3、RabbitMQ开发接口
Python使用RabbitMQ
创建访问用户
简单的实现队列
消息确认机制
消息持久化
队列持久化
公平分发
发布订阅 (publish/subscribe)
fanout广播模式
示例如下
direct组播模式
示例如下
topic类型
示例如下
创建访问用户
简单的实现队列
消息确认机制
消息持久化
队列持久化
公平分发
发布订阅 (publish/subscribe)
fanout广播模式
示例如下
direct组播模式
示例如下
topic类型
示例如下
Python使用RabbitMQ
接下来就使用Python来简单的对以下几种队列类型进行一部分的操作,主要是为了更加容易去理解它,站在开发的角度去看待RabbitMQ;
创建访问用户
# 创建一个cce用户
[root@node01 ~]# rabbitmqctl add_user cce caichangen
# 创建一个虚拟主机
[root@node01 ~]# rabbitmqctl add_vhost simpleTest
# 赋予用户一个角色
[root@node01 ~]# rabbitmqctl set_user_tags cce administrator
# 对该用户进行授权
[root@node01 ~]# rabbitmqctl set_permissions -p simpleTest cce ".*" ".*" ".*"简单的实现队列
# 生产者
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, credentials=auth, virtual_host='simpleTest'))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明需要开启的queue名称
channel.queue_declare(queue='simpleTest')
# RabbitMQ消息永远不能直接发送到队列,它总是需要通过交换
# 将消息发送到队列
for num in range(1, 5):
channel.basic_publish(exchange='',routing_key='hello',
body='Hello World!' + str(num))
print("已经向RabbitMQ中提交数据'")
connection.close()# 消费者
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1',port=5672,virtual_host='simpleTest',credentials=auth))
channel = connection.channel()
# 声明需要接收消息的通道
channel.queue_declare(queue='hello')
# 订阅的回调函数这个订阅回调函数是由pika库来调用的,ch就是上面的channel实例
def callback(ch, method, properties, body):
print("从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费者参数,回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理。实际就是一个select监听
channel.start_consuming()消息确认机制
如上,我们已经实现了基础的队列功能,那么就带来了另一个问题,当我们的消费者接受到一个消息的时候,这个消息比较耗时,如果在这个消费的过程中服务器内存溢出等其他情况导致消息没有完成消费,那么此时为了解决这个消息的遗漏问题,RabbitMQ提供了一个消息确认机制,当消息交给消费者之后,如果消费者消费完成,需要给RabbitMQ回复一个消息确认信息,如果这个信息没有被确认消费成功那么当没有消费成功的客户端和RabbitMQ的连接断开之后会把这个消费重新分配给其他的客户端进行消费;
那么解决上面客户端的问题,那么往深了想我们的RabbitMQ服务端也可能会出现这个问题,当RabbitMQ挂掉之后,那么这个消息也不应该丢失,所以RabbitMQ的持久化机制给我们带来了很好的体验;
消息持久化
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。 这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑…千面是因为我们在消费者端标记了ACK=True关闭了它们,如果你没有增加ACK=True或者没有回执就会出现这个问题;
关键参数:
durable:Bool值,代表queue队列通道是否持久化,想要消息持久化,那么队列必须持久化;
# 生产者需要在发送消息的时候标注属性为持久化
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1',port=5672,virtual_host='simpleTest',credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明需要开启的queue名称
channel.queue_declare(queue='task_queue')
# RabbitMQ消息永远不能直接发送到队列,它总是需要通过交换
# 将消息发送到队列
channel.basic_publish(exchange='', # 使用默认交换器
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties( # 消息持久化
delivery_mode=2, # 设为2表示标记消息为持久化
))
print("已经向RabbitMQ中提交数据'")
connection.close()# 消费者需要发送消息回执
import pika
import time
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1',port=5672,virtual_host='simpleTest',credentials=auth))
channel = connection.channel()
# 声明需要接收消息的通道
channel.queue_declare(queue='hello')
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
time.sleep(5)
ch.basic_ack(delivery_tag=method.delivery_tag) # 这段代码表示确认这个消息消费完成,返回这个消息的唯一标识符,发送消息确认,确认交易标识符
