22、Kubernetes高级调度方式
高级调度方式
使用示例
实验环境
亲和硬限制
亲和软限制
反亲和硬限制
反亲和软限制
结合使用
污点和容忍度(Taints and Tolerations)
污点的效用
Tolerations匹配Taints
容忍度的评估方式
污点和容忍度的使用
给节点打污点
添加污点
移除污点
添加容忍度
使用
实战示例
Kubernetes内建污点
使用示例
实验环境
亲和硬限制
亲和软限制
反亲和硬限制
反亲和软限制
结合使用
污点和容忍度(Taints and Tolerations)
污点的效用
Tolerations匹配Taints
容忍度的评估方式
污点和容忍度的使用
给节点打污点
添加污点
移除污点
添加容忍度
使用
实战示例
Kubernetes内建污点
高级调度方式
对于Pod资源来讲,在运行过程当中,因为Pod彼此之间的或业务或彼此之间的关联关系,有可能需要将两个在同一个控制器的Pod,根据业务需求将其运行于同一个,或者是不能运行于同一节点上,像这种高级调度控制器记住,称之为Pod间的Affinity或Anti-Affinity,这两种调度关系分别为亲和性及反亲和性两种相反的调度逻辑;
对于Pod亲和性来讲,主要用于描述两个Pod之间能否运行于同一位置,同一位置可能是同一机房,同一节点,同一集群等,因此在定义Pod亲和性时,我们必须有一个机制来人为定义何为同一位置,有一个专门的字段,叫做topologyKey,通过这个Key来界定算不算同一位置,比如我们某一个应用程序,需要运行在Linux系统之上,但是我们的Kubernetes集群内可能有Linux,可能有Ubuntu,也可能够FreeBSD,那我们可以把他们看为三个位置,借助node级别label来进行区别系统,比如我们给Linux系统打上一个os标签值为linux,Ubuntu系统打上os值为ubuntu,FreeBSD打上一个os标签值为freebsd,所以我们就可以使用topologyKey来界定os的值为linux的标签为同一位置;
或者说两个机房,北京一个机房,上海一个机房,此可以看为两个位置,那么如果有时候我们期望我们的Pod运行在同一位置当中的时候,我们就可以使用亲和性来做同一位置限制,如果我们又期望处于冗余的目标,我们也可以让其不在一个位置,一般都应该让他运行在不同的机房中,此时我们就可以使用反亲和性;
如果要使用Pod亲和性来调度,只需要在Pod的spec下面的affinity字段当中使用podAffinity或者使用podAntiAffinity来定义即可,但是Pod的亲和性和反亲和性有一个要求,如果要使用Pod亲和性,假如有三百个节点,每调度一个Pod都需要评估这个Pod和其他Pod是不是在同一个位置,可能会遍历每一个节点查询位置是不是一样的,所以评估过程就被拖慢,因此在较大的规模的集群当中,反而不是特别适合于使用podAffinity,或者不易于使用较细的粒度进行区分同一位置;
podAntiAffinity指的是几个Pod一定不能在同一个位置,那么如果有某几个节点没有标签如何判断这个节点和我当前的目标是不是在同一位置,因此Pod的podAntiAffinity要求集群当中的每一个节点,都必须设置正确的标签,否则没法评估到底是不是反亲和性的,否则反亲和性就无法工作,因此Pod的亲和性调度,还是有着较大局限性的;
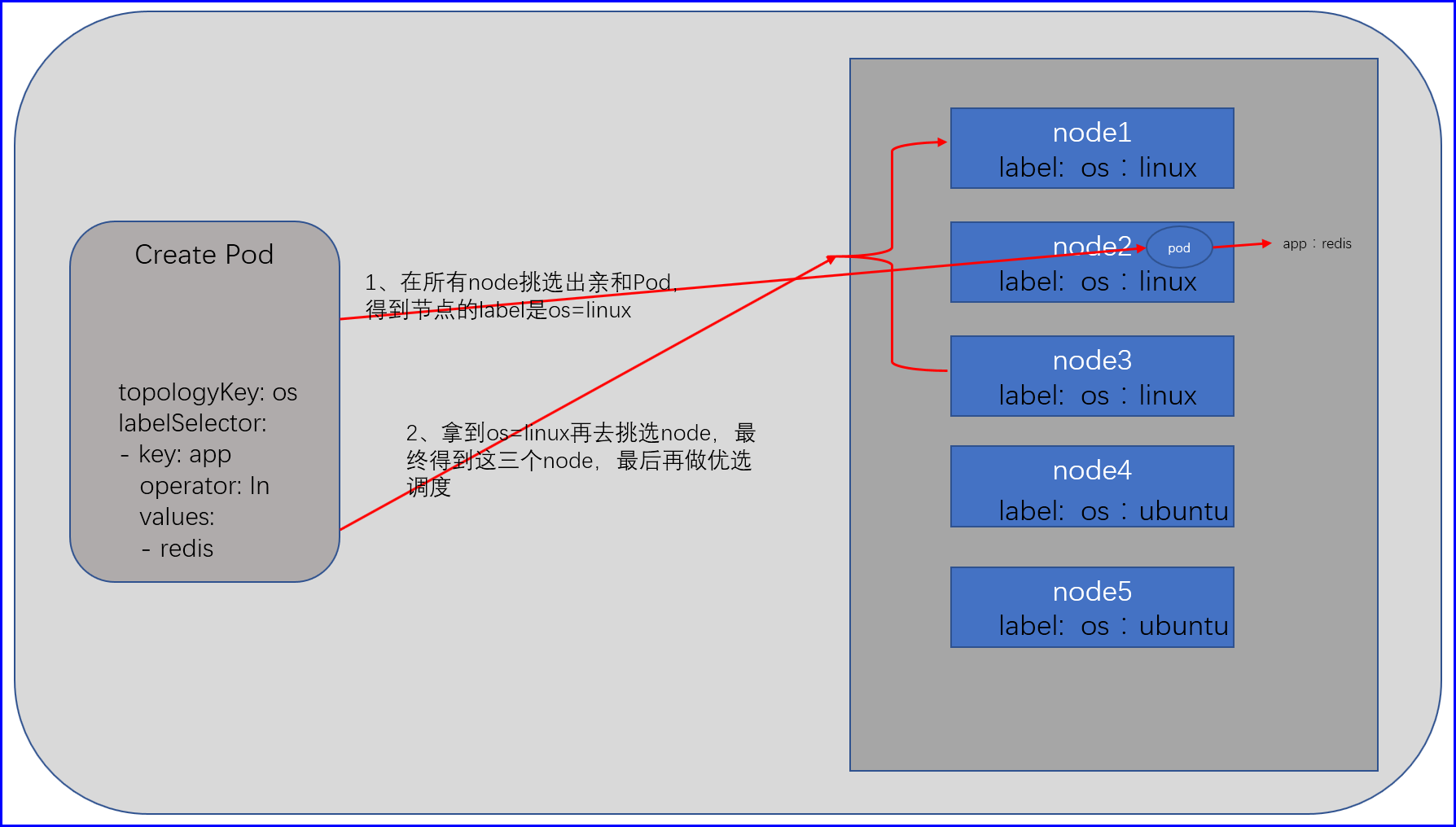
使用示例
spec:
affinity: # 亲和性定义
podAffinity: # 亲和性
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: zone # node标签选择,这里定义利用哪个label的key作为同一位置评判,如果是一个机房的node那么我们应该将其zone值设为一样,因为这里是硬亲和,所以必须运行在能匹配到亲和性的Pod的机房
labelSelector: # pod标签选择,这里表示选择需要和哪个Pod亲和,如果在所有机房内的所有node如果机房1内能匹配到这个Pod,那么就表示该Pod可以运行在机房1的所有节点
matchExpressions:
- key: security
operator: In
values: S1
podAntiAffinity: # 反亲和性
preferredDuringSchedulingIgnoredDuringExecution: # 软亲和
- weight: 100 # 如果匹配该亲和性那么总优选分值减多少
podAffinityTerm:
