19、Kubernetes网络插件体系及Flannel基础
Kubernetes网络
常见网络模型网络解析
Kubernetes网络解析
CNI
flannel支持的后端
Vxlan的DriectRouting模式/Host-gw模式
flannel配置参数
flannel默认配置
测试隧道协议
DirectRouting
Flannel总结
host-gw
模拟实现
Flannel实现
VxLan
Directrouting
常见网络模型网络解析
Kubernetes网络解析
CNI
flannel支持的后端
Vxlan的DriectRouting模式/Host-gw模式
flannel配置参数
flannel默认配置
测试隧道协议
DirectRouting
Flannel总结
host-gw
模拟实现
Flannel实现
VxLan
Directrouting
Kubernetes网络
如果有多个节点,这些节点跨节点进行协作时,一般应用程序所使用的IP地址就是,就是节级的IP,那么只要跨节点通信的应用程序本身能够引用节点IP地址也就能正常通信了,但是现在问题是,如果我们以容器化的方式运行应用程序时,每一个应用程序都应该拥有自己的网络名称空间,那么因此,每一个应用程序都应该拥有自己独立的IP地址,更重要的是,每一个节点之上有可能会运行多个应用,而一个容器化应用与另外一个容器化应用通信时,彼此到底工作于整个集群环境的哪一个节点之上,用户是无法预知的,因为这是一个编排系统所必须具备的能力之一,也就是说一个容器化应用应该运行在哪个节点上,如果我们自己没有强制性的去干扰调度器如何进行调度的话,那么调度器就会根据自己的调度逻辑完成调度,这就会面临一个问题,以Pod为例,Pod和Pod之间通信时,如果一个Pod被创建在节点一上,因为docker时代,每一个容器在创建时,容器所默认使用的网络模型,叫做bridge,其宿主机接口也就是docker0桥,每一个容器也会有自己的虚拟网卡,来实现容器内部的虚拟网络通信;
而docker0桥的网络地址是固定的,那么如果某一个Pod控制,编排了两个Pod,这两个Pod各自编排了一个容器,此时我们剥离Pod,单谈容器,刚好这两个Pod或者两个容器本身分别被调度到了两个节点之上,那么这两个Pod中的容器如果关联到我们的docker0桥上,那么很有可能第一个容器获取到的地址是172.16.0.2,第二个容器在第二个节点之上获取的IP地址还是172.16.0.2,那么这两个容器之间使用的地址就相同了,更何况这两个桥上默认与节点外部的其他端点进行通信时,还需要使用SNAT方式,因为每一个节点本地就是一个局域网,这个局域网在节点外部默认是不能被路由的,因此节点外部流量并不没有办法直接访问这个节点上的容器的,除非我们在节点上面做DNAT,因此出去请求别人,我们需要通过SNAT实现,如果要提供服务还需要通过DNAT实现,这样一来就会带来,巨大的问题,跨节点通信,要通过两次NAT才能完成,客户端先做SNAT,被访问的目的端要通过DNAT暴露出来,那么如果我们有五个Pod彼此之间要通信,那得多少个NAT需要维护,且不说容器自身怎么维护,这些NAT规则在我们容器增时就头疼不已,所以这种网络模型显然在这个所谓的容器编排系统当中不是一个可取的网络模型;
对于Kubernetes来讲,我们无论怎么编排Pod,经过充分测试它的地址是不会冲突的,Kubernetes要求所有的Pod应该有自己的网络Pod Network,另外Kubernetes的设计机制当中,Pod和Pod的通信是不会直接进行的,而是通过一个Service中间层进行通信的,Service也有地址,我们把它称为Service Network也称为Cluster Network,在集群内部Pod和Pod虽然,可以直接通信,但是Pod一般要请求某个服务一般请求的它的Service Network地址,而后由Service