print('数据消费完成')
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume('hello', callback, auto_ack=False) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()RabbitMQ查看没有被ACK的消息
# Linux
rabbitmqctl list_queues name messages_ready messages_unacknowledged
# Windows
rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
队列持久化
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务。由于这里仅为RabbitMQ的简单介绍,所以这里将不讲解RabbitMQ相关的事务。 这里我们需要修改下生产者和消费者设置RabbitMQ消息的持久化**[生产者/消费者]都需要配置;
channel.queue_declare(queue='task_queue', durable=True) # 队列持久化
关键参数:
durable:Bool值,代表queue队列通道是否持久化,想要消息持久化,那么队列必须持久化;
delivery_mode:标记RabbitMQ服务端消息持久化,值为2的时候为持久化其他任何值都是瞬态的;
# 生产者消息持久化
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1',port=5672,virtual_host='simpleTest',credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明需要开启的queue名称
channel.queue_declare(queue='hello',durable=True)
# RabbitMQ消息永远不能直接发送到队列,它总是需要通过交换
# 将消息发送到队列
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print("已经向RabbitMQ中提交数据'")
connection.close()公平分发
默认情况下RabitMQ会把队列里面的消息立即发送到消费者,无论该消费者有多少消息没有应答,也就是说即使发现消费者来不及处理,新的消费者加入进来也没有办法处理已经堆积的消息,因为那些消息已经被发送给老消费者了。
prefetchCount:会告诉RabbitMQ不要同时给一个消费者推送多于N个消息,即一旦有N个消息还没有ack,则该consumer将block掉,直到有消息ack。 这样做的好处是,如果系统处于高峰期,消费者来不及处理,消息会堆积在队列中,新启动的消费者可以马上从队列中取到消息开始工作。
在消费者中增加channel.basic_qos(prefetch_count=1)实现公平分发

工作过程如下:
1、消费者1接收到消息后处理完毕发送了ack并接收新的消息并处理;
2、消费者2接收到消息后处理完毕发送了ack并接收新的消息并处理;
3、消费者3接收到消息后一直处于消息中并没有发送ack不在接收消息一直等到消费者3处理完毕后发送ACK后再接收新消息;
发布订阅 (publish/subscribe)
在前面我们学了work Queue它主要是把每个任务分给一个worker[工作者]接下来我们要玩些不同的,把消息发多个消费者(不同的队列中). 这个就要用到Exchange了,这个模式称之为"发布订阅";
订阅的方式他和一对一不一样,消费者没有连接的时候消息会进行持久化,但是发布订阅当消费者没有连接的时候,那么这个消息就丢失了,并且发布订阅是每个收听者一个队列,如果和别人共享一个队列,那么就可能出现,A把消息收走了,B却没收到;
因为在发布订阅的模式下面每个队列都需要接收到消息生产者不可能每个队列每个队列的发,所以这个时候就需要用到Exchange了,它作为转发器负责将广播发送到每个指定的队列,Exchange还需要维护一个订阅列表,所以它才知道需要将广播发送给哪个收听者;
关键参数:
queue_bind:当我们创建了Exchanges和(QUEUE)队列后,我们需要告诉Exchange发送到们的Queue队列中,所需要需要把Exchange和队列(Queue)进行绑定,
Exchanges可用类型有四种:
direct:组播,通过routingkey和exchange决定的哪一组queue可以接收消息;
fanout:广播,所有bind到此exchage的queue都会接收到消息;
topic:所有符合routingkey(可以是一个表达式)的rroutingkey索bind的queue可以接收消息;
表达式符号:
#:代表一个或多个字符;
*:匹配前面或者后面任何字符;
#.a:会匹配a.a,aa.a,aaa.a等;
a.#:会匹配a.a,a.aa,a.aaa等;
*.a:会匹配a.a,aa.a,aaa.a等;
a.*:会匹配a.aa,a.aaa,a.aaa等;
#:匹配所有;
注意:使用routingkey为#,exchange Type为topic的时候相当于fanout;
headers:通过headers消息头来决定把消息发给哪些queue;
fanout广播模式
模式特点:
可以理解他是一个广播模式;
不需要routing key它的消息发送时通过Exchange binding进行路由的~~在这个模式下routing key失去作用;
这种模式需要提前将Exchange与Queue进行绑定,一个Exchange可以绑定多个Queue,一个Queue可以同多个Exchange进行绑定;
如果接收到消息的Exchange没有与任何Queue绑定,则消息会被抛弃;
示例如下
# 广播模式生产者
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1',port=5672,virtual_host='simpleTest',credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='logs', exchange_type='fanout')
channel.basic_publish(exchange='logs', routing_key='', body='caidaye')
print("已经向RabbitMQ转发器发送广播")
connection.close()# 广播模式消费者
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
result = channel.queue_declare(queue='',