topologyKey: kubernetes.io/hostname # node标签选择,这里是软反亲和,看这个键,是用来表示node节点名称的,在这个例子表示此Pod,尽量不要security=S2这个Pod的节点上再运行
labelSelector: # pod标签选择,这里表示选择需要和哪个Pod亲和,如果在所有机房内的所有node如果机房1内能匹配到这个Pod,那么就表示该Pod尽量不要运行在机房1的已经运行了一个匹配到如下Pod的节点
matchExpressions:
- key: security
operator: In
values: S2
# 大概意思就是,声明,这个Pod必须在一个已经运行了一个能能匹配到security=S1的Pod的机房运行,这一步已经挑选出了哪几个机房,然后再进行下面的反亲和的软亲和,也就是说假如已经挑选出了3个机房,那么在调度的时候也尽量不要让节点的名称一样,也就是尽量不要在一个节点上再运行一个这样的Pod,这还会从机房中排除一些节点,而后,如果有的节点能被security=S2这个label匹配到也尽量不要调度到这个节点上去,又挑选出了一些节点,余下的进行优选随机
# 先在所有机房查询出有哪几个机房里面的Pod能匹配到labelSelector,意思就是和哪个机房亲和,至于亲和标准为哪个机房能匹配到labelSelector实验环境
亲和硬限制
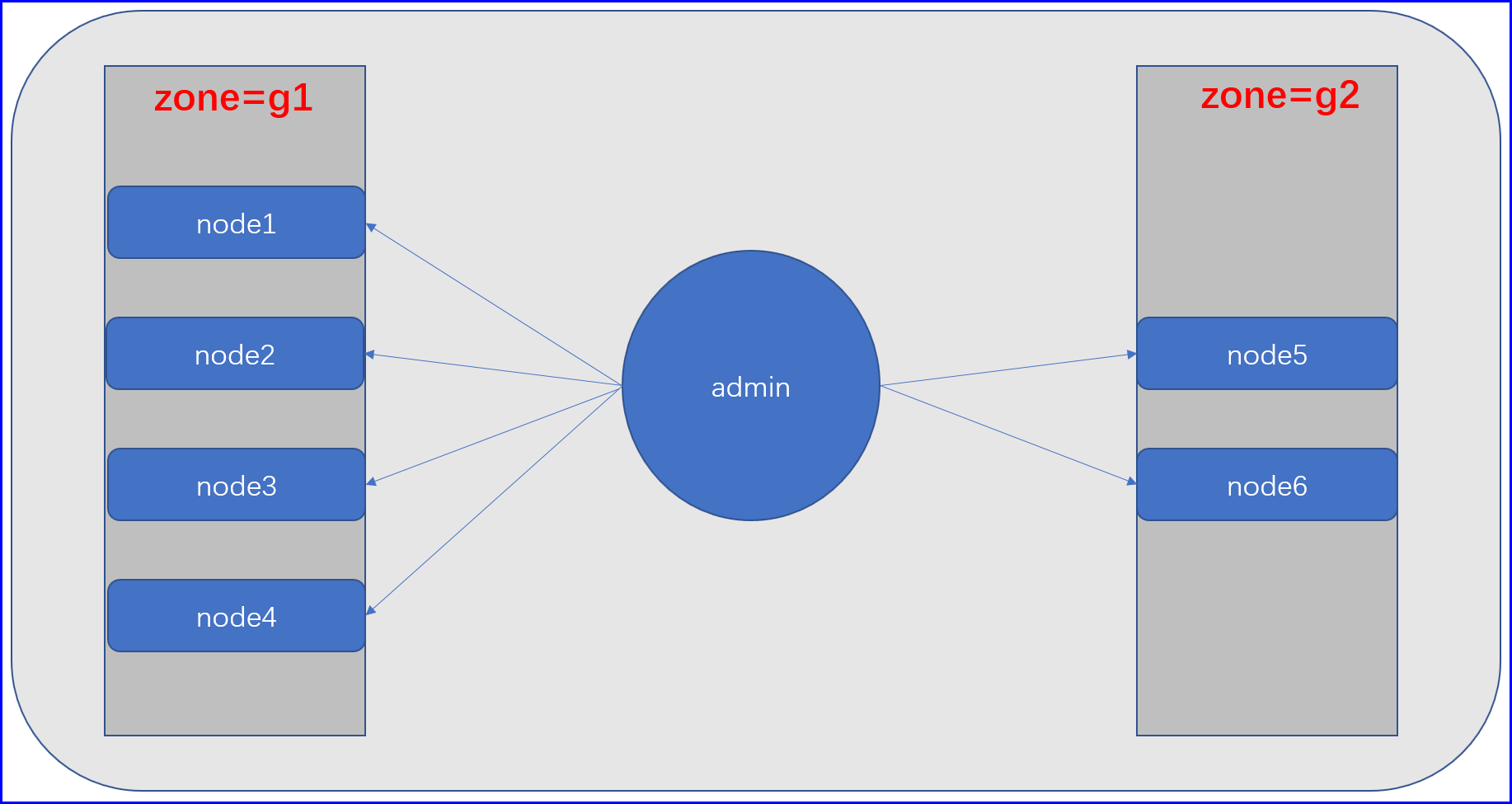
亲和硬限制的流程是,首先需要在各个node里面找到属于一个位置的node,所以我们需要用label区分开来,比如现在有5个node节点,其中两个的属于机房一,那么这三个节点都会有一个zone=g1的label,另外两个属于g2,假设我们在g1机房其中的一个node给node创建了一个app=db的redis的Pod,之后我们在创建应用的时候需要让我们的应用代码放在与redis机房一个机房的node节点上,至于哪一个随意,那么我们就需要在创建的Pod配置清单里面说明,硬亲和app=redis有这个label的Pod,然后在所有节点去寻找这个Pod,如果这个Pod不存在则Pending,如果找到这个Pod之后我们的Scheduler会得到这个这个Pod的zone,假设为g2,然后会继续在所有节点中查询与这个Pod的zone一样的节点,接下来就得到了2个node,接下来就进行其他优选函数的优选调度进行检测;
# 创建一个redis,并且给该Pod打上一个label
[root@node1 ~]# cat redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
labels:
app: db # 打上一个标签
spec:
containers:
- name: redis-db
image: redis:4-alpine
# 得知道该节点运行在node2上
[root@node1 ~]# kubectl get pods -o wide|awk '/^r/{print $1,$7}'
redis node2.cce.com
# 创建一个deployment,并且测试亲和硬限制
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
affinity:
podAffinity: # 定义亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和
- topologyKey: zone # 必须与下面匹配到的Pod在同一个位置,用zone来是否相等来区分是否在同一位置,所以同一位置的node应该是一样的,比如一个机房的所有node上面的zone应该都是一样的
labelSelector: # 匹配Pod,这是关键部分,因为上面的topologyKey需要拿到下面匹配到的这个Pod属于的node的label再进行下一步判断
matchExpressions:
- key: app
operator: In
values:
- db
# 创建了一个deployment之后会发现所属的Pod都处于Pending状态,那是因为,此时我们要与之亲和的Pod虽然已经找到了,但是我们判定同一个位置的label为zone,所以该Pod所属的节点如果没有zone那么调度器就无法确认到底将deployment创建在哪个位置,所以Pending;
[root@node1 ~]# kubectl get pods -o wide|awk '/^[^N]/{print $1,$3,$7}'
redis Running node2.cce.com