Network给他调度并且代理至后端的Pod,其实对于Kubernetes网络,应该是我们的管理员手动维护的,因为节点地址还没有进行编排范畴,那么集群地址是Kubernetes自己指定的,由Kubernetes内部的Service资源,通过把它定义成或者转换成iptables或者ipvs规则来实现的,它并不配置在任何一个网卡上,所以Kubernetes自行就能管理好Cluster Network,但是Pod Network,意思就是每创建一个Pod,如果需要自己的地址的话,没有共享宿主机的网络名称空间,那么就需要从这个Pod Network分配一个地址,更重要的是Kubernetes还要求,各Pod之间,必须能够使用对方的地址进行通信,不能走NAT,这是Kubernetes的要求;
也就是说,如果客户端的Pod想访问某个服务端的Pod,在不考虑Service的情况下,二者之间不能经过任何NAT要能够直接进行通信,这是Kubernetes的要求,因为在Kubernetes内部它要维持这样几种通信。
第一,Pod内的容器间通信,这些通信直接通过lo接口就能做到;
第二,Pod和Pod之间的通信,Kubernetes要求我们的网络必须是一个平面网络,不能经由NAT转发,所以Pod到Pod通信一定是直达的;
第三,Pod与Service之间的通信,而Pod到达Service,任何一个目标地址如果访问某一个Service,而Service在任何节点上一定有iptables或ipvs规则存在,所以在它没有离开本机的之后,就已经被iptables或者ipvs规则捕获并进行调度转换了,因此这个通信是通过这种逻辑实现的;
第四,Pod与外部客户端通信,这种通信可以通过NodePort类型的Service,HostPort类型的Pod或者HostNetwork类型的Pod,把外部的流量引入进来;
常见网络模型网络解析
Kubernetes要求我们的网络必须是一个平面网络,不能经由NAT转发,但是这种逻辑就必须要实现一种工作逻辑,比如在一个节点之上,我们运行多个容器,这些容器的地址有可能的动态指定的,那么夸两个节点之间的容器间通信,如果不经过NAT直接与对方地址通信,那么只有突破传统的私有网络模型来实现,实现逻辑也不复杂,只要让我们Pod网络使用桥接网络即可,每个网桥可以直接通信,地址只要不冲突就OK了,那么就必须有一种地址分配地址确保地址池在每一个节点是不一样的,但是大家分配出来的地址却在同一个网段,很简单,首先我们的Pod网络是10.244.0.0/24,那么我们给第一个节点的地址是10.244.1.0/24,分配池为10.244.1.2-10.244.1.254,第而个节点的地址是10.244.2.0/24,分配池为10.244.2.2-10.244.2.254,那么就不互相冲突了;
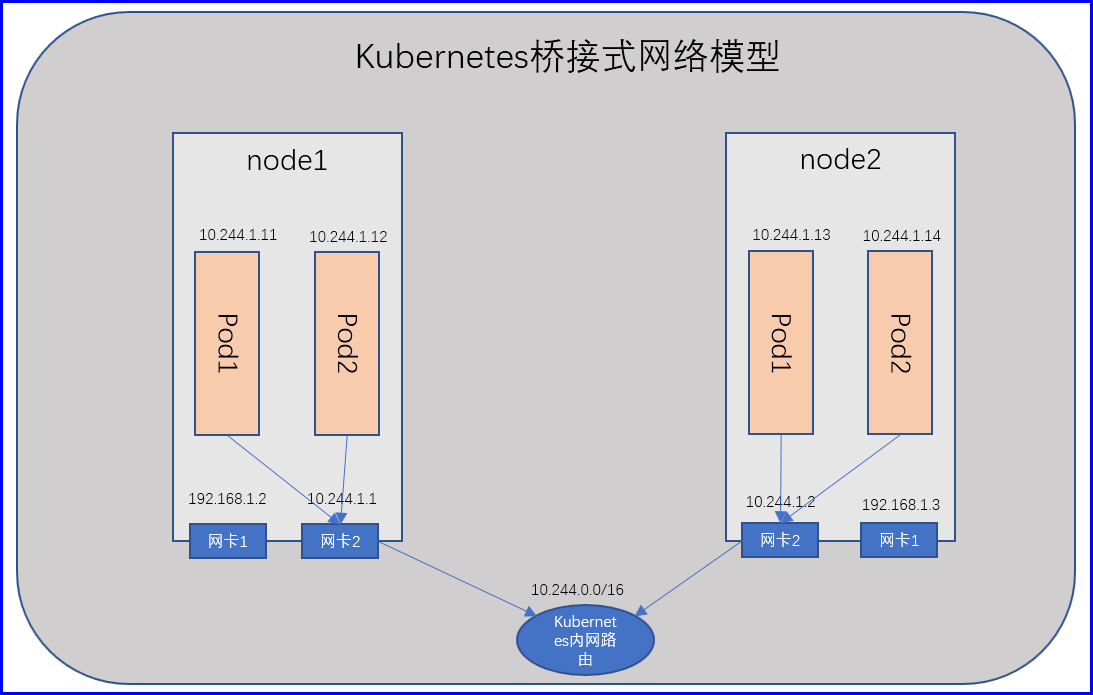
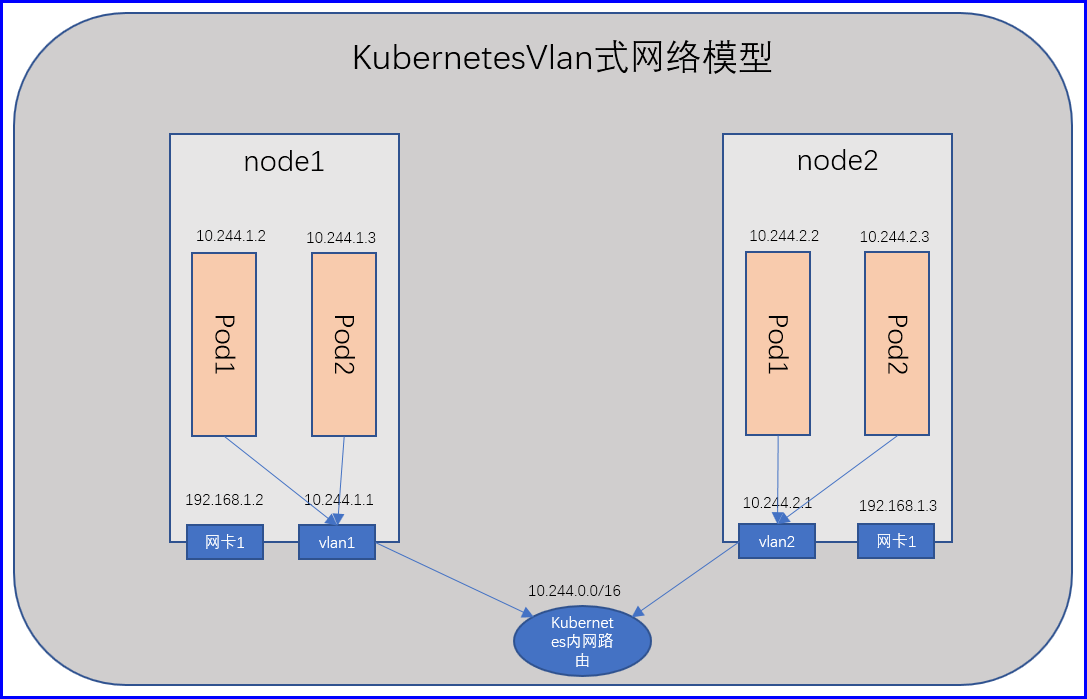
但是这种桥接式网络模型也有问题,假如我们有一千个节点,每个节点跑了100个Pod,这可有十万个Pod,十万个Pod在同一个物理网络,那很容易形成广播风暴,耗尽带宽,那么因此,最好的办法就是把每一个节点之上最好能做成vlan,每一个节点做成一个vlan,同一个节点的Pod互相通信就直接通信了,如果跨节点通信,通过Vlan交换机进行交换就行了,这是一种方案;
但是如果网络很大,变动也很频繁的时候,使用vlan也未必是一种好的解决方案,更何况vlan使用的是不同的网段地址,也虽然可以使用相同网段,但是网络管理起来也很麻烦,所以如果必要的时候完全可以使用BGP网络来实现,构建Kubernetes的网络;
我们依然让Pod连接到节点之上的虚拟网桥上,而不是物理网桥,因此它依然不能与节点之外的Pod通信,但是可以两个节点的物理接口之间打开一个隧道,一旦这个Pod所通信的其他目标Pod,所在的网段是本地网段,那就直接本地通信,如果客户端Pod与自己Pod不在同一网段时,可以通过物理网卡封装一个隧道协议报文,送到另外一个节点的物理网卡上,这个物理网卡解封装之后发现里面还有一层报文,而那层报文刚好是在本地内部来的,因此,就可以与其他Node节点的Pod进行通信了,而在虚拟网络协议中有一种技术叫做VXlan,就是实现这么一个功能,左侧的主机是一个局域网,右侧主机是另外一个局域网,我们可以通过某个控制器,让两个局域网之间的报文能够借助于VXLAN的隧道协议,让他们进行通信, 所以左侧局域网和右侧局域网可以理解为一个大网中的两个小子网而已,也就意味着,从大的角度来看他们还是一个网段;
