5、网络编程五
I/O模型
同步阻塞I/O(blocking I/O)
同步非阻塞I/O(non-blocking I/O)
I/O多路复用(IO multiplexing)
select/poll
epoll
信号驱动I/O(signal driven IO)
异步I/O(Async IO)
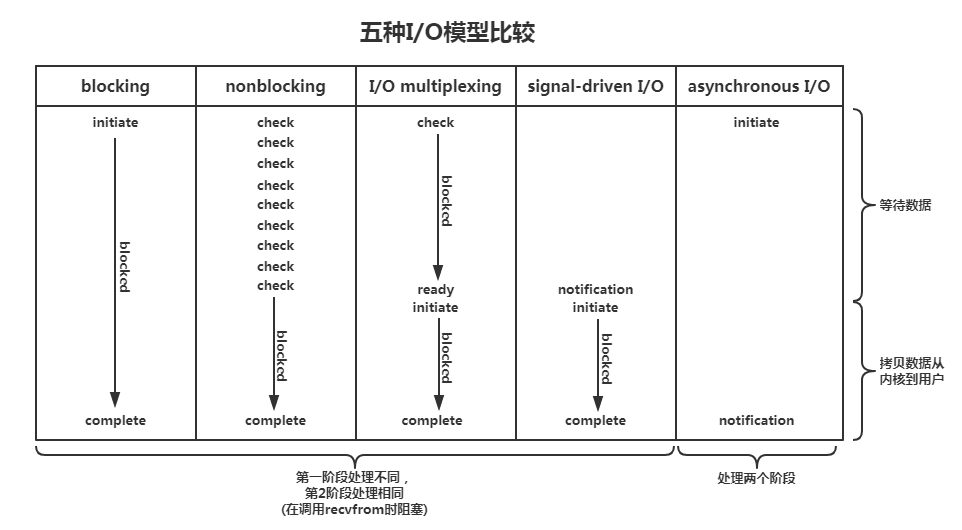
五大I/O对比
同步阻塞I/O(blocking I/O)
同步非阻塞I/O(non-blocking I/O)
I/O多路复用(IO multiplexing)
select/poll
epoll
信号驱动I/O(signal driven IO)
异步I/O(Async IO)
五大I/O对比
I/O模型
当一个正在运行的进程或线程,如果它碰到了I/O,就会阻塞,因为大多数情况下I/O都是比较慢的,它与CPU来讲速度差得太多了,在一个CPU时间片内,一定是访问不完I/O的,因为CPU的时间片是非常非常短的,在这种情况下CPU也不可能等待,所以这个时候进程或者线程就会进入阻塞状态,进入阻塞态之后CPU就解放了,可以去执行其他的任务了,那么进入阻塞态之后,在数据未准备完之前,CPU是不会调度的;
前面也说过,要向访问磁盘文件,或者访问网络,这个时候就必须借助内核提供的系统调用才能完成,那么这样I/O就可以分为两个阶段,以读取recv为例,第一阶段就是将磁盘中的文件读取到内核缓冲区,第二个阶段,将数据从内核空间缓冲区,拷贝到用户空间,如果是send也是一样的,也分为两个阶段,从用户空间到内核空间,从内核空间再到磁盘文件,或者从网络接口发送出去,那么由此,产生I/O的地方就主要有两次,第一次,内核从I/O设备上读取数据,这就是一个I/O的过程,第二次,进程从内核中复制数据;
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段;
# I/O两阶段
第一阶段:等待数据准备 (从磁盘文件读取到内核内存空间)。
第二阶段:将数据从内核拷贝到进程中 (从内核内存空间拷贝到用户空间对应进程的堆栈)
# 对于socket流而言
第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区;
第二步:把数据从内核缓冲区复制到应用进程缓冲区; 网络应用需要处理的无非就是两大类问题,网络IO,数据计算。相对于后者,网络IO的延迟,给应用带来的性能瓶颈大于后者。网络IO的模型大致分为两大类,如下;
# 同步I/O
同步I/O(synchronous IO)
阻塞IO(bloking IO)
非阻塞IO(non-blocking IO)
多路复用IO(multiplexing IO)
信号驱动式IO(signal-driven IO)
# 异步I/O
异步IO(asynchronous IO)同步阻塞I/O(blocking I/O)
同步阻塞IO模型是最常用的一个模型,也是最简单的模型。在linux中,默认情况下所有的socket都是blocking。它符合人们最常见的思考逻辑。阻塞就是进程"被"休息, CPU处理其它进程去了;
在这个IO模型中,用户空间的应用程序执行一个系统调用(recvform),这会导致应用程序阻塞,什么也做不了,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络IO;