web-controller-89d846b5c-mlnx2 Pending <none>
web-controller-89d846b5c-v6mk8 Pending <none>
web-controller-89d846b5c-wv6dn Pending <none>
# 因为相亲和的Pod在node2上,那么我们就在除了node2的其他节点打上标签(机房一的node为g1,机房2的node为g2)
[root@node1 ~]# kubectl label nodes node1.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node3.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node4.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node5.cce.com zone=g2
[root@node1 ~]# kubectl label nodes node6.cce.com zone=g2
# 打完标签之后依然处于Pending状态,因为我们的调度器是需要依据这个亲和Pod的topologyKey来作为判断同一位置的依据的,所以才会Pending
[root@node1 ~]# kubectl get pods -o wide|awk '/^[^N]/{print $1,$3}'
redis Running
web-controller-89d846b5c-mlnx2 Pending
web-controller-89d846b5c-v6mk8 Pending
web-controller-89d846b5c-wv6dn Pending
# 给node2打上标签
[root@node1 ~]# kubectl label nodes node2.cce.com zone=g1
# 可以发现给node2打完标签之后,这个属于deployment的Pod会立马进行调度,并且都调度到与redis在同一个zone的节点
[root@node1 ~]# kubectl get pods -o wide|awk '/^[^N]/{print $1,$3,$7}'
redis Running node2.cce.com
web-controller-89d846b5c-mlnx2 Running node3.cce.com
web-controller-89d846b5c-v6mk8 Running node2.cce.com
web-controller-89d846b5c-wv6dn Running node4.cce.com
# 亲和硬限制测试完成亲和软限制
和上面一样,一个redis一个代码,一般来讲,如果不做任何限制,那么我们的deployment应该是分部在这5个node之上,那么我们现在更加期望我们的deployment控制器下面的Pod能和redis在同一个zone,因为同机房,访问的网络IO更加,当然,这不是硬限制,也可以调度到和redis不再同一个zone的node上;
# 创建一个redis,并且给该Pod打上一个label
[root@node1 ~]# cat redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
labels:
app: db # 打上一个标签
spec:
containers:
- name: redis-db
image: redis:4-alpine
# 得知道该节点运行在node5上
[root@node1 ~]# kubectl get pods -o wide|awk '/^r/{print $1,$7}'
redis node5.cce.com
# 先做个测试,创建一个deployment下面有10个Pod,不附加任何亲和测试,查看是不是分部在五个节点之上
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 10
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
# 经测试,确实是10个Pod分部在5个节点之上
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-86bf65fc79-8ttrc Running node3.cce.com
web-controller-86bf65fc79-92gjl Running node4.cce.com