比如我们VXlan所管理的网络是10.244.0.0/16的B类网,我们再把这个B类网切分成256个C类网,第一个节点是10.244.0.0/24,然后内部Pod再进行dhcp分配,第二个节点是10.244.1.0/24,然后内部Pod再进行dhcp分配,一旦两个节点内部的Pod需要进行通信时,可以通过VXLAN技术将两个节点的地址它的掩码从24位给他,聚合提升为16为,因此两者要进行通信时,第一个节点原地址是10.244.0.2/24就被提升为了10.244.0.2/16,第二个节点原地址是10.244.1.2/24就被提升为了10.244.1.2/16,因此,他们就是同一个网段了,而VXLAN借助于自己的二层隧道,把报文从一个节点送到另外一个节点,但是VXlan怎么知道哪一个节点上拥有哪一个子网呢,如果VXlan自己不能保存这些信息,那么通常要借助于外部的存储系统来保存;
比如一个一个vxlan控制器可以借助于比如想etcd类的kv存储系统,因此我们可以找一个etcd存储,这个vxlan来一个节点就给节点分配一个子网,然后记录到etcd当中,比如记录,要到达10.244.0.0/24(node1虚拟网卡)网段通过192.168.1.2(node1物理网卡),要到达10.244.1.0/24(node2虚拟网卡)网段通过192.168.1.3(node2物理网卡),所以随后node1当中的Pod1(10.244.0.2)要访问node2上面的Pod1(10.244.1.2),先vxlan先查表,然后它查询目的主机是10.244.1.0/24网段,然后根据etcd当中的信息发现要达到10.244.1.0/24这个网段那么首先要将报文送到192.168.1.3,送到192.168.1.3之后发现目标mac地址是自己的,然后拆掉目标mac, 看到里面mac,而里面的mac是192.168.1.3内部的虚拟交换机的,虚拟交换机收到之后,里面的目标IP是Pod1的IP,然后Pod1就收到了;
这种网络我们通常称之为叠加网络,说白了就是,在一个网络上承载了另外一个网络,而叠加网络也是让我们能在一个较大规模的网络当中,实现网络虚拟化的重要基础技术之一,而能实现叠加网络的众多技术当中VXLAN以性能高协议开放著称,所以用的非常非常广泛,甚至于有很多项目都是借助于VXLAN来完成网络虚拟化的;

Kubernetes网络解析
上面提到的叠加网络看似是我们的Kubernetes最优的选择,但是Kubernetes自身并没有实现这个功能,Kubernetes虽然需要为Pod分配网络,但是它觉得各家网络服务厂商,很可能都有自己的私有技术,因此Kubernetes把Pod网络功能基于插件接口提供服务,把它交给第三方网络插件来实现,Kubernetes只是留出了一个插件接口,只要遵循接口规范开发的网络插件,都可以作为Kubernetes集群系统之上的Pod网络组件;
Kubernetes网络插件:https://kubernetes.io/docs/concepts/cluster-administration/networking/
Flanner网络插件:https://github.com/coreos/flannel
对于Kubernetes来讲所支持的网络插件,有很多种,比如ACI、Cilium、CNI-Genie from Huwei等,至少截止到目前来讲,比较主流的有两个一个是Porject Calico,一个是Flannel,Flannel是由于CoreOS所研发的一种轻量级网络实现方案,简单易用,但是它不支持网络策略,Flannel本身在实现方案上是基于VXLAN技术的,也就意味着背后跨级节点通信,是借助于叠加网络来实现的,而Porject Calico默认是使用BGP协议的,大二层网络解决方案,利用一个mac报文承载另一个mac报文,Flannel也支持隧道网络,但是它不是二层,而是三层,ipip,·用一个ip报文承载另外一个ip报文;
