TOC
Volumes基础应用
在此前docker应用里面,容器如果跨多节点运行时,容器自身拥有自身的文件系统,一般而言,我们把他们从一个节点迁往另外一个节点,通畅有可能需要关闭,甚至是已有节点上删除已有镜像,并在另外一个节点重新建立同一个容器才能实现,那么这个过程当中将会导致,此前的容器的所有数据被遗留在原有节点之上,而无法迁往另外一个节点,因为我们的docker容器的运行方式,依赖于其底层的镜像构建方式,使得底层的镜像都是只读的,镜像本身是只读的,我们所有的写操作,只能发生在镜像栈最上面所添加的可写层,这个可写层只属于容器自身,而通常这个可写层也被保存在我们对应的容器所在的节点之上,如果删除的容器,容器底层的那些只读部分属于镜像的部分不会变,但是最上面那个可写层将会被删除,那么从而,将镜像启动为容器之后所发生的所有的数据改变,也必然会丢失,所以为了能够脱离容器的生命周期而存储数据,即便是容器停止甚至删除之后,数据依然存在,在docker里面我们应该使用存储卷,docker使用的存储卷有两种类型,第一种是绑定挂在卷,第二种我们称之为docker管理的卷;
但是不论是这两种卷的哪一种,基于docker自己所支持的存储插件来看,默认这个存储卷也之能放在容器所在的节点之上,比如有一个节点,上面运行一个容器,这个容器是堆叠起来的多个镜像层次所构建成的,即便我们使用了存储卷,无论是这两种存储卷的哪一种,默认这个卷的数据还是在当前节点上,所不同的无非是,绑定绑定挂载卷,它的卷的数据,用户可以手动指定,而docker管理的卷,其路径是由docker自行管理和创建的,一般如果我们没有特殊指定删除容器时并不会删除其使用的存储卷,这是在docker容器上使用的存储卷;
到了Kubernetes时代以后,我们的Pod被调度运行的时候,很可能运行于多个数据节点中的任何一个节点之上,假设我们有一个Kubernetes集群,某一次调度一个Pod时,它运行在第一个节点上,我们仍然使用本地存储卷,因此这个卷就是被构建在第一个节点之上,因为各种各样的原因比如节点故障或者说用户显示删除这么一个Pod,那么Kunbernets会自动创建一个替代者,这个替代者在请求创建时,会被调度到集群的任何一个节点上运行,因此,如果下一次重构的Pod运行在第三个节点上,那么第三个节点上是没有这个存储卷的,所以说,它能够期望脱离Pod生命周期,而构建所谓的数据存储,在这种情形当中依然无法实现,但早起单机管理的时候,我们在本地使用这种所谓的传统存储卷似乎没有问题,但一旦跨多节点这种这种解决方式就无法使用该场景了;
所以我们期望在集群分布式管理的Kubernetes模型下,我们的存储卷不但应该脱离容器的生命周期,也需要与节点的生命周期相分离,那么这个时候我们就需要引入通过网络所访问的网络存储空间,比如我们可以使用一个NFS存储系统,让每一个节点都挂载NFS,而后我们无论在把Pod调度到哪一个节点之上,所构建的存储卷,只要NFS不宕机,随后这个Pod宕机了,被重新重构到其他节点,只要重构的这个节点能够在节点级访问到NFS存储,从而就能够让这个Pod访问到NFS存储数据,NFS无而就是一个网络存储系统而已,任何一个网络存储系统,只要确保各节点能够访问到他们,基本都可以为我们的Kubernetes提供脱离节点生命周期的外置的存储系统;
不过,如果NFS这个存储系统宕机了,那么所有存储的数据,也将必然的丢失,因此我们还需要得必须得想办法对外部的这个引用的存储系统做冗余才可以,NFS本身不具有这样的能力,我们只能对NFS借助于其他服务做镜像,或者做数据同步来实现,比如Rsync,但是这种同步方式,性能非常非常低下,因此我们最好能够去构建所谓在存储服务级,自身就拥有冗余能力的存储系统,这个时候我们就会用到所谓的分布式存储,而且自身在数据级别拥有冗余能力的分布式存储系统;