web-controller-86bf65fc79-fgm5j Running node2.cce.com
web-controller-86bf65fc79-h7j2s Running node4.cce.com
web-controller-86bf65fc79-j6b82 Running node6.cce.com
web-controller-86bf65fc79-jccm8 Running node2.cce.com
web-controller-86bf65fc79-p5dst Running node3.cce.com
web-controller-86bf65fc79-rg84p Running node6.cce.com
web-controller-86bf65fc79-rh9m4 Running node5.cce.com
web-controller-86bf65fc79-wmdw7 Running node5.cce.com
# 现在做亲和软限制,先给各个node打好label
[root@node1 ~]# kubectl label nodes node1.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node3.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node4.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node5.cce.com zone=g2
[root@node1 ~]# kubectl label nodes node6.cce.com zone=g2
# 让我们deployment控制器下面的Pod,尽量跑在node5、node6这两个节点之上,因为他们在同一个机房的
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 5
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 因为优选调度是会计算分值的,所以如果有这样匹配的node,那么就将其分值加100,这样就能达到软亲和的效果
podAffinityTerm:
topologyKey: zone
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- db
# 很明显可以看出来node5、node6这两个节点的Pod居多,软亲和生效
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-5f78d5d8fc-4rg79 Running node6.cce.com
web-controller-5f78d5d8fc-5vcnv Running node2.cce.com
web-controller-5f78d5d8fc-8b2vn Running node5.cce.com
web-controller-5f78d5d8fc-8gtcz Running node5.cce.com
web-controller-5f78d5d8fc-kmbx2 Running node3.cce.com
web-controller-5f78d5d8fc-l2wjd Running node5.cce.com
web-controller-5f78d5d8fc-p6v6b Running node4.cce.com
web-controller-5f78d5d8fc-qkz7d Running node6.cce.com
web-controller-5f78d5d8fc-sjdbf Running node6.cce.com
web-controller-5f78d5d8fc-wqv2t Running node5.cce.com反亲和硬限制
和上面环境一样,一个redis的Pod,一个是代码deployment,现在有这样的一个需求,redis服务器上资源有限,我们不期望redis节点上再运行任何deployment下面的Pod;
# 创建一个redis,并且给该Pod打上一个label
[root@node1 ~]# cat redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
labels:
app: db # 打上一个标签
spec:
containers:
- name: redis-db
image: redis:4-alpine