所以Porject Calico相对于Flannel来讲,性能更高一些,但是Flannel也支持二层通信,如果我们把它调整为二层,性能也不亚于Porject Calico,但是不得不说的是Porject Calico支持网络策略,这是Porject Calico突出的重要功能之一,但是如果用不到网络策略Flannel还是很不错的一款插件,到目前来讲也是使用者最多的网络解决方案,那Porject Calico也看到了Porject Calico的趋势,所以Porject Calico和Flannel两个项目,就组合起来研发了一款canal,取名Porject Calico的ca和Flannel的al,意思就是说用Flannel的网络功能,用Porject Calico的网络策略功能将二者合二为一;
既能确保用户继续使用Porject Calico的网络策略同时也能使用Flannel的网络功能,所以这是最主流是三种解决方案,不过无论是Porject Calico还是Flannel,他们与Kubernetes的其他网络,比如Cluster Network的功能结合还不是太紧密,操作功能也不能太强大,只不过是它能够完成Pod Network所需要的网络能力,因此还有新兴的项目的出现,叫做kube-router,功能非常强大,既能实现网络也能够借助于lvs/ipvs来管理Service的kube-proxy ,还能够借助于内核转发功能来构建Pod和Pod之间的网络解决方案,而且不使用叠加网络,直接利用内核级的某些特性就能完成大二层网络之间的Pod通信,所以kube-proxy从这个角度来讲也是一个后起之秀,但是一直处于bate这个级别,没有stabe;
CNI
Kubernetes是通过插件接口对接外部网络解决方案的,这个插件接口有两种,如果我们要想部署或使用网络插件的话,早期的接口叫做kubenet,这个是Kubernetes自己的接口,后来Kubernetes被CNCF所接手,因此kubenet慢慢就被废弃了,提供了一种更为开放开源性的接口,CNI(Container Network Interface), 要想对接外部网络解决方案可以使用kubenet这个插件接口,也可以使用CNI这个插件接口,而对于Flannel这两种接口都可以使用,要想使用CNI,我们在每一个节点启动kubelet的时候要给定参数--network-plugin=cni启用这个插件,CNI还需要一个外部的节点级的应用程序来对接,因此还需要使用--cni-conf-dir来指定应用程序地址,默认配置文件的/etc/cni/net.d,程序文件默认在/opt/cni/bin目录,我们在使用kubeadm部署的时候不需要手动管理CNI插件;
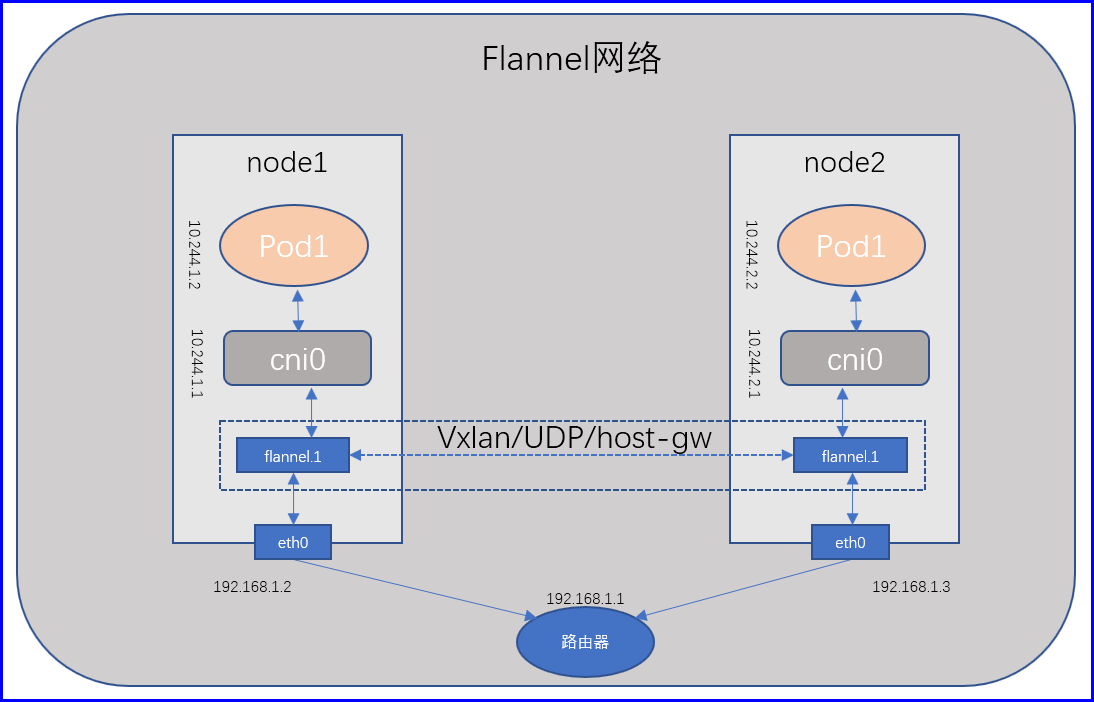
如果我们要使用CNI,使用某个插件,只需要在/etc/cni/net.d创建一个文件,指明插件相关信息,所以我们可以看到每个节点上都可以看到cni0的网络接口,同时还有一个接口flannel.1,这是flannel自己的隧道接口桥(隧道网络有自己专用的封装隧道协议的接口在这里叫做flannel.1),任何Pod在创建以后会自动关联到cni0这个网段上来,因此关联的地址和cni0的地址,同时也是一个24为的掩码 ,如果目标主机IP和cni0地址不在同一个网段,那就不是本地cni0的子网,那么就会通过内核级的路由转发到flannel.1,而后flannel.1给它打上隧道报文,送给另外一个节点,从而完成跨节点的隧道间协议转发,因为默认是vxlan的;
[root@node2 ~]# ifconfig cni0
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::1033:afff:fecd:a9c8 prefixlen 64 scopeid 0x20<link>