我们的数据冗余通畅可以在两个级别进行,比如NFS,我们可以使用第一种,直接在服务级别进行镜像,构建两个NFS系统,并且数据双相同步,还有一种机制是,我们可以准备很多台主机,构建出一个分布式跨多节点的存储服务来,而后我们不会对每一个节点做冗余,每一个节点都是独立的,但是我们可以在数据管理级别,对每一个数据对象做冗余,比如说我们有一个分布式集群,在分布式集群外面做了一个统一的访问入口,所有对数据的存取操作都通过这么一个统一入口来实现,这个统一入口,负责把用户所提交的存取数据,在当前集群的相关节点,具体是哪些节点,取决于调度法则,比如存一个文件,它会把这个文件在不同的节点上存储多分,到底存储几分这取决于你自己设定的规则,这样会带来的节点的时候,任何时候任何一个节点都不会导致我们的数据对象不可用了,这种冗余,也不至于使得整个集群当中把数据绑定在特有节点上,而是按需灵活分布到不同的节点,这种存储系统还有一个好处,将来存储空间不够用了或IO能力遇到瓶颈的时候,我们可以通过增加节点就能够完成扩展,还支持向外进行扩展的方式来使用,所以这种存储系统应该是一种比较理想的选择,这种分布逻辑,对客户端来讲是透明的,也就是我们的客户端无需关注数据存储在哪一个节点上,究竟需要存储多少个副本,那些通通都委托给这个数据服务来实现,这种也能够为我们的Kubernetes提供所谓脱离节点生命周期的数据存储服务,它比我们的NFS要复杂得多得多,但是他们所提供的存储能力冗余能力扩展能力要强大得多得多;
Pause容器
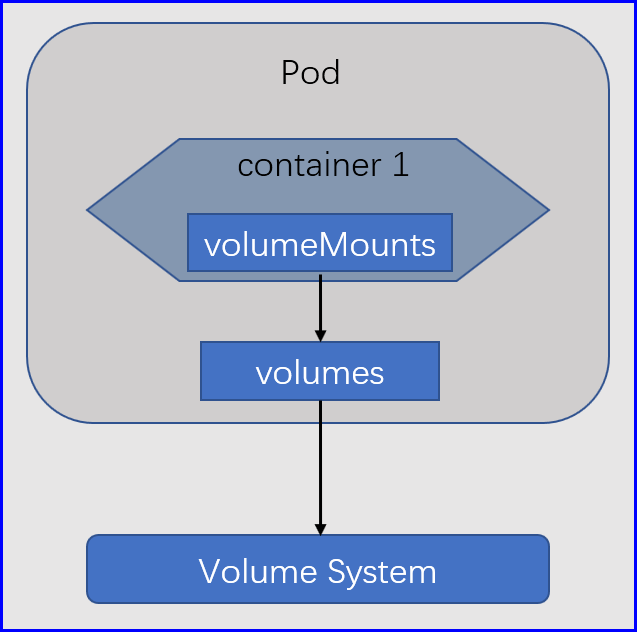
这种存储功能它已然不是,Pod文件系统之上的存储空间了,研习在Docker上面使用的名称,在Kubernetes之上,我们依然把它称之为Volumes存储卷,对于Kubernetes来讲,存储卷不属于容器,而属于Pod,因为Kubernetes最小管理单元是Pod,不过这个概念也不是很精确,因为Pod本身就是抽象出来的,所以在Kubernetes之上应该是这样的一个逻辑,加入我们有一个Pod,在一个Pod当中有可能会运行一到多个容器,其中一个容器的主容器,其他的是辅助容器,但是不管怎么讲, 一个Pod中的多个容器是可以使用同一个存储卷的, 因为存储卷属于Pod,说是Pod,其实Pod有一个底层基础架构容器,在我们自己使用的kubeadm部署的Kubernetes集群之上,这个基础架构容器的镜像名字,通常叫做pause,它在每一个节点上都有,它主要是为我们的每一个Pod提供一个底层的基础支撑设备的,然后我们运行的每一个Pod,其内部都会有一个pause容器存在,对我们而言,我们不用关心它;
容器借助于内核中的六个网络名称空间提供服务,其他pause就是提供了一个基础的容器,剩余加入这个Pod的容器,都共享底层pause的网络名称、IPC以及UTS,同一个Pod内的所有容器,不但能通过lo通信,而且还共享同一个主机名,其实除此之外还有一个功能,如果我们给这个Pod添加一个了一个存储卷,其实这个存储卷是属于Pause的,每一个加入这个Pause的容器,是可以去复制,Pause这个容器的存储卷的,类似docker的--from-volume的功能,对于Pod也一样的,我们加入到Pod的每一个容器,都可以指明,这个容器需要复制Pause容器的存储卷就OK了,谁复制谁就能使用这个Pause种已添加进行来的存储卷,但它和docker所不同的是,Kubernetes的Pod里面的容器要想使用存储卷,我们得自己明确的去挂载这个存储卷到本地的某个目录下,它才能被使用;