# 得知道该节点运行在node5上
[root@node1 ~]# kubectl get pods -o wide|awk '/^r/{print $1,$7}'
redis node5.cce.com
# 先做个测试,创建一个deployment下面有10个Pod,查看默认策略是否会分配到我们的redis节点上
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 10
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
# 经测试,redis节点确实有运行
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-86bf65fc79-8ttrc Running node3.cce.com
web-controller-86bf65fc79-92gjl Running node4.cce.com
web-controller-86bf65fc79-fgm5j Running node2.cce.com
web-controller-86bf65fc79-h7j2s Running node4.cce.com
web-controller-86bf65fc79-j6b82 Running node6.cce.com
web-controller-86bf65fc79-jccm8 Running node2.cce.com
web-controller-86bf65fc79-p5dst Running node3.cce.com
web-controller-86bf65fc79-rg84p Running node6.cce.com
web-controller-86bf65fc79-rh9m4 Running node5.cce.com
web-controller-86bf65fc79-wmdw7 Running node5.cce.com # 可以看到已经分配到我们的redis节点上了,这不是我们想要的
# 现在做亲和软限制,先给各个node打好label
[root@node1 ~]# kubectl label nodes node1.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node3.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node4.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node5.cce.com zone=g2
[root@node1 ~]# kubectl label nodes node6.cce.com zone=g2
# 让我们deployment控制器下面的Pod,坚决不让我们的deployment跑在node5上
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 10
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname # 因为hostname可以唯一的,所以我们可以用它来做反亲和,也就是除了运行redis这节点kubernetes.io/hostname之外的所有的kubernetes.io/hostname都可以运行
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- db
# 很明显可以看出来node5节点并没有运行我们deployment下面的Pod,反硬亲和生效
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-5f969678c-52k9m Running node2.cce.com
web-controller-5f969678c-7x6pz Running node4.cce.com
web-controller-5f969678c-8m4xl Running node6.cce.com
web-controller-5f969678c-8pllx Running node6.cce.com
web-controller-5f969678c-c9xkx Running node2.cce.com
web-controller-5f969678c-hdscx Running node4.cce.com
web-controller-5f969678c-hzd58 Running node2.cce.com
