1、Iptables应用简介
网络简介
我们常用的httpd/dns/samba等他们都是基于套接字的模式通信的,所谓套接字通信的这种模式就是一台主机之上有一个所谓的工作在用户空间的进程,它为了与别的主机进行通信,基于所谓的C/S架构通信时, 基本的工作模型通常是,它向内核注册监听一个套接字。而对于我们的网络来讲大体上可以分为通信子网和资源子网,资源子网工作在用户空间,通信子网则是在内核中实现。而通信子网当中,基于TCP/IP协议模型。
就比如我们的链路层:主要实现本地通信或者说局域网通信,如果要完成互联网寻址则我们就需要网络层,它的主要通信方式是通过封装IP首部,里面最为核心的就是IP源地址和IP目标地址,再向上一层是传输层,这一层当中最典型的协议就是我们常说的TCP协议等。我们接触得最多的是进程有通信需求,但是一台主机之上不止有一个进程,那此时我们就需要通过端口来区别进程,所以端口号主要是用来区分进程的。
所以这就是每一台主机上的应用程序想要通信都要指定服务端的IP+端口或者客户端IP+端口的原因,IP仅用于标识主机,端口则标识这个IP地址的主机之上指定的进程,所以说传输层一层的主要目的是提供源端口、目标端口,所以计算机之间的通信,多数都是进程和进程之间的通信。
两个主机至上的进程,想要通信,那么至少有一方主动发起,因此这个时候,被通信的一方,应该至少让发起的一方能够找到自己才行,也就意味着被通信的一方得有一个能够接收别人发出请求的这么一个端点。所以任何一个服务端都得监听在某一个地址和端口之上,监听的意思就的等待请求者来请求,无论是否请求,都在等待。
只有这样才能使得当客户端请求时才能真正接收客户端请求,那对方怎么知道访问哪一个端口呢,这就和约定,互联网有一个专门的组织,就是IANA,他们专门用来实现,数字和名称地址分配的,因此他们就定义了httpd就使用80端口监听,只有这样子大家才不至于说不知道去访问某一个主机之上的端口。
TCP/IP模型

Iptables
整个互联网的通信,大多数都是进程与进程之间的通信,而且每一端都拿着一个IP+端口与另外一端的IP+端口建立通讯,一旦某个通信建立起来了,我们就称之为一个已建立的套接字,他们之间就可以交互信息了, 等信息交换完了还需要拆除连接,TCP和UDP之间不同的是TCP在双方进行数据交互的时候,首先会建立一个虚链路,一旦使用完了也需要将这个链路的拆除。