ether 12:33:af:cd:a9:c8 txqueuelen 1000 (Ethernet)
RX packets 2439 bytes 178422 (174.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2542 bytes 664404 (648.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@node2 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::3c9b:e5ff:fe3a:77ce prefixlen 64 scopeid 0x20<link>
ether 3e:9b:e5:3a:77:ce txqueuelen 0 (Ethernet)
RX packets 64 bytes 12066 (11.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 34 bytes 5676 (5.5 KiB)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0 每一个Pod为了实现自己的网络名称空间,通常为了和对外通信,它还应该有自己的虚拟网卡,通过描述我们的Flannel应该是这么一个工作逻辑,node1节点上的Pod1需要和node2节点的Pod1通信,那么Pod1所封装的报文先到达cni0,然后送给flannel.1,在flannel.1上通过隧道协议封装,并将24位掩码提升为16位掩码传给node2节点flannel.1并交给node2节点的cni0,从而到达node2节点的Pod1,并且node2节点的Pod1还会认为他们的同一个网段中的协议报文;
但是Flannel是一个守护进程,作为一个Pod运行在我们的物理节点上,而后这个进程可以管控着跨节点的Flannel接口之间的报文究竟是如何被封装的,这种封装封方式我们称之为Flannel Backend,也就是说跨节点是两个Flannel之间,如何去转发报文我们成为Flannel Backend;
Flannel Backend有三种类型,VXLan只是其中一种,另外两种一个是UDP,一个是Host-gw,所谓Vxlan就是一个二层协议隧道,UDP是一个四层UDP协议隧道,这个性能相对于差一点,UDP的出现是因为Flannel刚刚设计的最初,Linux内核有一些发行版内核还比较老,内核级还不支持VXLAN,所以只好退而求其次,使用了UDP协议隧道,所以结果是世人都认为Flannel性能差,那是因为UDP这种模式决定的,如今的Flannel使用VXLAN性能并不差;
还有一种是Host-gw,Host-gw是直接把每一个节点上的容器,通过物理网桥直接接入物理网桥,网桥不是路由,所有Pod直接通信,但是这种方式虽然性能很好,但是有局限性,既然大家都是直接通过mac地址通信的,那也就意味着所有节点必须在同一个物理网络中不能夸路由器,那它的网络设备彼此之间的距离就受限,范围、数量也受限了,如果我们期望能夸路由器甚至必要时能夸机房可以使用VXLAN;
而且VXLAN还支撑一种诡异的方式,VXLAN明明是隧道访问方式,但是VXLAN还可以降级成为和Host-gw一样的方式,也就意味着明明使用的是VXLAN,但事实上使用是二层物理层直接进行通信的,不支持宿主机,也就是节点的IP跨路由器,但如果使用VXLAN的话,可以使用这样的方式,如果大家在同一个网络中就使用Host-gw类型,如果不在同一个网络中就工作为VXLAN模型,这种在VXLAN当中,有一个单独的属性名称,叫做DirectRouing;