web-controller-5f969678c-nmlc2 Running node3.cce.com
web-controller-5f969678c-s9js6 Running node3.cce.com
web-controller-5f969678c-x2tm4 Running node3.cce.com反亲和软限制
和上面的差不多,只不过这次不是坚决不让,而是尽量不让我们deployment下面的Pod运行在node5上;
# 创建一个redis,并且给该Pod打上一个label
[root@node1 ~]# cat redis.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
labels:
app: db # 打上一个标签
spec:
containers:
- name: redis-db
image: redis:4-alpine
# 得知道该节点运行在node5上
[root@node1 ~]# kubectl get pods -o wide|awk '/^r/{print $1,$7}'
redis node5.cce.com
# 先做个测试,创建一个deployment下面有10个Pod,查看默认策略是否会分配到我们的redis节点上
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 10
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
# 经测试,redis节点确实有运行
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-86bf65fc79-8ttrc Running node3.cce.com
web-controller-86bf65fc79-92gjl Running node4.cce.com
web-controller-86bf65fc79-fgm5j Running node2.cce.com
web-controller-86bf65fc79-h7j2s Running node4.cce.com
web-controller-86bf65fc79-j6b82 Running node6.cce.com
web-controller-86bf65fc79-jccm8 Running node2.cce.com
web-controller-86bf65fc79-p5dst Running node3.cce.com
web-controller-86bf65fc79-rg84p Running node6.cce.com
web-controller-86bf65fc79-rh9m4 Running node5.cce.com
web-controller-86bf65fc79-wmdw7 Running node5.cce.com # 可以看到已经分配到我们的redis节点上了,这不是我们想要的
# 现在做亲和软限制,先给各个node打好label
[root@node1 ~]# kubectl label nodes node1.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node3.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node4.cce.com zone=g1
[root@node1 ~]# kubectl label nodes node5.cce.com zone=g2
[root@node1 ~]# kubectl label nodes node6.cce.com zone=g2
# 让我们deployment控制器下面的Pod,尽量不让我们的deployment跑在node5上
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 10
selector:
matchLabels:
app: web
template:
metadata:
name: ikubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
topologyKey: kubernetes.io/hostname # 因为hostname可以唯一的,所以我们可以用它来做反亲和,也就是除了运行redis这节点kubernetes.io/hostname之外的所有的kubernetes.io/hostname都可以运行
