简介
Memcached基础简介;
存储系统
任何夸主机或网络调用的机制都可以理解为套接字通信机制,而套接字通信机制上的通信,如果我们是调用对方的服务而这个时候我们通常把他们叫做RPC(远程接口调用),MySQL是一种是一种关系型存储系统,这种系统支持强大的实物能力,支持强大的数据一致性功能等等,但事实上对于有些并发现要求较高的场景当中,它是不适用的主要原因在于其内部的严格显示,会使得在每一次数据改写时都得被检查,例如,有个表中有主键那么,当我们插入一行新的数据的时候MySQL会去对这个主键的每一行进行检查,是否有重复,看上去只是一行简单的插入操作背后所实现的是大量大查询,这也就是为什么关系型数据库性能那么低的原因,约束是一个主要原因。
在很多时候,我们如果认为数据的数据重复是无所谓的或者我们对主键这种要求并不是那么的高,而且对事物方面也没有需求,只要确保数据本身在多次的存取访问时是不会一致的时候我们就可以改变这种模型,我们可以对数据不施加各种约束,这个数据结构非常简单它只需要描述各种键值对,行和行之间没有什么关系,比如可以存储姓名,姓名就是一个键,姓名对应的姓名就是一个值【key/value】,我们可以存储N组这样的数据,只要我们能够确保我们存进来的数据不可能有任何两个键相同时,那我们几可以使用一种非常简单的数据结构来实现一种存储系统。用户给定键我们给它赋予值,我们直接找个空间给他们存下来即可,那么这种存储系统我们通常叫做键值存储系统。无论是什么存储系统我们可以将数据保存在内存或者磁盘中,很显然保存在内存中性能会更好一点,保存在磁盘上数据的持久会更好一点,而我们memcached就是这么一种系统,它仅支持键值存储,和我们MySQL相比较它表中的每一行都可以存储多个元素,但对于我们的memcached来讲一个数据项就是一个键值,因此不能存储复杂的逻辑结构,仅能存储一个简单的流式化数据,我们想存储姓名、年龄、性别在memcached中是很难做到的。所以说我们要存储那些简单的没有逻辑结构的数据,我们使用memcached的KV存储就能解决问题。而KV存储可以是本地的基于文件系统来实现,当然我们可将此功能通过我们的套接字服务远程输出出去让别人可以调用,memcached本质上就是一个键值缓存存储系统,因为它只能放在内存当中,一断电就丢失了。所以不支持持久存储,它也没有提供这种机制将数据存储到磁盘当中,因此不会吃数据持久化,它就以高性能的、简单的向用户提供了一种数据存储系统,它也监听在套接字之上,将自己的存储功能向外部进行输出,任何可以扮演memcached客户端的都可以使用此协议,我们称之为memcached协议,它能缓存所有的可流式化数据,此外memcached自身没有理解可流式化数据。
1. 简单key/value存储:服务器不关心数据本身的意义及结构,只要是可序列化数据即可。存储项由“键、过期时间、可选的标志及数据”四个部分组成;
2. 功能的实现一半依赖于客户端,一半基于服务器端:客户负责发送存储项至服务器端、从服务端获取数据以及无法连接至服务器时采用相应的动作;服务端负责接收、存储数据,并负责数据项的超时过期;
3. 各服务器间彼此无视:不在服务器间进行数据同步;
4. O(1)的执行效率
5. 清理超期数据:默认情况下,Memcached是一个LRU缓存,同时,它按事先预订的时长清理超期数据;但事实上,memcached不会删除任何已缓存数据,只是在其过期之后不再为客户所见;而且,memcached也不会真正按期限清理缓存,而仅是当get命令到达时检查其时长;长清理超期数据;
特点
1、协议简单;
2、基于libevent的事件处理(event并发性高);
3、内置内存存储方式;
4、memcached不互相通信的分布式(无法像M有SQL一样去做主从、主主等存储方式);
memcached的内存分配机制:
memcached是基于内存来存储数据的,所以它有大量的时间需要去做内存分配,一般而言我们要缓存一个10字节的数据,那么我们就需要向内存申请十个字节来存放这段数据,久而久之内存不断的申请回收,回出现内存碎片的。而对我们的memcached为了降低内存碎片的出现,采用了一种比较精巧的内存回收等管理方式。
memcached内存分配因子:
memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
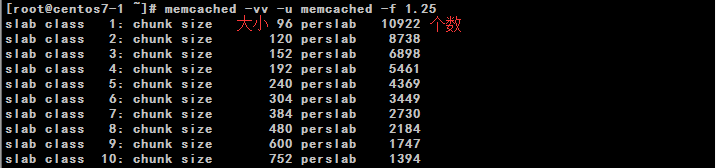
如图

原理
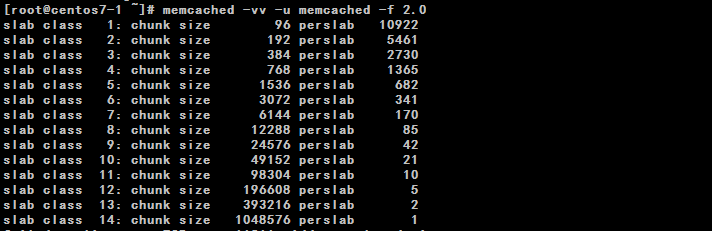
当我们使用memcached的时候默认直接配置64M内存,它就上来直接将这64M内存进行分块,(memcached有个要求,最小的块分为64个字节,最大单个缓存项不可超过1M)它的原理是将这64M内存分为不同区间大小的内存块,通过 -f(增长因子) 参数来实现(默认1.25倍),最小的块是96字节,那么我们可以通过此数计算出下一个块的大小就是120字节,每个相同大小的块分配多个,由此便减少了内存碎片的出现。
图例1
图例2
缓存生命周期
每个键值都有一个生命周期,它有一种最近最少使用的机制来删除不使用的缓存,但是memcached是一种惰性清理的管理逻辑,当缓存过期时,memcached也不会直接将数据清理出去,把它的内存标记为可用当需要存储的时候直接往里面存储覆盖原有数据而不需要删除元数据,当我们需要这段空间的时候才去清理。
不互相通信
由于我们的memcached不支持互相通信的方式,那么假如我们的一个集群系统中有多个memcached存在,当用户第一次申请的数据被缓存到某一个memcached实例中,那么下次我们的客户端如何知道存储在哪一个memcached实例中呢,那么对于这种情况我们可以将用户请求的url做hash计算,这个hash计算的结果当做键,数据当做值,那么用户下次请求的时候可以通过一致性hash算法或者其他算法,调度到这台主机,然后取得结果返回给用户。