通过kubeadm部署的Kubernetes集群,可以通过kubectl get pods -n kube-system -o wide 查看到我们的flannel是直接通过DaemonSet部署到每一个node节点的,而且并且还直接共享了宿主机的网络名称空间,因此它能够通过Pod,直接操作你节点上的网口,所以部署完flannel之后它会自动创建cni0这个接口来,这就是因为它直接共享了宿主机的网络名称空间来操作的,因此flannel即便运行为Pod形式,但是却类似于直接在我们的宿主机上运行了一个系统级守护进程,所以我们将来部署flannel的方式就有两种,直接把flannel使用DaemonSet运行为一个Pod,或者直接在节点上安装相关flannel包,手动配置flannel的文件,使用systemctl来管理flannel,但是对于第二种方式来讲,后面想升级flannel那就比较麻烦了,如果我们使用Pod方式来部署,apply一下就好了;
所以应用程序能运行为Pod,那尽量运行为Pod,毕竟这样这样能很好的发挥Kubernetes带给我们的便利性,所以虽然看上去flannel是一个Pod,其实它是一个系统级的应用,flannel在工作架构当中,也使用了etcd来保存自己已经分配出去的网段和节点IP的映射关系,而Kubernetes自己有一个etcd了,所以flannel就有了两个选择,要么使用自己专用的etcd存储,要么和Kubernetes共同使用一个etcd系统,但是和Kubernetes共享就麻烦了,如果flannel直接就你访问Kubernetes的etcd,那万一flannel有bug将Kubernetes的数据删除了,这后果是很严重的,因此,我们任然允许共享,但是flannel要想Kubernetes的原有etcd服务,是不能直接访问etcd的,而要通过APIServer访问,但是如果把它部署为系统级守护进程,那可能还需要构建一套系统级别etcd专用于flannel;
flannel支持的后端
Vxlan:
vxlan:原生vxlan;
DriectRouting:直接路由,也就是源和目标节点在同一个网络,就是Host-gw的方式,不使用隧道转发,而是直接转发;
Host-gw:而是直接转发;
UDP:就用纯碎的UDP报文转发;
Vxlan的DriectRouting模式/Host-gw模式
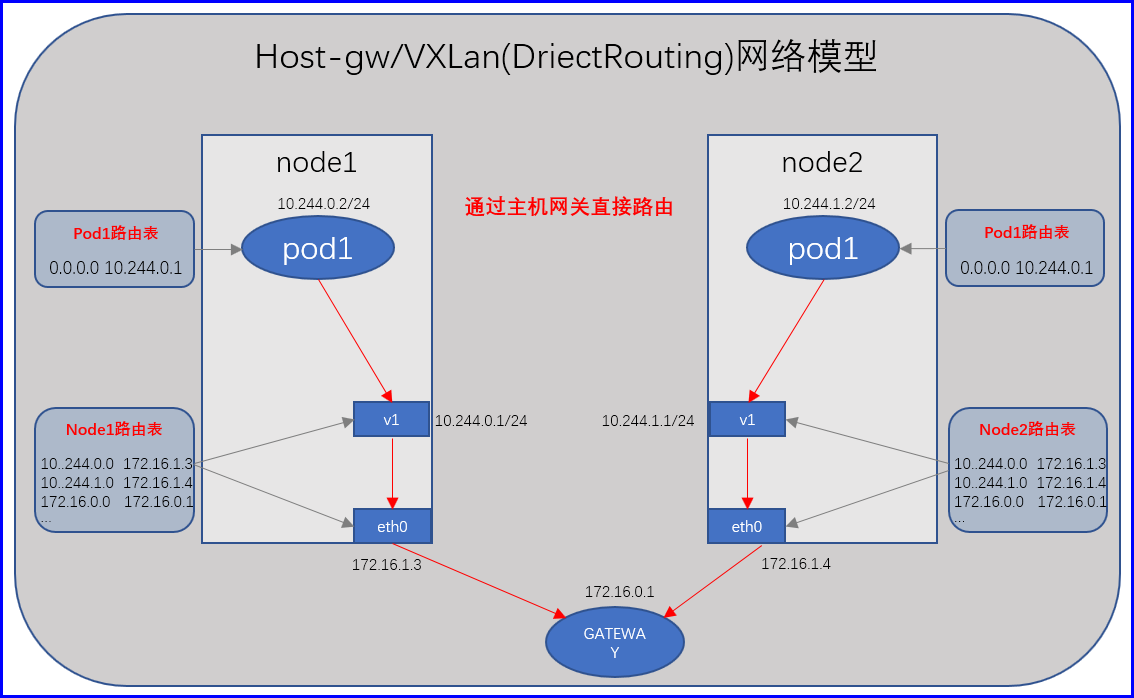
他们都是主机网关模式,假设我们有两个节点,分别是node1和node2,他们各自有自己的专有网段,node1节点上的Pod1的ip地址为10.244.0.2/24,node2节点的Pod1的ip地址为10.244.1.2/24,此时我们可以把node1宿主机作为node1上面的所有Pod网关, 把node2宿主机作为node2上面的所有Pod网关,那这个时候各自Pod和外部通信的时候就可以使用自己的宿主机网关IP地址进行传递;
比如我们在物理机上创建一个虚拟接口v1,用于连接Pod网络,并作为Pod网络的网关,这时候Pod在传输报文的时候不是通过隧道承载传递的,此时这个Pod的ip地址为10.244.0.2/24,而当它需要传递报文的时候目标地址不是本地的,目标地址是10.244.1.2/24,拿它应该把报文传递给网关,网关地址是10.244.0.1/24,所以传递给了本地的专用虚拟接口v1,这个网关看到这个报文之后,然后查询本地的路由表,而后经过发现要到达指定网段需要经过本地的物理网卡eth0(地址为172.16.1.3/24),那么此时到达了我们的物理网卡eth0,物理网卡再查询本地路由表,发现路由表中记录了,要到达指定10.244.1.0/24网络要送给对对端的物理网卡地址为172.16.1.4/24,所这个报文会通过本机的物理网卡,传递给对端的物理网卡,然后对端的物理网卡发现要目的地址是10.244.1.0/24网络,那么就发送给了10.244.1.1这个虚拟网卡,然后也就达到了对端主机(10.244.1.2/24),把主机节点自己当做网关,这种方式性能强多了;
flannel配置参数
Network:flannel使用的CIDR格式的网络地址,用于为Pod配置网络功能,默认为10.244.0.0/16,它可以划分为多个子网比如10.244.0.0/24、10.244.1.0/24...