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- db
[root@node1 ~]# kubectl apply -f deployment.yaml
# 可以看到node5是节点上只有一个Pod,其他节点最少跑了2个,反亲和软限制生效
[root@node1 ~]# kubectl get pods -o wide|awk '/^w/{print $1,$3,$7}'
web-controller-c55fdb7cf-2b2dh Running node3.cce.com
web-controller-c55fdb7cf-2xzsw Running node2.cce.com
web-controller-c55fdb7cf-5vvj9 Running node2.cce.com
web-controller-c55fdb7cf-8rkd5 Running node4.cce.com
web-controller-c55fdb7cf-bpkcx Running node6.cce.com
web-controller-c55fdb7cf-ftxcf Running node3.cce.com
web-controller-c55fdb7cf-j4fnl Running node2.cce.com
web-controller-c55fdb7cf-q4kwp Running node5.cce.com
web-controller-c55fdb7cf-smrmm Running node6.cce.com
web-controller-c55fdb7cf-zwgzk Running node4.cce.com结合使用
亲和和反亲和可以结合使用,比如说我们希望的我们的deployment与redis在一个zone,但是不期望redis这个node再跑deployment下面的Pod;
污点和容忍度(Taints and Tolerations)
无论是NodeAffinity还是PodAffinity还是PodAntiAffinity都是Pod选择运行在哪个节点上,他们都是基于Pod选节点的,所以无论是哪一个都是我们的节点等待被选择,Taints这种机制使得我们的节点可以反对Pod被调度,或者接纳Pod调度的主控权,从而能够使得节点在必要时可以排斥它不期望运行的Pod,所以Pod可以基于NodeAffinity或者PodAffinity选一个节点的时候,但是这个可以节点也可以不让你选;
与NodeAffinity或者PodAffinity不同的是,它必须要结合Tolerations才能协同工作的,也就是说一旦一个节点打上了污点之后Pod能不能调度到这个节点上要取决于这个Pod上有没有对应污点的容忍度,所以将来要基于污点来调度的话,那就必须要确保在节点上能够有污点,在Pod上有容忍度,否则的话,任何不能容忍这个污点的Pod都无法调度上来,从而使得该节点可以用于运行特定类型的Pod;
污点的效用
污点类似此前在Pod上定义的lables等数据,其实污点也类似于这种概念,它只不过用于我们节点上用来标注节点特性的键值数据,它的每一个效用通常有三部分组成;
key:键,不能超过253个字符;
value:值,最多只能63个字符;
affect: 效用;
NoSchedule:不调度,如果有一个节点有污点,一个Pod有容忍度,如果节点的效用是NoSchedule那么就不会调度上来,对已经调度上来了,由于后续发生改变不再匹配的保持原状;
PreferNoSchedule:尽量不调度,如果有一个节点有污点,一个Pod有容忍度,如果节点的效用是NoSchedule那么就尽量不调度上来,就是说还是会调度,对已经调度上来了,由于后续发生改变不再匹配的保持原状;
NoExecute:不执行,如果有一个节点有污点,一个Pod有容忍度,调度时这个Pod调度上来了,调度上来之后节点的污点变了或者Pod容忍度改变了,使得调度上面来的Pod不能再容忍这个污点,如果是NoExecute,那么会驱离这个Pod,并且还可以定义一个驱离宽限期;
Tolerations匹配Taints
1、key必须相同;
2、value必须相同;
3、effect必须相同;
容忍度的评估方式
operator:操作符;
Equal:key相同value相同effect相同;
Exists:key相同effect相同;
污点和容忍度的使用
给节点打污点
Command: kubectl taint
添加污点
kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ...
