session.commit()
GetState(student)
# persistent
# persistent
# detached