SubnetLen:把Network切分为子网供各节点使用时,使用多长的掩码进行切分,默认为24;
SubnetMin:指明子网地址段,可分配给节点使用的最小其起始段,比如10.244.1.0/24为起始分配子网;
SubnetMax:指明子网地址段,可分配给节点使用的最大其起始段,比如10.244.100.0/24为结束分配子网;
Backend:指明各Pod之间进行通信使用什么方式来实现Pod和Pod之间的通信,有vxlan(vxlan还有两种,默认的vxlan,还有一种是DriectRouting方式的vxlan),host-gw,udp;
示例:https://github.com/coreos/flannel/blob/master/Documentation/configuration.md
flannel默认配置
[root@node1 ~]# kubectl describe configmaps -n kube-system kube-flannel-cfg
Name: kube-flannel-cfg
Namespace: kube-system
Labels: app=flannel
tier=node
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","data":{"cni-conf.json":"{\n \"name\": \"cbr0\",\n \"cniVersion\": \"0.3.1\",\n \"plugins\": [\n {\n \"type\...
Data
====
cni-conf.json:
----
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json:
----
{
"Network": "10.244.0.0/16", # 默认网段地址
"Backend": {
"Type": "vxlan" # 跨节点容器间通信使用的是vxlan协议,做隧道协议封装
}
}测试隧道协议
# 分别在两个节点部署一个Pod
[root@node1 ~]# kubectl create deployment cce --image=ikubernetes/myapp:v1
deployment.apps/cce created
[root@node1 ~]# kubectl scale --replicas=3 deployment cce
deployment.apps/cce scaled
[root@node1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cce-fcd4c8cff-6ggwz 1/1 Running 0 38s 10.244.1.9 node2.cce.com <none> <none>
cce-fcd4c8cff-9jc92 1/1 Running 0 38s 10.244.2.7 node3.cce.com <none> <none>
cce-fcd4c8cff-bmbdd 1/1 Running 0 55s 10.244.2.6 node3.cce.com <none> <none>
# 使用node2上的Pod去ping node3上的Pod
[root@node1 ~]# kubectl exec -it cce-fcd4c8cff-6ggwz -- sh
/ # ping 10.244.2.7 -c 1
# 使用tcpdump抓包查看数据包
[root@node2 ~]# tcpdump -i eth0 -nn host 192.168.1.106 # 监控eth0接口
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:48:26.988189 IP 192.168.1.106.37887 > 192.168.1.107.8472: OTV, flags [I] (0x08), overlay 0, instance 1 # 外层请求数据包
IP 10.244.1.9 > 10.244.2.7: ICMP echo request, id 5888, seq 364, length 64 # 内层请求数据包
14:48:26.991758 IP 192.168.1.107.51758 > 192.168.1.106.8472: OTV, flags [I] (0x08), overlay 0, instance 1 # 外层响应数据包
IP 10.244.2.7 > 10.244.1.9: ICMP echo reply, id 5888, seq 364, length 64 # 内层响应数据包DirectRouting
修改flannel配置,将DirectRouting模式给打开,这样我们的数据报文就不再经过flannel.1接口进行封装,DirectRouting其原理,它的工作逻辑和Host-gw一样,让各个Pod使用物理网络直接进行通信,但是它依然使用的是10.244这个网段的地址,而不是节点网络地址,而不是节点网络地址,当vxlan工作为DirectRouting方式的时候,他们不能够直接与宿主机的网络进行通信,但是各个Pod之间是可以借助于二层网络,或者说物理网络直接通信的;
是否启用直接路由,当两台宿主机位于同一个网段时,不封装通过路由直接送达,默认false;
# 修改直接查看路由
[root@node2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
0.0.0.0 172.16.1.1 0.0.0.0 UG 101 0 0 eth1
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1 # 隧道封装接口
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 # 节点通信接口
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
172.16.0.0 0.0.0.0 255.255.0.0 U 101 0 0 eth1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
# 修改flannel的configmap
[root@node1 ~]# kubectl edit configmaps -n kube-system kube-flannel-cfg
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"DirectRouting": true
}
}
# 删除所有flannel节点的Pod
[root@node2 ~]# kubectl delete pod -n kube-system -l app=flannel
pod "kube-flannel-ds-amd64-jxxqd" deleted
pod "kube-flannel-ds-amd64-ph58c" deleted
pod "kube-flannel-ds-amd64-qftr5" deleted
# 查看重建加入新配置的flannel节点的路由
[root@node2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
0.0.0.0 172.16.1.1 0.0.0.0 UG 101 0 0 eth1
10.244.0.0 192.168.1.104 255.255.255.0 UG 0 0 0 eth0 # 直接使用eth0进行通信,不再使用cni0,因为这里eth0使用的是192.168.1.0/24网段的地址和上面数的不一样,应该是flannel默认将eth0作为node通信地址了,而不是我的eth1;
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 # 直接使用eth0进行通信,不再使用cni0
10.244.2.0 192.168.1.107 255.255.255.0 UG 0 0 0 eth0 # 直接使用eth0进行通信,不再使用cni0
172.16.0.0 0.0.0.0 255.255.0.0 U 101 0 0 eth1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0Flannel总结
Flannel主要就是用于解决容器的跨主机通信问题,那么它是如何实现跨主机通信的呢,主要实现方式有三种,已经在上层讲解,下面就开始做一个总结,具体如下;
host-gw
其实host-gw现网络通信的逻辑实际就是字面意思,设置主机的IP为网关,也就是直接通过添加路由的方式实现网络通信,这种方式最简单,对于网络IO的消耗也极大的优化了,没有太复杂的逻辑,接下来就分别使用两个主机node03和node04,分别启动两个容器,然后通过添加路由的方式使其实现跨主机通讯;
模拟实现
