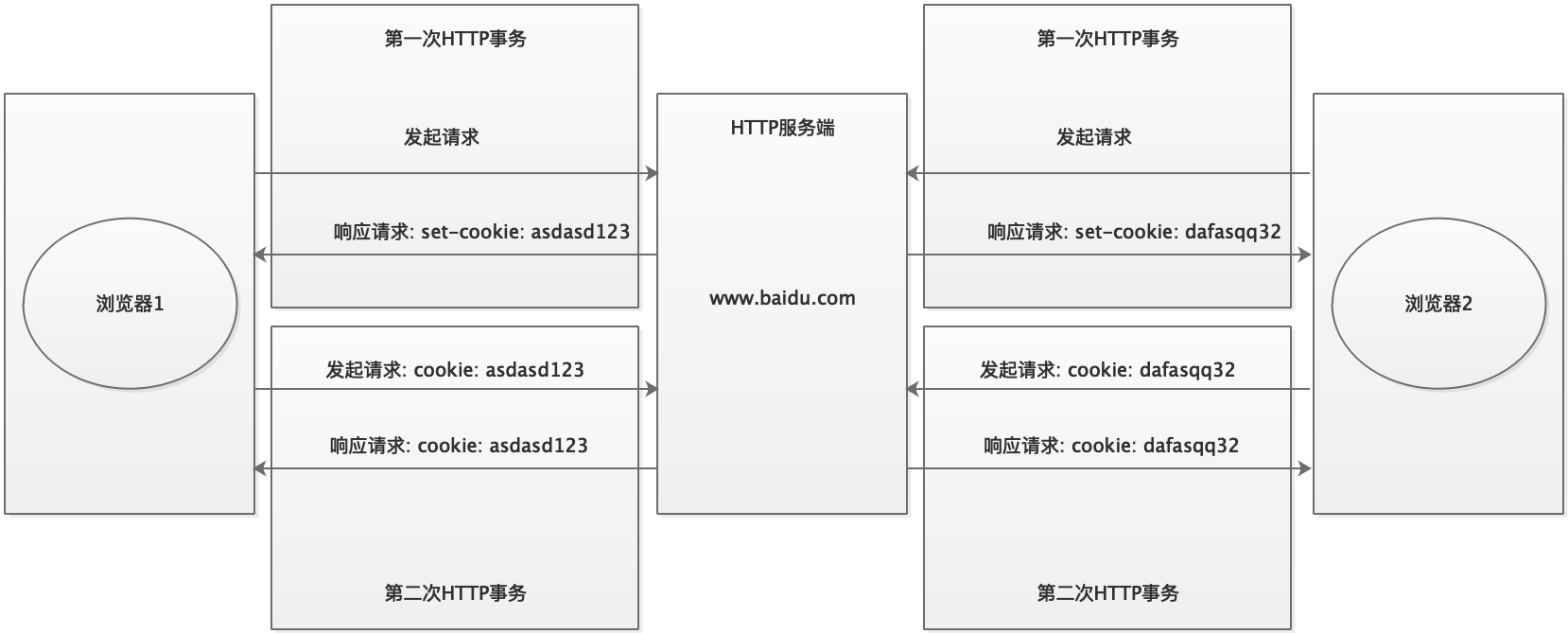
f21736837e4f679dbb581e3c359b75f4_587ca3f8-ba74-45e6-8f77-adcdd9a40245.jpg 发表于: 2023年1月30日 2023年1月30日 实际链接 1658 × 670 文章导航 发表于1、HTTP协议简介 cce 142站点RSS订阅