但是两台主机之上进程有很多,每一个进程和另外一台主机都有可能建立通讯,那也就意味着当前主机上有诸多进程都在通信当中,他们每个进程与每个通信的主机,如果是TCP连接,那么诸多通信都是需要建立一个虚链路的,以确保报文可靠送达到目的端的,那也就意味着我们一台主机之上可能要打开N个端口,每个端口用于实现一种通信,但是在C/S架构中,必定是一方请求一方响应的过程,请求的一方对于一个互联网放置本来是要提供给大众访问的服务器来讲,它的的确确应该是开放式的,但是作为一个客户端来讲,一般而言不会允许别人随意来访问自己的,所以请求的方向至关重要,因此每一个报文都应该具有源IP源端口,目标IP目标端口,所以这里提到的源目标至关重要,因为它决定了我们的方向是从何处到何处的。
当今的互联网上的通信,绝大多数都是套接字的通信,那么对于服务器端来讲,为了能够让别人访问,我们就必须要监听在某个端口之上让别人直接来请求,那么其他没有监听的端口就没有必要开放,就比如我们的服务器上可能构建了LAMP,那么这就说明我们的MySQL只需要让php来访问即可,在这种情况下就没必要开放给远程的客户端来访问,所以我们又要监听在3306端口上,又不能让那些未经授权的客户端来访问,我们监听3306仅仅是为了php代码来访问。
因此我们监听了端口未必就一定得开放给互联网访问,但是端口又要监听,监听的目的仅仅的为了提供本地服务器使用,但是这个端口一监听不打紧,那别人就有可能乘虚而入,向这种服务我们没有提供给互联网的使用,那么互联网上一些恶意的使用者利用这个漏洞,获取到非授权访问,对我们来讲就有非常大的安全隐患,那么这个时候我们就需要借助防火墙来放火,堵住所有端口不让任何人访问,只开放给指定的客户端。从正常逻辑来讲,我们内核中的所有的协议,是公开给所有外部主机访问的,所以因为这么一个机制我们就需要有手段来阻止非授权访问。因此我们就在主机上加了一道墙,让外部互联网未授权客户端无法访问到我们的服务,所以它就叫防火墙,实际上就是一个隔离带;
那么有了防火墙,任何想要到达我们主机的报文,首先需要经过防火墙的审核才行,另外我们在墙上还可以指定一些规则,比如我们的http的80端口,我们可以直接开放给互联网用户,其他端口都不允许访问,这就是防火墙的工作逻辑;
所以我们提到的大多数防火墙,我们都可以称之为,包过滤型防火墙,也就意味着这个防火墙能够对每一个数据请求报文,按照我们设定好的规则进程过滤,就比如说如果访问的是本机的80端口我们就允许你们访问,其他端口都不允许,允许不允许这就是过滤;
主机防火墙