exclusive=True) # 声明队列,这个队列用来接收广播,因为说了为了保证消息可达,需要队列唯一,一人一队列,使用exclusive=True表示不让其他人加入到这个队列,不指定queue名称rabbitmq会自动生成一个,当这个消费者断开之后会自动删掉,重新生成一个queue
queue_name = result.method.queue # 获得rabbitmq自动生成的队列名
channel.queue_bind(exchange='logs', queue=queue_name)
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue_name, callback, auto_ack=True) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()direct组播模式
任何发送到Direct Exchange的消息都会被转发到routing_key中指定的Queue
1、一般情况可以使用rabbitMQ自带的Exchange:" "(该Exchange的名字为空字符串),也可以自定义Exchange;
2、这种模式下不需要将Exchange进行任何绑定(bind)操作。当然也可以进行绑定。可以将不同的routing_key与不同的queue进行绑定,不同的queue与不同exchange进行绑定;
3、消息传递时需要一个“routing_key”;
4、如果消息中不存在routing_key中绑定的队列名,则该消息会被抛弃;
如果一个exchange 声明为direct,并且bind中指定了routing_key,那么发送消息时需要同时指明该exchange和routing_key;
简而言之就是:生产者生成消息发送给Exchange, Exchange根据Exchange类型和basic_publish中的routing_key进行消息发送消费者:订阅Exchange并根据Exchange类型和binding key(bindings 中的routing key),如果生产者和订阅者的routing_key相同,Exchange就会路由到那个队列。
老规矩还是通过实例来说:
在上面的文档中我们创建了一个简单的日志系统,我们把消息发给所有的订阅者 在下面的内容中将把特定的消息发给特定的订阅者,举个例子来说,把error级别的报警写如文件,并把所有的报警打印到屏幕中,进行了路由的规则类似下面的架构;

这里也要注意一个routing key 是可以绑定多个队列的
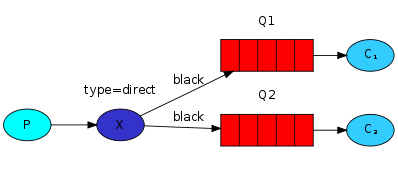
在上面我们已经创建过bindings了类似下面
channel.queue_bind(exchange=exchange_name,
queue=queue_name)
消费者端:Bindings可以增加routing_key 这里不要和basic_publish中的参数弄混了,我们给它称之为**binding key**
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key='black')
binding key的含义依赖于Exchange类型,fanout exchanges类型只是忽略了它
示例如下
# 组播模式生产者
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
channel.basic_publish(exchange='direct_logs', routing_key='info', body='info')
print("已经向RabbitMQ转发器发送info组播")
channel.basic_publish(exchange='direct_logs', routing_key='error', body='error')
print("已经向RabbitMQ转发器发送error组播")
connection.close()# 组播模式客户端1
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和direct的类型
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result = channel.queue_declare(queue='',exclusive=True) #声明队列,这个队列用来接收广播,因为说了为了保证消息可达,需要队列唯一,一人一队列,使用exclusive=True表示不让其他人加入到这个队列,不指定queue名称rabbitmq会自动生成一个,当这个消费者断开之后会自动删掉,重新生成一个queue
queue_name = result.method.queue # 获得rabbitmq自动生成的队列名
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key='info')
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue_name, callback, auto_ack=True) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()
# 从RabbitMQ获取的数据是:info# 组播模式客户端2
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result = channel.queue_declare(queue='',exclusive=True) #声明队列,这个队列用来接收广播,因为说了为了保证消息可达,需要队列唯一,一人一队列,使用exclusive=True表示不让其他人加入到这个队列,不指定queue名称rabbitmq会自动生成一个,当这个消费者断开之后会自动删掉,重新生成一个queue
queue_name = result.method.queue # 获得rabbitmq自动生成的队列名
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key='error')
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue_name, callback, auto_ack=True) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()
# 从RabbitMQ获取的数据是:errortopic类型
前面讲到direct类型的Exchange路由规则是完全匹配binding key与routingkey,但这种严格的匹配方式在很多情况下不能满足实际业务需求;
