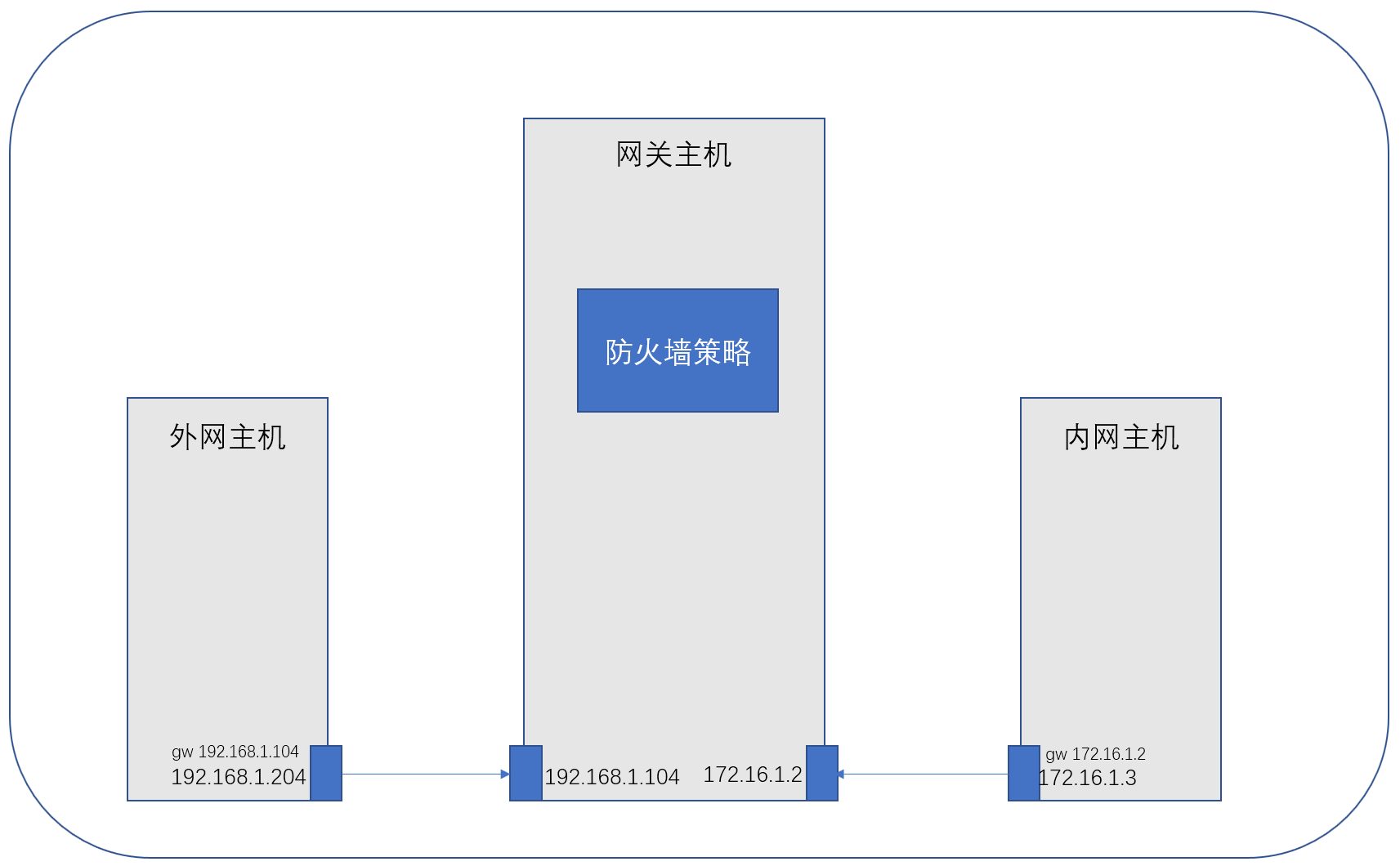
467d626e2a0a9fd07cc32abca9fc100a_5ae8aea5-7fe9-43fd-8b32-ee316073960f.png 发表于: 2023年1月30日 2023年1月30日 实际链接 1713 × 1060 文章导航 发表于3、Iptables网络防火墙 cce 142站点RSS订阅