一个请求报文可以有源端口目标端口源地址目标地址以及报文实体等等,我们防火墙都需要对这些东西做检查,当一个报文达到主机之后,它去识别一个报文的源端口目标端口等是在内核中实现的,因此防火墙应该工作在内核中,所以我们需要构建出一个防火墙来,你得需要在内核的TCP/IP协议栈上去实现,那是因为,你的报文的识别过程都是在内核级进行的,换句话说就是必须在内核的请求协议栈,正在把请求报文送给本地内部进程之前给它施加一道屏障,这到屏障就是我们所谓的主机级防火墙。

网络防火墙
当一个外部的竞争对手,请求到达时,它有可能会试图局域网内的每一台主机,而不是单一某一台主机,那么在众多主机当中总可能有一台主机的设定不是那么的妥当,那这个时候恶意者就可能基于这台主机作为跳板,直接打入内部其他主机,所以像这种情形当中,我们也不应该让这种报文能够直接进入到我们的网络当中,那我们就需要在我们的整个局域网的边缘处,还需要施加一套防火墙,也就意味着任何想要进入本地网络的,都需要经过我们的前端网关主机,那此时,我们就可以在网关主机上去部署一个应用,这个应用如果说能够检测所有的报文,如果一旦检测到了恶意请求,我们就把它挡在本地网络之外,不让它进入我们的本地网络,那这样就更好了。
这台主机主要的不是防范别人对自己的访问,而是对自己背后所构建的局域网进行访问,假设这一台网关主机,是一台Linux主机,那么都知道我们的Linux内核有一个内核参数,打开网卡的核心转发,打开核心转发之后,那么这个主机就是一个网关了,它可以有两块网卡,一块网卡连接到我们的公网,一块网卡连接到我们的内网,从一个网络来的请求到达它,它能够给它帮忙路由到另外一个网络中去。
一个报文来了,首先到达的是我们的网卡,而网卡报文接收处理是由内核进行的,达到网卡之后到达网卡驱动,而后到达内核所处理的缓冲区当中,接下来内核就把它交给我们的TCP/IP协议栈来分析这个报文是来访问谁,如果目标IP是自己那么就开始找本地端口,交给进程,如果目标IP不是自己主机, 自己主机上没有任何一个IP是这个报文的目标IP,那么这个时候只要我们打开的核心转发功能,那么内核接下来就需要帮我们转发出去,需要检测下,要达到目标IP地址,经过我们的哪一个网卡接口能出去,不会动源IP也不会动目标IP,而只是会帮忙检测下,要到达目标IP通过本地的两块网卡的哪一个网卡能发出去,而且能达到,那么检测就是检查本地的路由表,检测路由表有达到目标IP的路由条目,那么就根据设定交给下一跳主机,如果说没有任何主机能够到达目标IP,那么就会走默认网关,如果目标IP就是本地网卡2的内网的一个地址,那么下一跳,就直接送到内网主机来了,所以可以看到,这个报文是没有达到网关主机的用户空间的,直接在内核空间中就转发出去了;