一次I/O请求分两次I/O事务,第一次是等内核将数据准备好,第二次是在用户空间等数据准备好,从kernel space到user space的过程,这个所谓数据准备好,指的是kernel准备好,它从磁盘的驱动到磁盘上读取数据,将数据读取到内核当中,这是第一阶段,然后用户空间的这个进程从发起recvfrom函数开始一直到数据到自己用户空间的内存,整个过程进程全程阻塞,一直都在等数据准备好,进程做不了其他的任何事情,所以此类I/O为同步阻塞I/O;
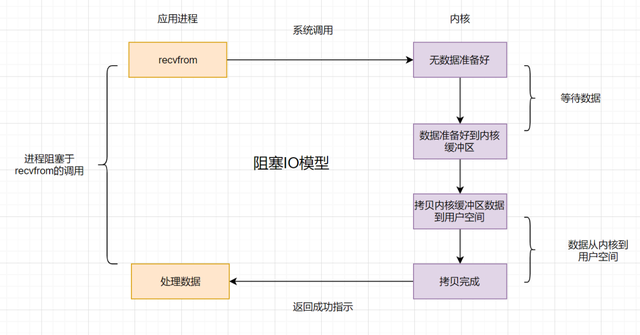
当用户进程调用了recv()/recvfrom()这个系统调用,kernel就开始了IO的第一个阶段,即准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞,也可以不阻塞)。第二个阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来;
- 重点 :
所以,根据上述的描述来看,blocking IO的特点就是在IO执行的两个阶段都被block了;
同步非阻塞I/O(non-blocking I/O)
同步非阻塞就是"每隔一会儿瞄一眼进度条"的轮询(polling)方式。在这种模型中,设备是以非阻塞的形式打开的。这意味着 IO 操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK)。在网络IO时候,非阻塞IO也会进行recvform系统调用,检查数据是否准备好,与阻塞IO不一样,"非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 '被' CPU光顾",即获得CPU时间片;
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态;
进程在等待I/O的过程中,会不断的去调用recvfrom,整个等待过程只做这recvfrom一件事,其他什么事都做不了,直到返回一个OK,才能进行下一步操作,所以这是一个同步I/O,同时它也阻塞,当数据到达内核空间之后,从内核空间将数据拷贝到用户空间这一阶段,这个时候recvfrom这个函数会阻塞,从内核空间拷贝到用户空间需要耗时多久,就需要等待多久;
但是第一阶段是不会阻塞的,因为每次向内核发起一个recvfrom都会立即得到一个结果,那么为了和blocking I/O区分,就将其称之为non-blocking I/O;
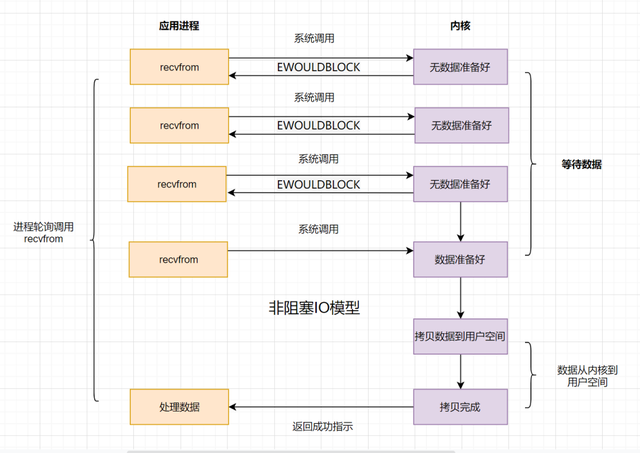
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回
- 重点 :
所以,non-blocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有;
I/O多路复用(IO multiplexing)
由于同步非阻塞方式需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间,而 “后台” 可能有多个任务在同时进行,人们就想到了循环查询多个任务的完成状态,只要有任何一个任务完成,就去处理它。如果轮询不是进程的用户态,而是有人帮忙就好了。那么这就是所谓的"IO 多路复用";