如果我们期望在Pause使用存储卷,而这个存储卷有时候可能属于NFS,有时候可能属于ceph,有时候可能属于samba,有时候也可能是本地的,这不同的存储设备所提供的访问方式是各不一样的,因此,这里就需要两个非常重要的步骤,第一,以NFS为例,这个Pod所在节点不能驱动,通过NFS协议连接至NFS存储上,那么运行在这个节点的Pod也势必不能访问NFS之上的存储空间,所以需要确保每一个节点自己能够适配到目标存储系统上,为什么要这样讲,因为每一个容器都是共享这个节点底层的内核的,而驱动是属于内核的功能,所以要确保节点的内核先能适配外部的存储系统;
第二,我们的节点内核可能会适配N种存储系统,假如我们的我们的Kubernetes集群之外部署了一个samba和nfs甚至还有一个ceph,那么我们启动一个Pod时,这个Pod有可能会使用NFS,甚至也可能使用samba存储,所以从这个角度来讲,Pause在接入这个存储卷的时候,还要明确指明,它自己要连接至节点级,已经关联到的哪一种类型存储设备上,而不同类型的存储设备,通过这个底层的Pause接入的方式也不一样,必须得明确定义到底使用哪一种,因为不同的存储设备连接方式不一样,所以这就意味这 pause在关联存储卷时,中间必须要以指定存储设备的访问接口相匹配,说白了,真正去驱动并调用这个服务的客户端不是你的节点的内核,内核只是负责把他们二者之间桥接起来而已,而真正去驱动它的,必须要去成为这个存储服务的客户端才可以;
CSI (Container Storage Interface)
就是Pause要连接到NFS,必须要在连接的时候指明,文件系统类型,NFS访问地址,和对方导出来的文件系统路径,这样一来就麻烦了,目前来讲,我们基于可用的存储类型,是很多的,那为了尽可能支持不同的存储设备,我们就不得不为Kubernetes中的Pod适配每一种存储系统内置驱动客户端,这样一来,我们的整个系统就会变得庞大无比,因此为了避免这种情形,甚至于在必要的情况下,我们允许用户自定义存储,Kubernetes为了使得这种功能更加灵活,Kubernetes还提供了一种特殊的类型叫做CSI,CSI是Kubernetes的一个插件接口,叫做容器存储接口,利用CSI用户可以方便开发自己的存储驱动插件,可以自定义使用任何类型的存储插件,为了降低用户使用的Kubernetes的复杂度,Kubernetes内置了很多标准类型,只有标准类型满足不了我们的需要时,我们才有必要去使用CSI扩展
所以说有两个关键点,第一节点需要适配的存储设备,要内核驱动支持,第二从起自身也需要扮演成为这个存储系统的客户端,为了能够驱动这个客户端,它必须内置一些插件链接不同的存储系统,而这个插件其实就是存储驱动;
Kubernetes支持的存储驱动kubectl explain pod.spec.volumes
Kubernetes支持的存储驱动分类
云存储:awsEastocBlockStore、azureDisk、azureFile、gcePersistentDisk、vshpere Volume
分布式存储:cephfs、glusterfs、rbd
网络存储:nfs、iscsi、fc
临时存储:emptyDir、gitRpo(deprecated)
本地存储:hostPath、local
特殊存储:configMap、secret、downwardAPI
自定义存储:CSI
持久卷申请:persistentVolumeClaim
...