既然报文达到了我们的内核,那么我们就可以让防火墙发挥作用了,所以我们如果在内核内部再设一道屏障,明确规定,从哪个IP到我们本机哪个IP访问什么服务都不允许,这么一设置,那我们就完成的内部网络的安全限制,像这种我们就称之为网络防火墙,因为它是帮一个局域网来完成防火功能。

解析
当报文进来达到本地主机内核空间之后,到达本地网卡之后,本地主机拆掉链路层的包头之后,一分析,只有两种可能,要么到本机内部来目标IP是自己,要么通过我们另外一个网卡接口重新发出去,就这两种可能性,因此我们就可以对这两种不同的报文分别设定一个卡子,也就意味着它就能够完成不同意义的放火功能了。
图中的INPUT,就是目标IP是本机,进入本机主机的报文,这叫主机防火墙;
图中的OUTPUT是进入到本机之后,本地主机得到响应,然后发送响应报文的卡子;
图中的OUTPUT,就是目标IP不是本地主机,需要从另外一个网卡接口转发出去的,这叫网络防火墙;
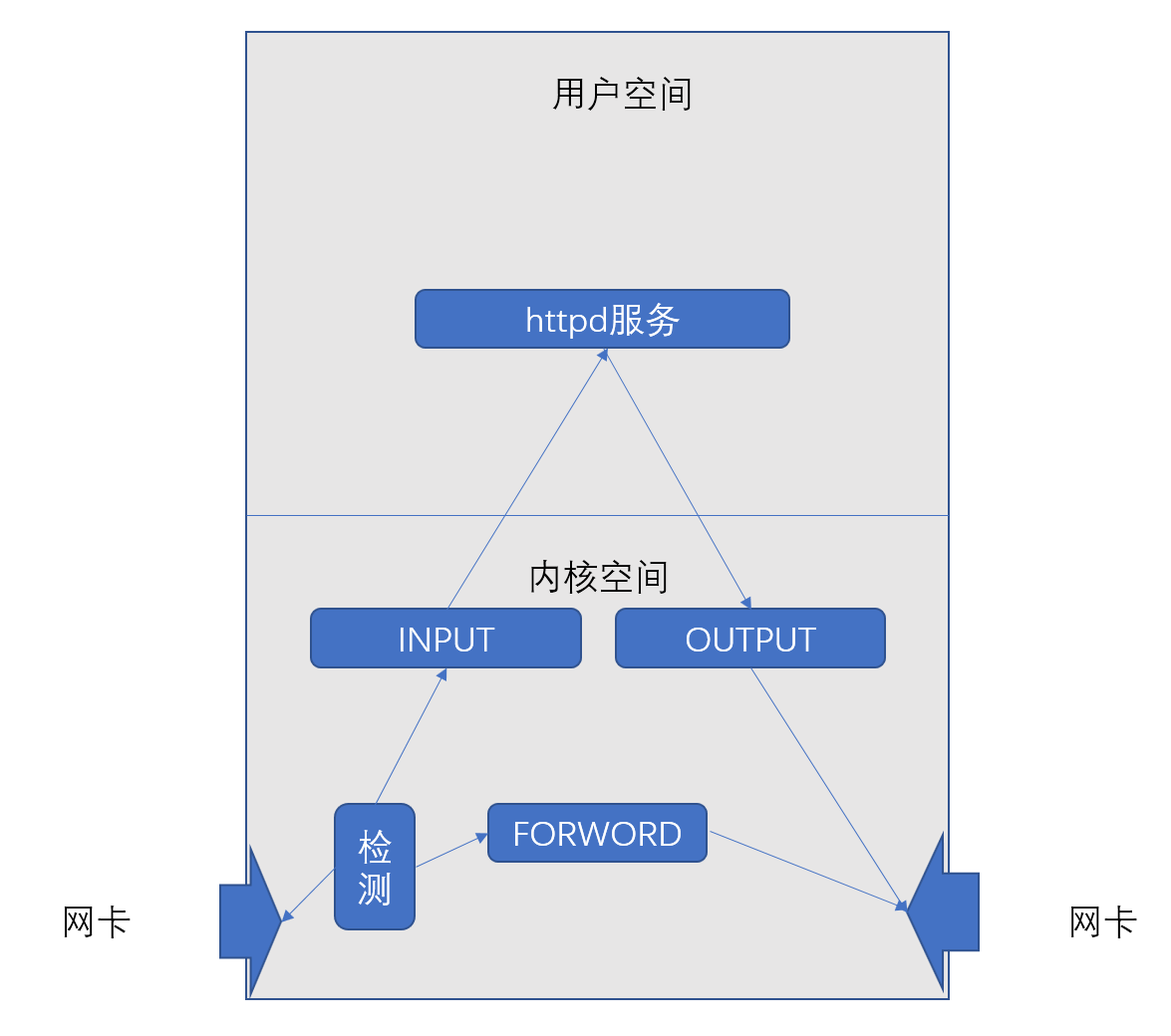
Linux防火墙
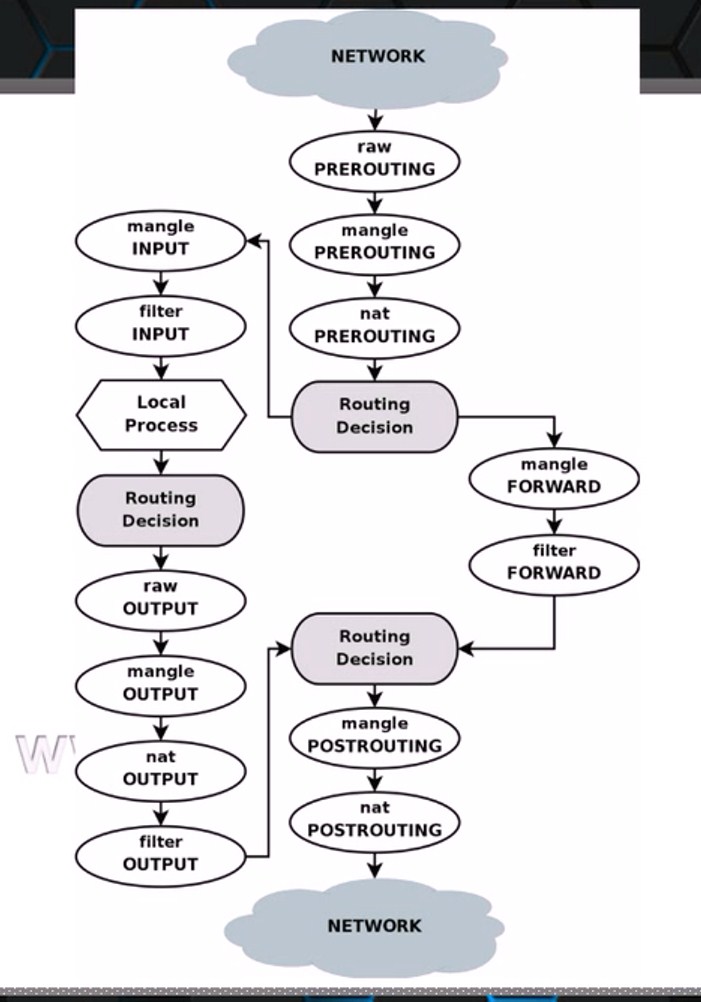
在任何时候,无论任何时候,当报文达到本地主机之后,第一步有一个路由的过程,不论从哪个网卡进来的报文,目标地址有可能是本机,有可能是其他主机,因此,我们就需要决定一下,到底是到本机还是经由本机转发,比如我们转发到另外一个网卡出去,这是两种不同的情形,而这个路由之后就有两种步骤,第一个步骤就是到达我们本机内部,像这种报文就是直接发给我们的INPUT做检测是否通过,只管到达我们本机内部的报文。如果是检查完成之后是经过本机转发给另外一个主机,那么像这种报文就是直接发给我们的FORWORD做检测是否通过,那这是路由检测之后的操作,当然那我们还可以在路由之前做一些操作,做一些预处理工作,因此在路由之前还有一个钩子这个钩子PREROUTING;
那么当报文达到主机之后,我们应用程序收到了报文并且发送了响应报文,那么这个响应报文就是一个从本机流出的一个报文,那么流出之前我们还有一个钩子,这个钩子叫做OUTPUT,那么通过了OUTPUT规则链之后要响应,那么此时假设我们的主机有四块网卡,那么这个报文到底走哪一块网卡能达到目的主机呢,这个时候也需要路由,那么此时在OUTPUT之后就还有一个路由,去检测到底报文的信息,那么路由之后报文就要离开我们的主机了,所以我们在报文离开主机之前还有一个钩子可以做一些机制处理,这个机制叫做POSTROUTING;