IO多路复用有两个特别的系统调用select、poll、epoll函数。select调用是内核级别的,select轮询相对非阻塞的轮询的区别在于,前者可以等待多个socket,能实现同时对多个IO端口进行监听,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,当然这个过程是阻塞的。select或poll调用之后,会阻塞进程,与blocking IO阻塞不同在于,此时的select不是等到socket数据全部到达再处理, 而是有了一部分数据就会调用用户进程来处理。如何知道有一部分数据到达了呢?监视的事情交给了内核,内核负责数据到达的处理。也可以理解为"非阻塞"吧。
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行监控,直到有数据可读或可写时(注意不是全部数据可读或可写),才真正调用I/O操作函数;
I/O多路复用也称之为Event-driven I/O,它关注的是I/O的事件,即读和写的事件,也叫做基于事件的I/O,所谓I/O多路复用其实就是有一个中间层(这个中间层就是操作系统),这个中间层能同时监控多个I/O的读写事件,我们只需要告诉中间层我们需要监控那些I/O的读或写事件,然后操作系统就会对这些I/O进行监控,如果这些I/O事件产生,就会通知进程;
I/O多路复用提高了处理I/O的能力,以前只能监控一路I/O,现在可以使用I/O多路复用来实现多路I/O的监控,那么通知进程的方式又有很多种,最早的技术SELECT技术,这个技术应用比较早,所以我们常见的操作系统都支持;
SELECT是一种轮训的方式,轮训的去查看哪个I/O已经完成,一个一个I/O交由操作系统来轮训来检测是否已经完成,效率较为低下,后来又在SELECT这个技术之上演化出来了poll的通知方式,poll是I/O多路复用中比较常见的第二项技术,poll对SELECT进行了一定的升级,但是升级也是有限的,它依然没有解决SELECT中效率低下的问题,所以说,从本质上,他两实际上是差不多的,那么从Linux内核2.5开始,就引入了epoll的这种方案,它是poll的一种升级,这个增强它摆脱了很多的限制,比如文件描述符的限制,对性能也有很好的提高;
epoll主要是通过回调的机制,来提高它的性能,其他平台,也陆陆续续有了自己技术,比如伯克利Unix上的BSD,比如Mac平台的kqueue,他们和epoll很相似Windows的iocp;
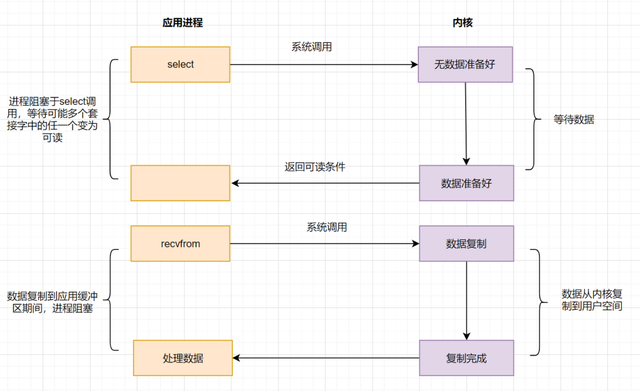
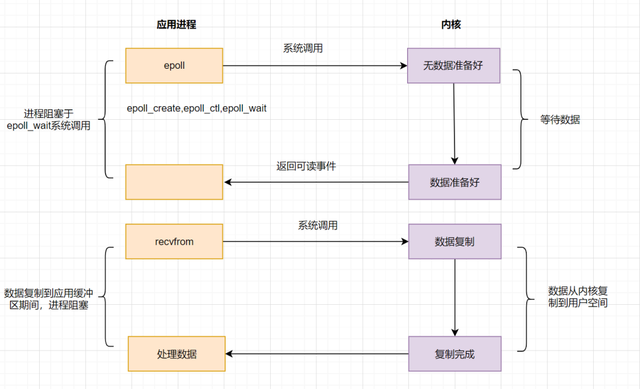
IO multiplexing就是人们常说的select、poll、epoll,有些地方也称这种IO方式为event driven IO。select/poll/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程;
当用户进程调用了select系统调用函数,那么整个进程会被block,而同时,kernel会"监视"所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程;
多路复用的特点是通过一种机制一个进程能同时等待IO文件描述符,内核监视这些文件描述符(套接字描述符),其中的任意一个进入读就绪状态,select, poll,epoll函数就可以返回。对于监视的方式,又可以分为 select, poll, epoll三种方式,其中select和poll实际上是一个东西,只不过做了最简单的升级;