topic类型的Exchange在匹配规则上进行了扩展,它与direct类型的Exchage相似,也是将消息路由到binding key与routing key相匹配的Queue中,但这里的匹配规则有些不同;
它约定:
routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”;
binding key与routing key一样也是句点号“. ”分隔的字符串,以.分割这点很重要----------------------------------;
binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个);
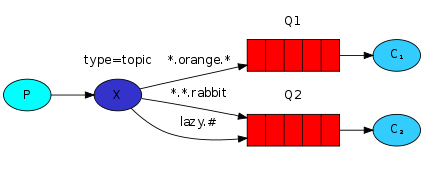
以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,routingKey=”lazy.orange.fox”的消息会路由到Q1,routingKey=”lazy.brown.fox”的消息会路由到Q2,routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey;
To receive all the logs run:
python receive_logs_topic.py "#"
To receive all logs from the facility "kern":
python receive_logs_topic.py "kern.*"
Or if you want to hear only about "critical" logs:
python receive_logs_topic.py "*.critical"
You can create multiple bindings:
python receive_logs_topic.py "kern.*" "*.critical"
And to emit a log with a routing key "kern.critical" type:
python emit_log_topic.py "kern.critical" "A critical kernel error"示例如下
# 组播模式topic服务端
import pika
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='topic_logs', exchange_type='topic')
channel.basic_publish(exchange='topic_logs', routing_key='mysql.caaa', body='info')
print("已经向RabbitMQ转发器发送info组播")
channel.basic_publish(exchange='topic_logs', routing_key='mysql.cbbb', body='error')
print("已经向RabbitMQ转发器发送error组播")
connection.close()# 组播模式topic客户端1
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和direct的类型
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(queue='',exclusive=True) #声明队列,这个队列用来接收广播,因为说了为了保证消息可达,需要队列唯一,一人一队列,使用exclusive=True表示不让其他人加入到这个队列,不指定queue名称rabbitmq会自动生成一个,当这个消费者断开之后会自动删掉,重新生成一个queue
queue_name = result.method.queue # 获得rabbitmq自动生成的队列名
channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key='mysql.caaa')
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue_name, callback, auto_ack=True) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()
# 从RabbitMQ获取的数据是:info# 组播模式topic客户端2
import pika
# 指定用户名和密码
auth = pika.PlainCredentials('cce', 'caichangen')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='172.16.1.1', port=5672, virtual_host='simpleTest', credentials=auth))
# 开启一个rabbitMQ协议通道
channel = connection.channel()
# 通过通道声明exchange和exchange的类型
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(queue='',exclusive=True) #声明队列,这个队列用来接收广播,因为说了为了保证消息可达,需要队列唯一,一人一队列,使用exclusive=True表示不让其他人加入到这个队列,不指定queue名称rabbitmq会自动生成一个,当这个消费者断开之后会自动删掉,重新生成一个queue
queue_name = result.method.queue # 获得rabbitmq自动生成的队列名
channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key='mysql.*')
# ch就是上面的channel实例
def callback(ch, method, properties, body):
print(" 从RabbitMQ获取的数据是:%s" % body.decode('utf-8'))
# 指定消费的回调函数,和接收消息的通道,一收到消息就会调callback函数
channel.basic_consume(queue_name, callback, auto_ack=True) # 这里需要将自动确认消息设定为False
# 开启消息死循环,实际就是一个select监听
channel.start_consuming()
# 从RabbitMQ获取的数据是:info
# 从RabbitMQ获取的数据是:error