hostPath
hostPath直接关联节点指定的文件或者目录;
# 在node2上创建数据
[root@node2 ~]# mkdir -p /data/kubernetes/volumes/index
[root@node2 ~]# echo "node2.cce.com" > /data/kubernetes/volumes/index/index.html
# 在node3上创建数据
[root@node3 ~]# mkdir -p /data/kubernetes/volumes/index
[root@node3 ~]# echo "node3.cce.com" > /data/kubernetes/volumes/index/index.html
# 编写自主式Pod
[root@node1 ~]# cat volumes.yaml
apiVersion: v1
kind: Namespace
metadata:
name: vol
---
apiVersion: v1
kind: Pod
metadata:
name: vol-test
namespace: vol
spec:
hostNetwork: true
restartPolicy: Always
containers:
- name: vol-pod
image: busybox:latest
command:
- /bin/httpd
- -f
- -h
- /data
volumeMounts:
- name: code # 对应的数据卷名称
mountPath: /data # 挂载到Pod指定的路径
volumes: # 在pause容器里面定义一个volumes,此时不会挂载到其他容器,需要显示指定
- name: code
hostPath:
path: /data/kubernetes/volumes/index # 宿主机目录
type: Directory # 类型为Directory文件必须存在,不存在则抛出错误
# 查看自主式Pod的访问入口
[root@node1 ~]# kubectl get pods -n vol -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol-test 1/1 Running 0 20s 172.16.1.3 node2.cce.com <none> <none>
# 测试访问
[root@node1 ~]# curl 172.16.1.3
node2.cce.com
emptyDir
键名之意,空目录,只要Pod一删除,数据就没了,它大多数场景都是用在缓存的情况下,就比如我们在这个Pod中的容器可能需要用到缓存的功能,比如Nginx,nginx的temp目录可能会存储一些临时文件,这样的情况,我们就可以使用emptyDir来做,让缓存存储在指定的存储文件系统之上,更好用的是emptyDir还支持直接将数据存储在内存中,直接在节点的内存当中切割一段空间出来,把这个空间模拟成一个硬盘,然后把它当缓存用,速度更快;
还有一个场景,我们当前这个Pod没有文件存储的需求,但是Pod内部有两个容器,这两个容器之间需要共享一些数据,那这个时候我们就可以使用emptyDir这个空间,让第一个容器在里面读写,第二个容器也可用读写,这就实现的共享数据,或者说我们的php-fpm有一个sock文件,当构建lnmp的时候,我们可以直接将这个php-fpm的sock文件放在emptyDir里面。然后供nginx使用unix://emptydir_volumes/data/php-fpm.sock;
# 配置基于emptyDir的存储卷
[root@node2 ~]# cat emptydir.yaml
apiVersion: v1
kind: Namespace
metadata:
name: vol
---
apiVersion: v1
kind: Pod
metadata:
name: vol-test
namespace: vol
spec:
hostNetwork: true
restartPolicy: Always
containers:
- name: vol-pod # 该将插入的数据使用http的方式暴露
image: busybox:latest
command:
- /bin/httpd
- -f
- -h
- /data
volumeMounts: # 挂载卷
- name: tempvolumes
mountPath: /data
- name: vol-while # 该容器循环插入
image: busybox:latest
command: ["/bin/sh","-c"]
args:
- while true; do echo $(date) > /html/index.html;sleep 1; done
volumeMounts: # 挂载卷
- name: tempvolumes
mountPath: /html
volumes:
- name: tempvolumes
emptyDir: {} # emptyDir是一个对象,所以如果不想指定留空的话,就可以使用{};
# 查看跑起来的容器
[root@node2 ~]# kubectl get pods -n vol -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol-test 2/2 Running 0 76s 172.16.1.4 node3.cce.com <none> <none>
# 第一次查看结果
[root@node2 ~]# curl 172.16.1.4
Tue Nov 26 15:14:01 UTC 2019
# 第二次查看结果,可以看到时间在变动,也就说明index.html文件在变动
[root@node2 ~]# curl 172.16.1.4
Tue Nov 26 15:14:03 UTC 2019
nfs
在节点级实现数据持久化,脱离节点生命周期的存储,不论Pod是否会被重建,数据都不会丢失,再次重建容器会直接把数据加载进来;
# 在每一个节点安装nfs
[root@node1 ~]# yum install -y nfs-utils
[root@node2 ~]# yum install -y nfs-utils
[root@node3 ~]# yum install -y nfs-utils
# 设定访问权限
[root@node1 ~]# cat /etc/exports
/vols/v1 172.16.0.0/16(rw)
[root@node1 ~]# systemctl start nfs
# 创建对应目录
[root@node1 ~]# mkdir -p /vols/v{1,2,3,4,5}
[root@node1 ~]# echo 1 > /vols/v1/readme.md
# 在节点级手动测试是否能够成功挂载
[root@node2 ~]# mount -t nfs 172.16.1.2:/vols/v1 /cce
[root@node1 ~]# cat nfs.yaml
apiVersion: v1
kind: Namespace
metadata:
name: vol
---
apiVersion: v1
kind: Pod
metadata:
name: vol-test
namespace: vol
spec:
hostNetwork: true
restartPolicy: Always
containers:
- name: vol-pod
image: busybox:latest
command:
- /bin/httpd
- -f
- -h
- /data
volumeMounts:
- name: nfssystem
mountPath: /data
volumes:
- name: nfssystem
nfs:
path: /vols/v1
server: 172.16.1.2
# 查看pod所分配的节点
[root@node1 ~]# kubectl get pods -n vol -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vol-test 1/1 Running 0 97s 172.16.1.4 node3.cce.com <none> <none>
# 第一次请求
[root@node1 ~]# curl 172.16.1.4/readme.md
1
# 变更NFS文件数据
[root@node1 ~]# echo 2 > /vols/v1/readme.md
# 再次请求
[root@node1 ~]# curl 172.16.1.4/readme.md
2