上面的图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection,所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大,select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接;
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。所以IO多路复用是阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上;
select/poll
那么对于I/O多路复用的select来讲,操作系统将磁盘数据复制到内核的内存空间之后,告知进程某一路I/O处理完成了,但是具体是哪一路I/O完成操作系统并没有告知,需要进程自己去遍历所有的I/O,效率低下,并且它还有一个文件描述符的限制,最大1024,所以SELECT现在使用得比较少,那么poll就是最其文件描述符数量改进了下,内部原理和select是一样的,一样存在性能问题;
epoll
也正是因为select和poll模型存在的性能问题,所以就有了epoll模型,poll的升级版,对于epoll来讲,我们可以认为它增加了一种通知机制,或者说,回调机制,当数据准备好了之后,内核会直接告知用户空间的进程,哪一路I/O好了,这就是典型的回调机制,效率更高,并且它还突破了文件描述符的限制,内部的I/O句柄使用哈希表存储,性能更加强悍;
信号驱动I/O(signal driven IO)
epoll明显优化了IO的执行效率,但在进程调用epoll_wait()时,仍然可能被阻塞。能不能酱紫:不用我老是去问你数据是否准备就绪,等我发出请求后,你数据准备好了通知我就行了,这就诞生了信号驱动IO模型;
信号驱动IO不再用主动询问的方式去确认数据是否就绪,而是向内核发送一个信号(调用sigaction的时候建立一个SIGIO的信号),然后应用用户进程可以去做别的事,不用阻塞。当内核数据准备好后,再通过SIGIO信号通知应用进程,数据准备好后的可读状态。应用用户进程收到信号之后,立即调用recvfrom,去读取数据;
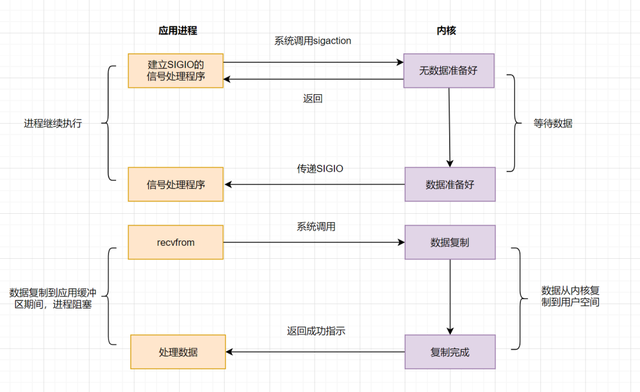
信号驱动IO模型,在应用进程发出信号后,是立即返回的,不会阻塞进程。它已经有异步操作的感觉了。但是你细看上面的流程图,发现数据复制到应用缓冲的时候,应用进程还是阻塞的。回过头来看下,不管是BIO,还是NIO,还是信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的;
异步I/O(Async IO)
上述全部都是BIO,即同步I/O,在数据从内核复制到应用缓冲的时候,都是阻塞的,因此都不算是真正的异步。由此诞生了AIO,它实现了IO全流程的非阻塞,就是应用进程发出系统调用后,是立即返回的,但是立即返回的不是处理结果,而是表示提交成功类似的意思。等内核数据准备好,将数据拷贝到用户进程缓冲区,发送信号通知用户进程IO操作执行完毕;

进程发起一个异步I/O的系统调用,就会立即返回一个中间结果,然后,第一阶段,从磁盘读取到内核缓冲区,这个过程包括第二阶段,从内核缓冲区到用户空间缓冲区,都是非阻塞的,也就是说,进程在这两个阶段,不会被阻塞,可以继续做其他的事情,这就是异步I/O,等数据好了,内核会直接调用回调函数,所以说,它的效率是极高的;
五大I/O对比
可以看到下图,前四个都是同步I/O,因为核心操作recv/recvfrom调用时,进程会阻塞直到最终拿到结果为止,而异步I/O进程全程不阻塞,性能极高;