# 在node03上启动一个http的容器
[root@node03 ~]# docker run -itd --rm --name node03_test_network ikubernetes/myapp:v1
# 命名为node03_test_network,可以看到IP为172.20.1.5
[root@node03 ~]# docker inspect node03_test_network | jq .[].NetworkSettings.Networks.bridge.IPAddress
"172.20.1.5"
# 在node04上启动一个http的容器
[root@node04 ~]# docker run -itd --rm --name node04_test_network ikubernetes/myapp:v1
# 命名为node04_test_network,可以看到IP为172.20.2.6
[root@node04 ~]# docker inspect node04_test_network | jq .[].NetworkSettings.Networks.bridge.IPAddress
"172.20.2.6"
# 默认在node03是无法访问到node04的这个容器的
[root@node03 ~]# curl -m 1 172.20.2.6
curl: (28) Connection timed out after 1001 milliseconds # 连接失败
# 模拟flannel,使用添加路由的方式使得node03可以访问node04的这个容器
[root@node03 ~]# route add -net 172.20.2.0/24 gw 172.16.1.4 dev eth1
# 测试访问
[root@node03 ~]# curl -m 1 172.20.2.6
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> # 可以看到,已经成功访问到了我们node04的容器Flannel实现
上面已经手动的通过添加路由的方式实现了容器之间跨主机通讯,那么此时,因为我们的Flannel也是这样做的,但是host-gw有一个非常重要的前提条件,那就是通信两端主机都必须在同一个二层平面网络中,不能经过NAT、隧道等转换,也就是说他们指向的是一个同一个物理网关,这样才能使用host-gw模型维护静态路由的方式去实现跨节点通信;
事实上在cni网络插件里,效率最高的也就是Flannel的host-gw模型,因为它就是通过内核转发的,它没有任何额外的资源开销,所以到底在生产当中需要什么样的模式,完全取决于当初的规划,是否将所有的宿主机都放在同一个二层网络当中,实现方式如下;
# 可以看到我们现在有两个Pod,分别在node03和node04上
[root@node01 ~]# kubectl get pods -n ingress-web -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-84dd646bcb-mhn94 1/1 Running 3 22h 172.20.1.3 node03.cce.com <none> <none>
web-84dd646bcb-x4qpc 1/1 Running 3 22h 172.20.2.4 node04.cce.com <none> <none>
# 此时,我们的Flannel是没有启动的,查看下路由表,发现并没有路由
[root@node03 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth1
172.16.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1
172.20.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
# 在node03上测试访问,也无法访问
[root@node03 ~]# curl -m 1 172.20.2.4
curl: (28) Connection timed out after 1001 milliseconds
# 启动Flannel,并查看路由表,测试访问
[root@node03 ~]# systemctl start flanneld.service
[root@node03 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth1
172.16.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1
172.20.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
172.20.2.0 172.16.1.4 255.255.255.0 UG 0 0 0 eth1 # 可以看到已成功添加了一天路由表
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
[root@node03 ~]# curl -m 1 172.20.2.4
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> # 成功访问到node04上的PodVxLan
VxLan就是在两台不同的宿主机上,分别实例化出来了两个虚拟网卡设备,这个设备的名字叫做flannel.1,说白了,就是一个虚拟网卡,第一台主机的Pod想要到达第二台主机的Pod,首先会达到我们的flannel.1这个虚拟网卡,这个网卡会进行封包,加上一个头部信息,和尾部信息,然后通过我们的物理网卡传送到对端主机的物理网卡,当进行报文解封装的时候发现实际目的IP并不是自己的,而是第二台主机的Pod,那么要想通过Pod就需要经过flannel.1,所以从而我们数据报文就从宿主机的物理网卡达到了flannel.1,继而达到了我们的Pod;
所以说VxLan模型,效率确实是不够高的,多了一层网络封包的过程;
# 在主节点修改Flannel的网络模型为VxLan
[root@node01 ~]# /usr/local/etcd/bin/etcdctl --endpoints="https://172.16.1.1:2379,https://172.16.1.2:2379,https://172.16.1.3:2379" --key-file=/etc/kubernetes/certs/etcd/etcd-peer-key.pem --cert-file=/etc/kubernetes/certs/etcd/etcd-peer.pem --ca-file=/etc/kubernetes/certs/ca/ca.pem set /coreos.com/network/config '{"Network": "172.20.0.0/16", "Backend": {"Type": "vxlan"}}'
# 在从节点启动Flannel
[root@node03 ~]# systemctl start flanneld.service
# 查看flannel.1虚拟网卡接口
[root@node03 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 172.20.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::8c51:68ff:fee1:a0e2 prefixlen 64 scopeid 0x20<link>
ether 8e:51:68:e1:a0:e2 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0Directrouting
直接路由模型,它是一种混合模型,结合了host-gw和vxlan模型,当flannel发现这两台需要通讯的主机是在同一个二层网络下的时候,flannel就走host-gw,否则就走vxlan,由flannel进行智能判断;
# 在主节点修改Flannel的网络模型为VxLan
[root@node01 ~]# /usr/local/etcd/bin/etcdctl --endpoints="https://172.16.1.1:2379,https://172.16.1.2:2379,https://172.16.1.3:2379" --key-file=/etc/kubernetes/certs/etcd/etcd-peer-key.pem --cert-file=/etc/kubernetes/certs/etcd/etcd-peer.pem --ca-file=/etc/kubernetes/certs/ca/ca.pem set /coreos.com/network/config '{"Network": "172.20.0.0/16", "Backend": {"Type": "vxlan","Directrouting": true}}'
# 在从节点启动Flannel
[root@node03 ~]# systemctl start flanneld.service