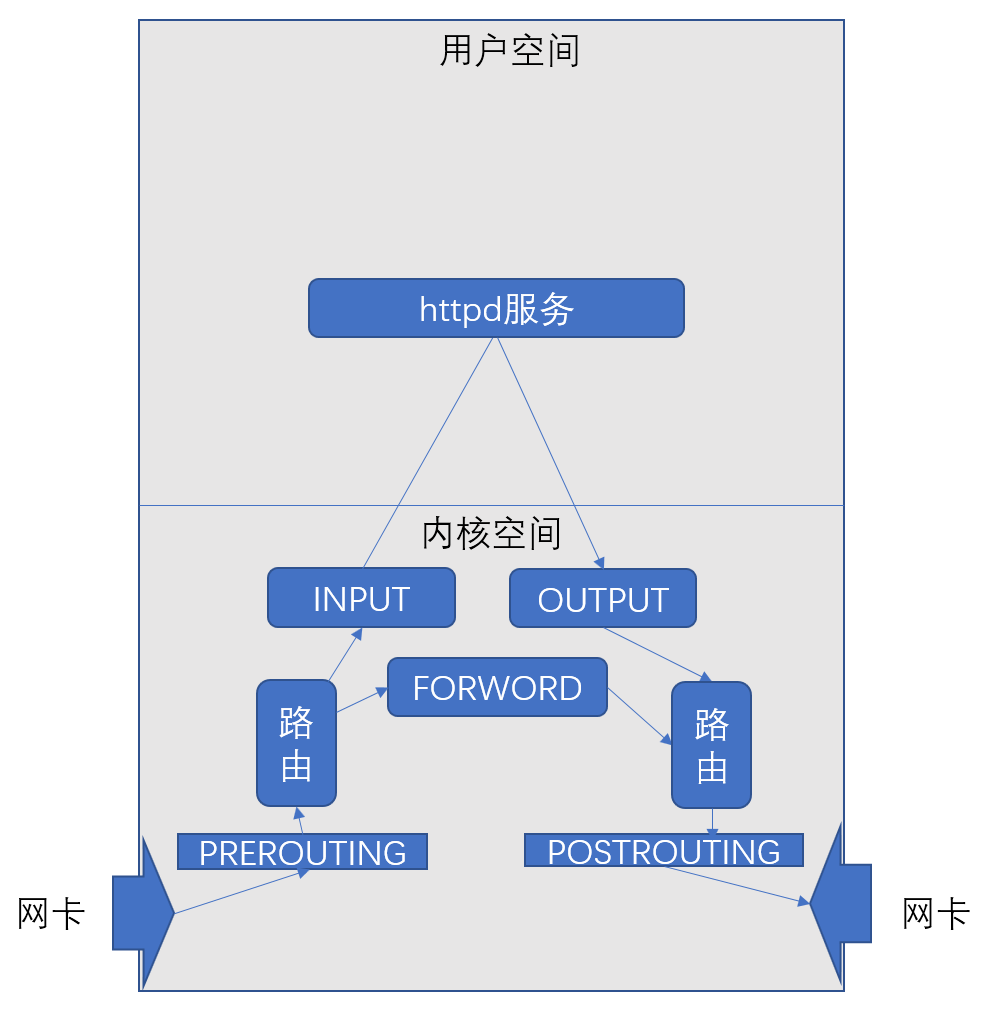
规则
以上五大钩子,事实上是在内核中安置的一个框架,任何一个报文只要到达内核,都要经过这五大钩子的检测,对于防火墙来讲,我们在这个钩子上放置的就是一些检查规则,和处理办法,比如如果源IP是什么,源端口是什么满足什么,怎么处理等,都是需要通过规则来进行决策的。
因为这五大钩子都在内核中的,我们的用户又不能直接与内核交互,之能通过系统调用进行,那么就有了一个运行在用户空间的一个工具,这个工具就可以通过用户编写的一些规则然后生成规则,发送给内核来应用到这几个钩子上,所以这个用户空间工具就叫做iptables、这个内核空间的叫做netfilter;
Iptables
链(钩子)
PREROUTING:请求报文路由之前;
INPUT:请求报文达到用户空间之前;
FORWORD:请求报文转发之前;
OUTPUT:响应报文出去第一个钩子;
POSTROUTING:响应报文离开主机之前;
功能
filter:报文过滤;
nat:网络地址转换,用户修改源IP或目标IP,也可用修改端口;
mangle:拆解报文,做出修改,并重新封装,mangle主要用于修改除了地址之外的其他信息的,比如ttl值、上层协议、协议版本等;
raw:关闭nat表上启用的连接追踪机制,nat功能要启用起来,为了保证转发出去的请求报文服务器收到请求发送响应报文到达iptables主机那么我们就必须有一个追踪表,无论是目标地址转换还是源地址转换都需要打开追踪机制,主要用于记录或识别功能的;
功能 对于 链(规则优先级由高到低)
raw:PREROUTING、OUTPUT;
mangle:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING;
nat:PREROUTING、INPUT、OUTPUT、POSTROUTING;
filter:INPUT、FORWORD、OUTPUT;
报文流向
流入本机:PREROUTING、INPUT;
由本机流出:OUTPUT、POSTROUTING;
转发:PREROUTING、FORWORD、POSTROUTING;