移除污点
kubectl taint nodes NAME KEY:TAINT_EFFECT-:移除名为KEY,且配置了执行EFFECT的taint;
kubectl taint nodes NAME KEY-:移除名为KEY的taint;
添加容忍度
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolertionSeconds: 3600
---
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoExecute"
tolertionSeconds: 3600使用
# 查看主节点默认的污点
[root@node1 ~]# kubectl describe nodes |grep ^T.*e$
Taints: node-role.kubernetes.io/master:NoSchedule
# 查看kube-apiserver默认的容忍度
[root@node1 ~]# kubectl describe pod -n kube-system kube-apiserver-node1.cce.com |grep Tolerations
Tolerations: :NoExecute # 没有显示key,表示只要是NoExecute就都容忍实战示例
给节点打上污点,并且给Pod打上容忍度,二者结合;
# 查看node,现在只有一个worker节点,主节点有污点所以不会调度
[root@node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1.cce.com Ready master 44h v1.16.2
node2.cce.com Ready <none> 44h v1.16.2
# 创建一个deployment测试Pod是否会调度到node2,此时我们的Pod没有定义容忍度
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
name: kubernets
labels:
app: web
spec:
containers:
- name: web-container
image: ikubernetes/myapp:v1
ports:
- containerPort: 80
protocol: TCP
name: http
[root@node1 ~]# kubectl apply -f deployment.yaml
[root@node1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-controller-94bd58c95-zkf54 1/1 Running 0 9s 10.244.1.6 node2.cce.com <none> <none>
# 给node2打上一个污点,并且删除原有的deployment,查看Pod是否会Pending
[root@node1 ~]# kubectl taint node node2.cce.com custom_taint=nginx:NoSchedule
[root@node1 ~]# kubectl describe nodes node2.cce.com |grep ^T.*e$
Taints: custom_taint=nginx:NoSchedule
# 可以看到已经进入pending状态
[root@node1 ~]# kubectl apply -f deployment.yaml
deployment.apps/web-controller created
[root@node1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-controller-94bd58c95-g29rj 0/1 Pending 0 4s
# 修改我们的deployment增加容忍度
[root@node1 ~]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-controller
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
name: kubernets
labels:
app: web
spec:
tolerations: # 定义容忍度
- key: custom_taint
operator: Equal
value: nginx
effect: NoSchedule
containers:
- name: web-container
image: ikubernetes/myapp:v1
ports:
- containerPort: 80
protocol: TCP
name: http
[root@node1 ~]# kubectl apply -f deployment.yaml
# 此时我们就可以看到已经调度到了node2
[root@node1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-controller-7494647986-ht47v 1/1 Running 0 11s 10.244.1.13 node2.cce.com <none> <none>Kubernetes内建污点
Kubernetes在1.6之后引入了几个表达节点问题的几个污点,他们由Node Controller根据节点的实际状态在需要时自动添加;
node.kubernetes.io/not-ready:节点未就绪;
node.kubernetes.io/unreachable:节点不可达;
node.kubernetes.io/out-of-disk:磁盘耗尽;
node.kubernetes.io/memory-pressure:内存耗尽;
node.kubernetes.io/disk-pressure:磁盘耗尽;
node.kubernetes.io/network-unavailable:网络不可用;
node.kubernetes.io/unschedulable:不可被调度;
node.kubernetes.io/uninitialized:未被初始化;