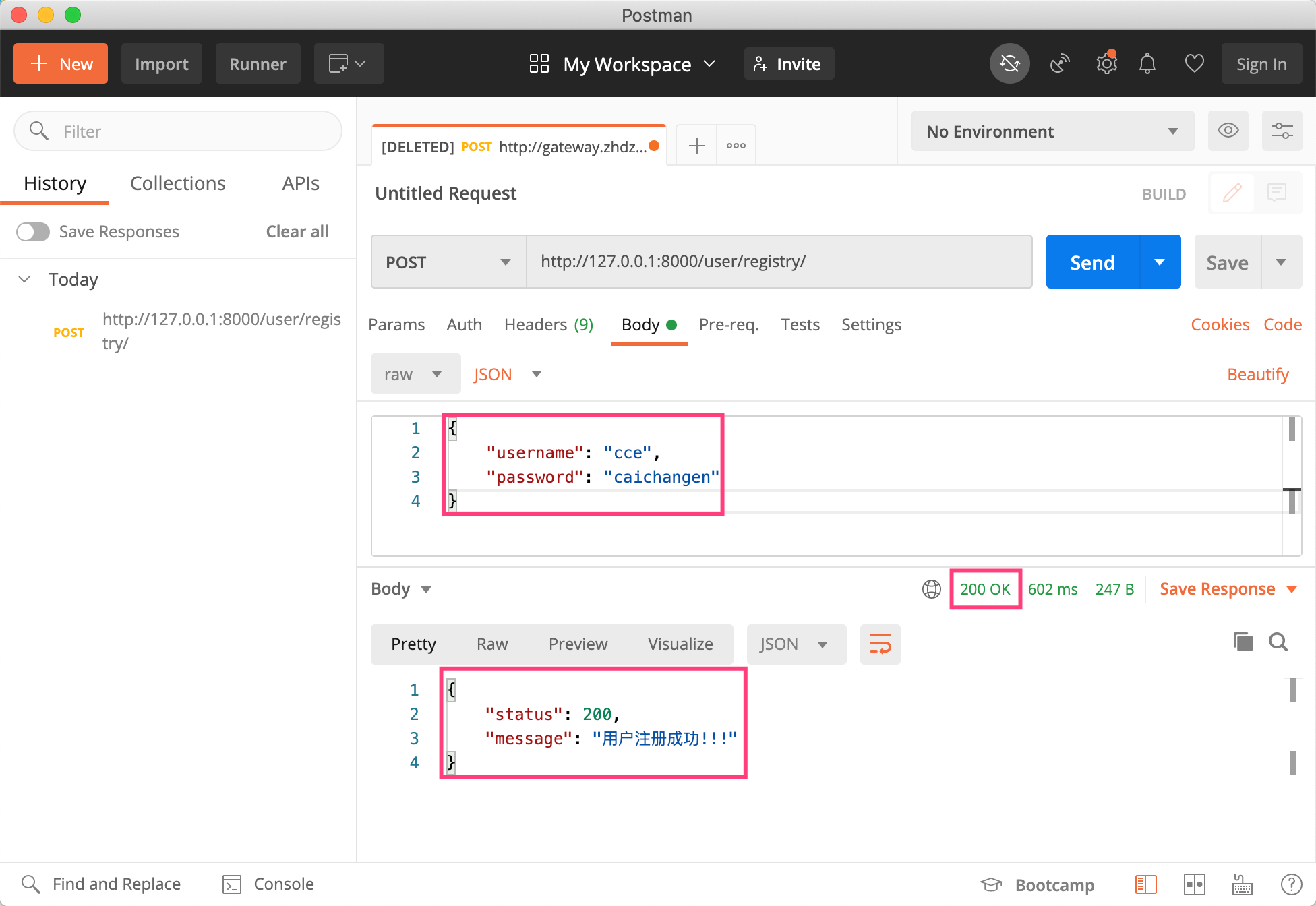
9f9eb502d6ab521a1db9f3c909650a49_7745811.png 发表于: 2023年1月30日 2023年1月30日 实际链接 1952 × 1344 文章导航 发表于9f9eb502d6ab521a1db9f3c909650a49_7745811.png cce 142站点RSS订阅